基于LSTM模型的股票预测(keras实现)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、数据获取
- 二、数据预处理
- 三、训练数据和测试数据处理
- 四、LSTM模型建立
- 五、跑模型
- 六、可视化
-
- 结果
- 总结
前言
这大概就是我第一次写博客hhh,大学摆烂好久,一直想开始记录一下自己的学习,只可惜想的这个动作持续了太久
嚣张一点,反正也没人看
一、数据获取
数据获取用的是tushare,不得不说tushare是一个简洁且方便的平台,获得的数据直接就是DataFrame格式,真是非常的耐撕啊。
tushare id:492845
下边贴个栗子:
import tushare as ts
import pandas as pd
ts.set_token('你的token')
# 我获取的是前复权的数据,如果不需要复权可以调用ts.daily()
train_data = ts.pro_bar(ts_code = '600519.SH',adj = 'qfq', start_date = '20000101', end_date = '20211231')
train_data.to_csv('train—_data.csv')
更加详细具体的内容可以看tushare官网,具体接口(公司信息、日线、周线等)和获取方法写的更详细,我就不赘述了。
值得一提的是官网上也有新冠疫情数据的相关接口,也是全免费。
二、数据预处理
这部分还是蛮简单的,主要是因为tushare的股票数据质量很高,没有空缺或者缺失的数据。
rain_data = pd.read_csv("train_data.csv", index_col=['trade_date'] )
test_data = pd.read_csv("test_data.csv", index_col=['trade_date'] )
# 因为tushare获取的日期是从最新开始获取,所以在进行预测前要reverse
train_data, test_data = train_data[::-1], test_data[::-1]
# 原始数据的维度只需要作为输入【开盘价,最高价,最低价,涨跌幅,成交量】
# 因为我只想要得到后一天收盘价的预测结果,所以预测的指导向量是【收盘价】
train_data = train_data[[ 'open', 'high', 'low' , 'pct_chg', 'vol', 'close']]
test_data = test_data[[ 'open', 'high', 'low' , 'pct_chg', 'vol', 'close']]
train_data.index.name = 'date'
test_data.index.name = 'date'
三、训练数据和测试数据处理
这里输入的数据X_train有三个维度【【开盘价,最高价,最低价,涨跌幅,成交量】】,【时序】【步长】
举个栗子可能会说明的比较清楚:
我要用2020-01-01 ~ 2020-02-01的数据作为输入,前10(步长)天预测第11天的收盘价
那么X_train的shape应该就是【5】【10】【股票在1月开盘的天数】
Y_train 的shape是【股票在1月开盘的天数】【1】
关于数据归一化,调用的是sklearn.MinMaxScaler,fit_transform()归一化,inverse_transform()反归一化还原。至于为什么要归一化呢,因为股价、成交量、涨幅比的量纲差距比较大
def train_data(time_step, sx, sy):
train_data = pd.read_csv('trainData.csv')
# 数据归一化
# sc = MinMaxScaler(feature_range=(0,1))
X_train = train_data[['open', 'high', 'low' , 'pct_chg', 'vol']]
Y_train = train_data[['close']]
X_train = sx.fit_transform(X_train)
Y_train = sy.fit_transform(Y_train)
x_train, y_train = [], []
for i in range(time_step, train_data.shape[0]):
x_train.append(X_train[i-time_step:i, :])
y_train.append(Y_train[i])
x_train, y_train = np.array(x_train), np.array(y_train)
x_train = np.reshape(x_train, (x_train.shape[0], x_train.shape[1], 5))
return x_train, y_train, sx, sy
def test_data(time_step, sxx, syy):
train_data = pd.read_csv('trainData.csv')
test_data = pd.read_csv('testData.csv')
all_data = pd.concat((train_data, test_data), axis = 0)
X_all = all_data[['open', 'high', 'low' , 'pct_chg', 'vol']]
Y_all = all_data[['close']]
x_test, y_test = [], []
# print(len(all_data), len(test_data), time_step)
X_all = X_all[len(all_data) - len(test_data) - time_step:]
Y_all = Y_all[len(all_data) - len(test_data) - time_step:]
X_all = sxx.fit_transform(X_all)
Y_all = syy.fit_transform(Y_all)
for i in range(time_step, test_data.shape[0]):
x_test.append(X_all[i-time_step:i, :])
y_test.append(Y_all[i])
x_test, y_test = np.array(x_test), np.array(y_test)
x_test = np.reshape(x_test, (x_test.shape[0], x_test.shape[1], 5))
return x_test, y_test, sxx, syy
四、LSTM模型建立
def stock_predict(x_train, y_train, _epochs, _steps_per_epoch):
x_train = tf.convert_to_tensor(x_train)
y_train = tf.convert_to_tensor(y_train)
print(x_train.shape)
regressor = Sequential()
regressor.add(LSTM(units = 50, return_sequences = False, input_shape = (x_train.shape[1], x_train.shape[2])))
regressor.add(Dropout(0.2))
regressor.add(Dense(units = 1))
regressor.compile(optimizer = 'adam', loss = 'mae')
regressor.fit(x_train, y_train, epochs = _epochs, steps_per_epoch = _steps_per_epoch)
return regressor
五、跑模型
sx = MinMaxScaler(feature_range=(0,1))
sy = MinMaxScaler(feature_range=(0,1))
sxx = MinMaxScaler(feature_range=(0,1))
syy = MinMaxScaler(feature_range=(0,1))
x_train, y_train, sx, sy = train_data(60, sx, sy)
x_test, y_test, sxx, syy = test_data(60, sx, sy)
regressor = stock_predict(x_train, y_train, _epochs=64, _steps_per_epoch=100)
actual_stock_price = y_test
predicted_stock_price = regressor.predict(x_test)
actual_stock_price = syy.inverse_transform(actual_stock_price)
predicted_stock_price = syy.inverse_transform(predicted_stock_price)```
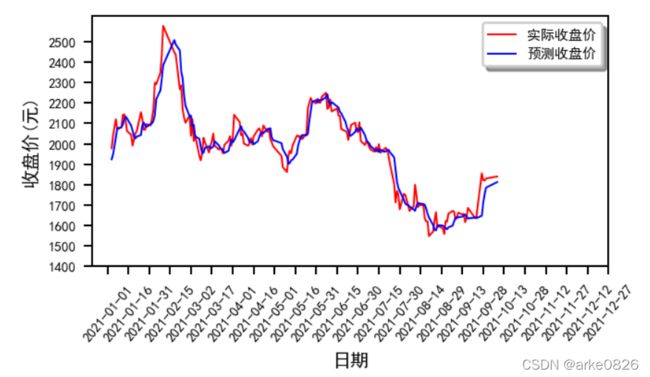
六、可视化
plt.figure(dpi = 180, figsize = (4,2))
plt.plot(actual_stock_price, color = 'r', label = '实际收盘价', linewidth=0.8)
plt.plot(predicted_stock_price, color = 'b', label = '预测收盘价', linewidth=0.8)
ax = plt.gca()
ax.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
plt.xticks(pd.date_range('2021-1-1','2022-1-1',freq='15d'), rotation = 50, fontsize = 6)
plt.yticks(range(1400, 2600, 100), fontsize = 6)
plt.xlabel('日期', fontsize = 8)
plt.ylabel('收盘价(元)', fontsize = 8)
plt.legend(shadow = True, fontsize = 6)
plt.show()
结果
总结
第一次做博客还是很菜的,本人也只是初学深度学习的小菜鸡一枚,还请各位大佬指正