改进粒子速度和位置更新公式的粒子群优化算法
文章目录
- 一、理论基础
-
- 1、相关工作
-
- 1.1 标准粒子群优化算法
- 1.2 粒子速度更新公式的改进
- 1.3 粒子位置更新公式的改进
- 2、改进算法
-
- 2.1 粒子速度和位置自适应更新策略
- 2.2 惯性权重的选取
- 2.3 算法实现
- 二、仿真实验及结果分析
- 三、参考文献
一、理论基础
1、相关工作
1.1 标准粒子群优化算法
标准PSO算法中,粒子通过学习自身历史经验( pbest \text{pbest} pbest)与群体经验( gbest \text{gbest} gbest)寻找最优粒子。对于求解变量为 X = { x 1 , x 2 , ⋯ , x D } X=\{x_1,x_2,\cdots,x_D\} X={x1,x2,⋯,xD}、目标函数为 min { f ( x ) } \min\{f(x)\} min{f(x)}的优化问题,标准PSO算法粒子更新公式为式(1)和式(2)。 v i d ( t + 1 ) = w v i d ( t ) + c 1 r 1 ( pbest i d − x i d ( t ) ) + c 2 r 2 ( gbest d − x i d ( t ) ) (1) v_{id}(t+1)=wv_{id}(t)+c_1r_1(\text{pbest}_{id}-x_{id}(t))+c_2r_2(\text{gbest}_d-x_{id}(t))\tag{1} vid(t+1)=wvid(t)+c1r1(pbestid−xid(t))+c2r2(gbestd−xid(t))(1) x i d ( t + 1 ) = x i d ( t ) + v i d ( t + 1 ) (2) x_{id}(t+1)=x_{id}(t)+v_{id}(t+1)\tag{2} xid(t+1)=xid(t)+vid(t+1)(2)其中, v i d ( t + 1 ) v_{id}(t+1) vid(t+1)和 x i d ( t + 1 ) x_{id}(t+1) xid(t+1)分别为粒子 i i i在 t + 1 t+1 t+1代的速度和位置; w w w是惯性权重,标准PSO算法中 w w w随迭代次数线性递减; c 1 c_1 c1和 c 2 c_2 c2为学习因子,通常取值为2; r 1 r_1 r1和 r 2 r_2 r2是 [ 0 , 1 ] [0,1] [0,1]均匀分布的随机数。
1.2 粒子速度更新公式的改进
文献[1]提出一种均值粒子群优化(MeanPSO)算法,即利用个体最优和群体最优的线性组合 pbest i d + gbest d 2 \displaystyle\frac{\text{pbest}_{id}+\text{gbest}_{d}}{2} 2pbestid+gbestd和 pbest i d − gbest d 2 \displaystyle\frac{\text{pbest}_{id}-\text{gbest}_{d}}{2} 2pbestid−gbestd分别替换公式(1)中 pbest i d \text{pbest}_{id} pbestid和 gbest d \text{gbest}_d gbestd,得到新的粒子速度更新公式,为式(3)。 v i d ( t + 1 ) = w v i d ( t ) + c 1 r 1 ( pbest i d + gbest d 2 − x i d ( t ) ) + c 2 r 2 ( pbest i d − gbest d 2 − x i d ( t ) ) (3) v_{id}(t+1)=wv_{id}(t)+c_1r_1\left(\frac{\text{pbest}_{id}+\text{gbest}_{d}}{2}-x_{id}(t)\right)+c_2r_2\left(\frac{\text{pbest}_{id}-\text{gbest}_{d}}{2}-x_{id}(t)\right)\tag{3} vid(t+1)=wvid(t)+c1r1(2pbestid+gbestd−xid(t))+c2r2(2pbestid−gbestd−xid(t))(3)MeanPSO算法中粒子搜索区间更广,使得算法在进化前期有更大可能搜索到全局最优解。
1.3 粒子位置更新公式的改进
文献[2]提出一种带有平均维度信息的分层简化粒子群优化(PHSPSO)算法,PHSPSO算法舍弃PSO算法中粒子速度更新项,并引入平均维度信息概念,即每个粒子所有维信息的平均值,计算公式为式(4)。同时PHSPSO算法将粒子位置更新公式分解为3种模式,分别为式(5)、(6)和(7)。 p a d ( t ) = 1 D ∑ i = 1 D x i d ( t ) (4) p_{ad}(t)=\frac1D\sum_{i=1}^Dx_{id}(t)\tag{4} pad(t)=D1i=1∑Dxid(t)(4) x i d ( t + 1 ) = w x i d ( t ) + c 1 r 1 ( pbest i d − x i d ( t ) ) (5) x_{id}(t+1)=wx_{id}(t)+c_1r_1(\text{pbest}_{id}-x_{id}(t))\tag{5} xid(t+1)=wxid(t)+c1r1(pbestid−xid(t))(5) x i d ( t + 1 ) = w x i d ( t ) + c 2 r 2 ( gbest d − x i d ( t ) ) (6) x_{id}(t+1)=wx_{id}(t)+c_2r_2(\text{gbest}_d-x_{id}(t))\tag{6} xid(t+1)=wxid(t)+c2r2(gbestd−xid(t))(6) x i d ( t + 1 ) = w x i d ( t ) + c 3 r 3 ( p a d − x i d ( t ) ) (7) x_{id}(t+1)=wx_{id}(t)+c_3r_3(p_{ad}-x_{id}(t))\tag{7} xid(t+1)=wxid(t)+c3r3(pad−xid(t))(7)其中,式(5)有助于算法的全局开发能力;式(6)有助于算法的局部开发能力,帮助算法跳出局部最优;式(7)有助于提升算法的收敛速度。在迭代过程中,算法基于概率选择不同的模式来更新粒子位置。
文献[3]指出采用“ X = X + V X=X+V X=X+V”来更新粒子位置有助于提高算法的局部开发能力,而“ X = w X + ( 1 − w ) V X=wX+(1-w)V X=wX+(1−w)V”有助于提高算法的全局探索能力,基于此本文提出一种自适应粒子位置更新机制,如式(8)和(9)所示。 p i = exp ( fit ( x i ( t ) ) ) exp ( 1 N ∑ i = 1 N fit ( x i ( t ) ) ) (8) p_i=\frac{\exp(\text{fit}(x_i(t)))}{\exp\left(\displaystyle\frac1N\sum_{i=1}^N\text{fit}(x_i(t))\right)}\tag{8} pi=exp(N1i=1∑Nfit(xi(t)))exp(fit(xi(t)))(8) x i d ( t + 1 ) = { w x i d ( t ) + ( 1 − w ) v i d ( t + 1 ) , p i > rand x i d ( t ) + v i d ( t + 1 ) , else (9) x_{id}(t+1)=\begin{dcases}wx_{id}(t)+(1-w)v_{id}(t+1),\quad p_i>\text{rand}\\[2ex]x_{id}(t)+v_{id}(t+1),\quad\quad\quad\quad\quad\text{else}\end{dcases}\tag{9} xid(t+1)=⎩⎨⎧wxid(t)+(1−w)vid(t+1),pi>randxid(t)+vid(t+1),else(9)其中, fit ( ⋅ ) \text{fit}(\cdot) fit(⋅)为粒子的适应度值, N N N为种群中粒子个数。式(8)中 p i p_i pi表示当前粒子适应度值与种群中所有粒子平均适应度值的比值,当 p i p_i pi较大时,当前粒子的适应度值远大于种群中所有粒子平均适应度值,此时应采用“ X = w X + ( 1 − w ) V X=wX+(1-w)V X=wX+(1−w)V”更新粒子位置以增强算法的全局探索能力,否则采用“ X = X + V X=X+V X=X+V”来更新粒子位置,来保证算法的局部开发能力。
2、改进算法
2.1 粒子速度和位置自适应更新策略
文献[4]结合以上分析提出一种新的自适应粒子速度和位置更新策略,如式(10)和(11)所示。 { v i d ( t + 1 ) = w v i d ( t ) + c 1 r 1 ( pbest i d + gbest d 2 − x i d ( t ) ) + c 2 r 2 ( pbest i d − gbest d 2 − x i d ( t ) ) x i d ( t + 1 ) = w x i d ( t ) + ( 1 − w ) v i d ( t + 1 ) (10) \begin{dcases}v_{id}(t+1)=wv_{id}(t)+c_1r_1\left(\frac{\text{pbest}_{id}+\text{gbest}_{d}}{2}-x_{id}(t)\right)+c_2r_2\left(\frac{\text{pbest}_{id}-\text{gbest}_{d}}{2}-x_{id}(t)\right)\\[2ex]x_{id}(t+1)=wx_{id}(t)+(1-w)v_{id}(t+1)\end{dcases}\tag{10} ⎩⎪⎨⎪⎧vid(t+1)=wvid(t)+c1r1(2pbestid+gbestd−xid(t))+c2r2(2pbestid−gbestd−xid(t))xid(t+1)=wxid(t)+(1−w)vid(t+1)(10) { v i d ( t + 1 ) = w v i d ( t ) + c 1 r 1 ( p a d − x i d ( t ) ) + c 2 r 2 ( gbest d − x i d ( t ) ) x i d ( t + 1 ) = x i d ( t ) + v i d ( t + 1 ) (11) \begin{dcases}v_{id}(t+1)=wv_{id}(t)+c_1r_1\left(p_{ad}-x_{id}(t)\right)+c_2r_2\left(\text{gbest}_d-x_{id}(t)\right)\\[2ex]x_{id}(t+1)=x_{id}(t)+v_{id}(t+1)\end{dcases}\tag{11} ⎩⎨⎧vid(t+1)=wvid(t)+c1r1(pad−xid(t))+c2r2(gbestd−xid(t))xid(t+1)=xid(t)+vid(t+1)(11)上述自适应策略借鉴文献[3]中 p i p_i pi作为自适应判定条件。当 p i > δ p_i>\delta pi>δ时,当前粒子的适应度值远大于种群中所有粒子平均适应度值,表明算法处于搜索初期或者当前粒子分布较为分散,此时应采用式(10)更新粒子速度和位置。式(10)在速度更新项中引入个体最优和群体最优的线性组合,能够使粒子的搜索空间更广,从而提高算法搜索到全局最优解的可能性,而位置更新则采用“ X = w X + ( 1 − w ) V X=wX+(1-w)V X=wX+(1−w)V”来提高算法的全局搜索能力;当 p i < δ p_i<\delta pi<δ时,当前粒子的适应度值与种群中所有粒子平均适应度值相差不大,表明算法处于搜索中后期或者当前粒子分布较为集中,此时应采用式(11)更新粒子速度和位置。在式(11)中,位置更新采用“ X = X + V X=X+V X=X+V”来保证算法局部开发能力,防止算法在求解复杂多峰函数时陷入局部最优,而将粒子平均维度信息 p a d p_{ad} pad引入到粒子速度更新公式中,提高算法的收敛速度。
2.2 惯性权重的选取
惯性权重 w w w是PSO算法的重要参数之一,它可以平衡算法全局探索能力和局部开发能力,标准PSO算法采用线性递减 w w w,这种线性调整的方式可以在一定程度上平衡算法探索能力与开发能力,而在面对复杂非线性多维函数优化问题时,算法容易陷入局部最优解。因此,为更好改善算法性能,一些学者提出惯性权重非线性调整策略。文献[4]采用文献[3]提出的基于Logistic混沌映射非线性变化惯性权重 w w w。
混沌映射作为一种非线性映射,因其所产生的混沌序列具有良好随机性和空间遍历性,在进化计算中得到广泛应用,其中Logistic映射应用较为广泛,它可以产生 [ 0 , 1 ] [0,1] [0,1]之间的随机数。式(12)给出了Logistic映射的定义, w w w的定义如式(13)。 r ( t + 1 ) = 4 r ( t ) ( 1 − r ( t ) ) , r ( 0 ) = rand , r ( 0 ) ≠ { 0 , 0.25 , 0.75 , 1 } (12) r(t+1)=4r(t)(1-r(t)),\,\,r(0)=\text{rand},\,\,r(0)\neq\{0,0.25,0.75,1\}\tag{12} r(t+1)=4r(t)(1−r(t)),r(0)=rand,r(0)={0,0.25,0.75,1}(12) w ( t ) = r ( t ) w min + ( w max − w min ) t T max (13) w(t)=r(t)w_{\min}+\frac{(w_{\max}-w_{\min})t}{T_{\max}}\tag{13} w(t)=r(t)wmin+Tmax(wmax−wmin)t(13)其中, w max = 0.9 , w min = 0.4 w_{\max}=0.9,w_{\min}=0.4 wmax=0.9,wmin=0.4; r ( t ) r(t) r(t)是由式(12)迭代产生的随机数。惯性权重随迭代次数的变化如图1所示。

2.3 算法实现
算法实现步骤如下:
步骤1 \quad 参数初始化,包括种群规模 N N N,最大迭代次数 T max = 1000 T_{\max}=1000 Tmax=1000,学习因子 c 1 c_1 c1和 c 2 c_2 c2,惯性权重 w w w;并在搜索空间内随机初始化粒子位置、速度;
步骤2 \quad 根据给定目标函数计算所有粒子适应度值;
步骤3 \quad 比较种群中所有粒子的适应度值与其经历过的最优位置适应度值的优劣,若前者更优,则用粒子的当前位置替代粒子的个体历史最优位置;
步骤4 \quad 比较种群中所有个体最优位置的适应度值与整个群体经历过的最优位置的适应度值的优劣,若前者更优,则更新全局最优位置;
步骤5 \quad 根据式(8)计算 p i p_i pi,若 p i > δ p_i>\delta pi>δ,则利用式(10)更新粒子的速度和位置;否则,利用式(11)更新粒子的速度和位置;
步骤6 \quad 判断是否满足终止条件,若满足,则算法终止并输出最优值;否则,转至步骤2。
二、仿真实验及结果分析
为验证文献[4]所提算法(IPSO-VP)有效性,将文献[4]算法与线性递减惯性权重粒子群优化(LDWPSO)算法[5]、均值粒子群优化(MeanPSO)算法[1]、社会学习粒子群优化(SL-PSO)算法[6]、基于概率分层的简化粒子群优化(PHSPSO)算法[2]、基于终端交叉和转向扰动的粒子群优化(TCSPSO)算法[7]、一种基于自适应策略的改进粒子群优化(MPSO)算法[3]进行对比测试,以文献[4]中表1的12个测试函数为例,使用Matlab软件进行仿真,不同PSO算法设置相同种群规模 N = 100 N=100 N=100、最大迭代次数 T max = 1000 T_{\max}=1000 Tmax=1000和变量维数 D = 30 D=30 D=30,其他参数设置与原文保持一致,具体见文献[4]中表3,每个算法独立运行50次,结果显示如下:




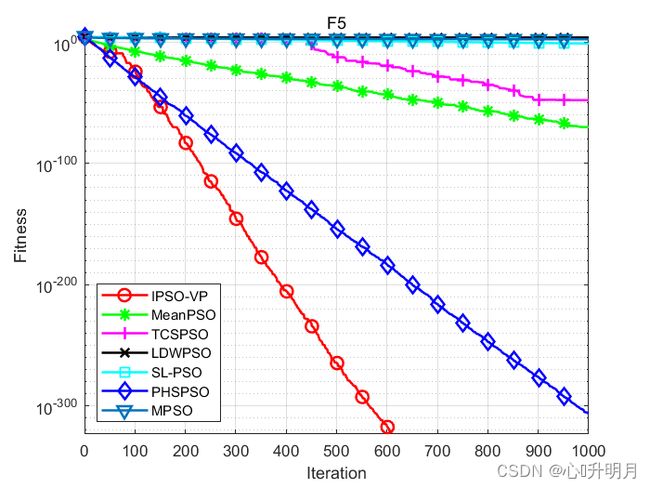






函数:F1
IPSO-VP:最优值: 0, 最差值: 0, 平均值: 0, 标准差: 0
MeanPSO:最优值: 6.8646e-86, 最差值: 5.9281e-71, 平均值: 1.8817e-72, 标准差: 8.9253e-72
TCSPSO:最优值: 5.6373e-114, 最差值: 4.9045e-55, 平均值: 9.8176e-57, 标准差: 6.9359e-56
LDWPSO:最优值: 0, 最差值: 0.91227, 平均值: 0.039838, 标准差: 0.15901
SL-PSO:最优值: 6.3084e-46, 最差值: 2.8089e-43, 平均值: 3.138e-44, 标准差: 4.5876e-44
PHSPSO:最优值: 0, 最差值: 3.6331e-318, 平均值: 8.7455e-320, 标准差: 0
MPSO:最优值: 2.5347e-73, 最差值: 6.1736e-57, 平均值: 1.2377e-58, 标准差: 8.7304e-58
函数:F2
IPSO-VP:最优值: 0, 最差值: 0, 平均值: 0, 标准差: 0
MeanPSO:最优值: 0, 最差值: 6.1457e-71, 平均值: 2.6063e-72, 标准差: 1.1072e-71
TCSPSO:最优值: 1.3652e-124, 最差值: 1.4709e-54, 平均值: 3.1769e-56, 标准差: 2.0801e-55
LDWPSO:最优值: 0, 最差值: 3284.4655, 平均值: 491.1481, 标准差: 766.9553
SL-PSO:最优值: 8.4655e-46, 最差值: 1.5845e-43, 平均值: 1.9671e-44, 标准差: 2.6786e-44
PHSPSO:最优值: 0, 最差值: 2.3647e-316, 平均值: 9.0693e-318, 标准差: 0
MPSO:最优值: 2.0274e-73, 最差值: 4.6725e-58, 平均值: 9.6728e-60, 标准差: 6.6051e-59
函数:F3
IPSO-VP:最优值: 0, 最差值: 0, 平均值: 0, 标准差: 0
MeanPSO:最优值: 5.283e-96, 最差值: 4.1191e-78, 平均值: 1.1412e-79, 标准差: 5.9438e-79
TCSPSO:最优值: 1.4865e-159, 最差值: 1.3319e-77, 平均值: 2.6639e-79, 标准差: 1.8837e-78
LDWPSO:最优值: 0, 最差值: 5.4479e-10, 平均值: 2.1166e-11, 标准差: 8.3114e-11
SL-PSO:最优值: 2.2139e-118, 最差值: 4.0772e-104, 平均值: 8.4391e-106, 标准差: 5.763e-105
PHSPSO:最优值: 4.6532e-99, 最差值: 1.3859e-77, 平均值: 2.7718e-79, 标准差: 1.9599e-78
MPSO:最优值: 1.8882e-219, 最差值: 1.3464e-178, 平均值: 3.1723e-180, 标准差: 0
函数:F4
IPSO-VP:最优值: 4.5551e-266, 最差值: 5.7613e-243, 平均值: 1.4013e-244, 标准差: 0
MeanPSO:最优值: 0, 最差值: 9.3944e-37, 平均值: 1.1951e-37, 标准差: 2.2013e-37
TCSPSO:最优值: 2.7039e-71, 最差值: 3.0697e-52, 平均值: 1.0024e-53, 标准差: 4.6749e-53
LDWPSO:最优值: 0, 最差值: 20.2796, 平均值: 3.6956, 标准差: 5.2418
SL-PSO:最优值: 2.5159e-24, 最差值: 8.9502e-23, 平均值: 2.5257e-23, 标准差: 1.8106e-23
PHSPSO:最优值: 1.2117e-164, 最差值: 1.4035e-158, 平均值: 6.0033e-160, 标准差: 2.1005e-159
MPSO:最优值: 1.1517e-39, 最差值: 4.4154e-33, 平均值: 1.0053e-34, 标准差: 6.2431e-34
函数:F5
IPSO-VP:最优值: 0, 最差值: 0, 平均值: 0, 标准差: 0
MeanPSO:最优值: 8.3741e-89, 最差值: 3.2567e-69, 平均值: 9.8745e-71, 标准差: 4.7812e-70
TCSPSO:最优值: 7.0918e-143, 最差值: 9.8839e-47, 平均值: 1.9768e-48, 标准差: 1.3978e-47
LDWPSO:最优值: 0, 最差值: 15186.9885, 平均值: 3974.1626, 标准差: 4628.8783
SL-PSO:最优值: 0.0047206, 最差值: 0.4358, 平均值: 0.091848, 标准差: 0.088621
PHSPSO:最优值: 0, 最差值: 3.2058e-305, 平均值: 6.4717e-307, 标准差: 0
MPSO:最优值: 13.8853, 最差值: 1707.2201, 平均值: 312.9347, 标准差: 277.632
函数:F6
IPSO-VP:最优值: 8.8818e-16, 最差值: 8.8818e-16, 平均值: 8.8818e-16, 标准差: 0
MeanPSO:最优值: 8.8818e-16, 最差值: 8.8818e-16, 平均值: 8.8818e-16, 标准差: 0
TCSPSO:最优值: 8.8818e-16, 最差值: 8.8818e-16, 平均值: 8.8818e-16, 标准差: 0
LDWPSO:最优值: 8.8818e-16, 最差值: 13.8122, 平均值: 0.60472, 标准差: 2.7433
SL-PSO:最优值: 4.4409e-15, 最差值: 7.9936e-15, 平均值: 6.7857e-15, 标准差: 1.7e-15
PHSPSO:最优值: 8.8818e-16, 最差值: 8.8818e-16, 平均值: 8.8818e-16, 标准差: 0
MPSO:最优值: 8.8818e-16, 最差值: 4.4409e-15, 平均值: 4.2277e-15, 标准差: 8.5229e-16
函数:F7
IPSO-VP:最优值: 0, 最差值: 0, 平均值: 0, 标准差: 0
MeanPSO:最优值: 0, 最差值: 0, 平均值: 0, 标准差: 0
TCSPSO:最优值: 0, 最差值: 0, 平均值: 0, 标准差: 0
LDWPSO:最优值: 0, 最差值: 104.6241, 平均值: 25.9934, 标准差: 25.9937
SL-PSO:最优值: 8.9546, 最差值: 29.8488, 平均值: 13.81, 标准差: 3.8226
PHSPSO:最优值: 0, 最差值: 0, 平均值: 0, 标准差: 0
MPSO:最优值: 0, 最差值: 74.1012, 平均值: 17.8264, 标准差: 20.8861
函数:F8
IPSO-VP:最优值: 0, 最差值: 0, 平均值: 0, 标准差: 0
MeanPSO:最优值: 0, 最差值: 0, 平均值: 0, 标准差: 0
TCSPSO:最优值: 0, 最差值: 0, 平均值: 0, 标准差: 0
LDWPSO:最优值: 0, 最差值: 60.25, 平均值: 15.2192, 标准差: 16.7802
SL-PSO:最优值: 32, 最差值: 53, 平均值: 40.08, 标准差: 5.2014
PHSPSO:最优值: 0, 最差值: 0, 平均值: 0, 标准差: 0
MPSO:最优值: 19.6972, 最差值: 151.837, 平均值: 53.9991, 标准差: 30.5432
函数:F9
IPSO-VP:最优值: 0, 最差值: 0, 平均值: 0, 标准差: 0
MeanPSO:最优值: 0, 最差值: 0, 平均值: 0, 标准差: 0
TCSPSO:最优值: 0, 最差值: 0, 平均值: 0, 标准差: 0
LDWPSO:最优值: 0, 最差值: 0.6829, 平均值: 0.040769, 标准差: 0.12944
SL-PSO:最优值: 0, 最差值: 0.0098647, 平均值: 0.00054236, 标准差: 0.0021875
PHSPSO:最优值: 0, 最差值: 0, 平均值: 0, 标准差: 0
MPSO:最优值: 0, 最差值: 0, 平均值: 0, 标准差: 0
函数:F10
IPSO-VP:最优值: 1.4998e-32, 最差值: 1.4998e-32, 平均值: 1.4998e-32, 标准差: 1.3823e-47
MeanPSO:最优值: 8.0709e-06, 最差值: 1.3233, 平均值: 0.40072, 标准差: 0.41418
TCSPSO:最优值: 0.69528, 最差值: 1.8328, 平均值: 1.2517, 标准差: 0.28216
LDWPSO:最优值: 0.13685, 最差值: 4.7504, 平均值: 0.93702, 标准差: 1.0571
SL-PSO:最优值: 1.4998e-32, 最差值: 0.45432, 平均值: 0.023545, 标准差: 0.091378
PHSPSO:最优值: 7.4448e-09, 最差值: 2.4401e-06, 平均值: 4.3436e-07, 标准差: 5.1923e-07
MPSO:最优值: 0.0085016, 最差值: 0.42659, 平均值: 0.1422, 标准差: 0.10651
函数:F11
IPSO-VP:最优值: 4.6349e-21, 最差值: 1.182e-13, 平均值: 7.1471e-15, 标准差: 2.1663e-14
MeanPSO:最优值: 5.2295e-05, 最差值: 0.13511, 平均值: 0.057518, 标准差: 0.031228
TCSPSO:最优值: 0.056151, 最差值: 0.76795, 平均值: 0.26317, 标准差: 0.16111
LDWPSO:最优值: 0.00092593, 最差值: 2.063, 平均值: 0.074796, 标准差: 0.30378
SL-PSO:最优值: 1.5705e-32, 最差值: 1.5705e-32, 平均值: 1.5705e-32, 标准差: 5.5294e-48
PHSPSO:最优值: 3.2248e-10, 最差值: 1.5657e-07, 平均值: 3.3779e-08, 标准差: 3.4082e-08
MPSO:最优值: 0.00041682, 最差值: 0.010294, 平均值: 0.0019032, 标准差: 0.0020786
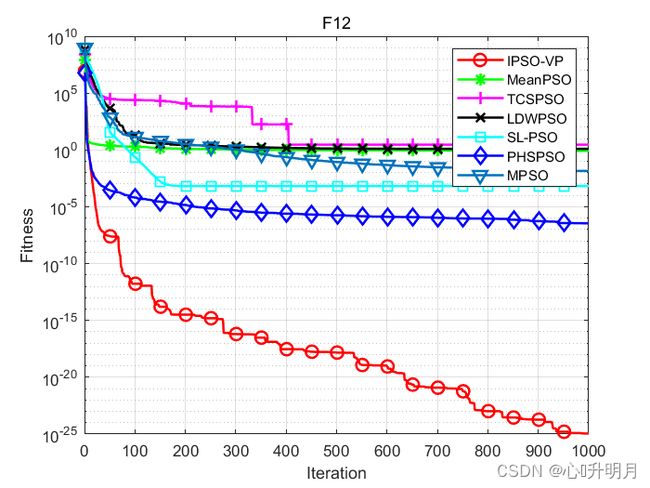
函数:F12
IPSO-VP:最优值: 1.3498e-32, 最差值: 3.8301e-24, 平均值: 1.1314e-25, 标准差: 5.6851e-25
MeanPSO:最优值: 8.1743e-05, 最差值: 2.7016, 平均值: 0.8306, 标准差: 0.60677
TCSPSO:最优值: 2.0026, 最差值: 2.998, 平均值: 2.9169, 标准差: 0.23732
LDWPSO:最优值: 0.041643, 最差值: 3.4192, 平均值: 1.2515, 标准差: 0.87477
SL-PSO:最优值: 1.3498e-32, 最差值: 0.010987, 平均值: 0.00065924, 标准差: 0.0026358
PHSPSO:最优值: 4.775e-10, 最差值: 1.4829e-06, 平均值: 3.4713e-07, 标准差: 3.5818e-07
MPSO:最优值: 0.00094959, 最差值: 0.20431, 平均值: 0.013967, 标准差: 0.02913
实验结果表明:IPSO-VP算法在收敛速度和寻优精度方面均优于其他6种改进算法。
三、参考文献
[1] Deep K, Bansal J C. Mean particle swarm optimisation for function optimisation[J]. International Journal of Computational Intelligence Studies, 2009, 1(1): 72-92.
[2] Hao-Ran Liu, Jing-Chuang Cui, Ze-Dan Lu, et al. A hierarchical simple particle swarm optimization with mean dimensional information[J]. Applied Soft Computing, 2019, 76: 712-725.
[3] Hao Liu, Xu-Wei Zhang , Liang-Ping Tu. A modified particle swarm optimization using adaptive strategy[J]. Expert Systems With Applications, 2020, 152: 113353.
[4] 李二超, 高振磊. 改进粒子速度和位置更新公式的粒子群优化算法[J]. 南京师大学报(自然科学版), 2022, 45(1): 118-126.
[5] Y. Shi, R. Eberhart. A modified particle swarm optimizer[C]. 1998 IEEE International Conference on Evolutionary Computation Proceedings. IEEE World Congress on Computational Intelligence (Cat. No.98TH8360), 1998, 4: 69-73.
[6] Ran Cheng, Yaochu Jin. A social learning particle swarm optimization algorithm for scalable optimization[J]. Information Sciences, 2015, 291: 43-60.
[7] XuWei Zhang, Hao Liu, Tong Zhang, et al. Terminal crossover and steering-based particle swarm optimization algorithm with disturbance[J]. Applied Soft Computing Journal, 2019, 85: 105841.