GoogLeNet Inception v3& LSN详解
GoogLeNet Inception v3 & Label Smoothing
论文《Rethinking the Inception Architecture for Computer Vision》
1 设计背景
文中针对如何构建Inception风格的卷积神经网络提出了一些设计准则,并根据这些准则,设计实现了基于Inception v3模块的GoogLeNet模型。
2 通用设计准则
- 避免模型出现特征瓶颈;
Avoid representational bottlenecks, especially early in the network.
模型在卷积过程中,应该避免对输入进行极端的压缩,输入的大小在整个卷积过程中应该平缓的减小。
- 高维的特征更容易处理;
Higher dimensional representations are easier to pro- cess locally within a network.
特征数目越多(可能有部分特征是非独立的),训练的速度越快。
- 降低通道维度的embedding操作损失较小;
Spatial aggregation can be done over lower dimen- sional embeddings without much or any loss in representational power.
通过降低输入的通道维度,可以降低模型的开销,加快模型的训练过程。
- 平衡网络的深度和宽度
Balance the width and depth of the network.
同时提高模型的宽度和深度会极大增加模型的训练时的开销,需要在宽度和深度之间达到平衡。
3 模型优化
3.1 Filter分解
3.1.1 大Filter分解为小Filter
较大的filter的感受野较大,可以获得距离较远的单位之间的相关性,但同时也意味在卷积操作时会有更大的开销。
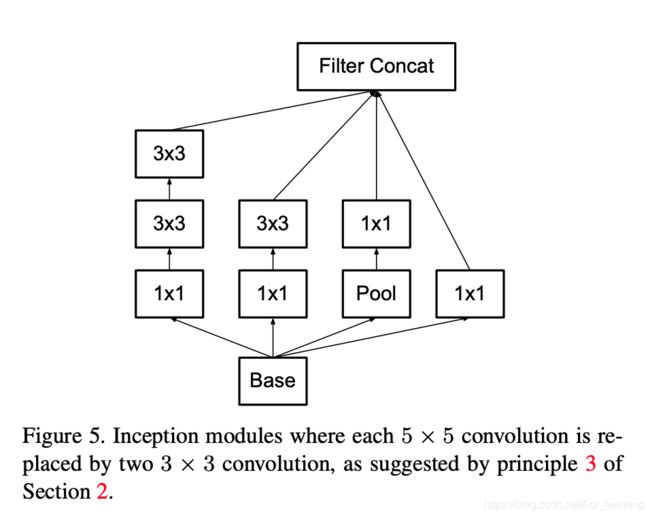
类似于VGGNet,使用多个较小的filter替代较大filter,在感受野保持不变的前提下,减少卷积操作的计算开销。
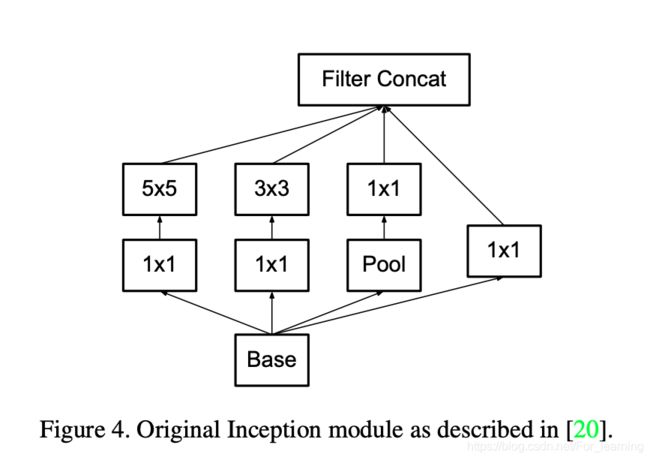
基于上述思路,在原有的Inception模块的基础上进行改进,改进前后的Inception模块的结构如下。
3.1.2 对称Filter分解为非对称Filter
基于filter分解的思想,文中开始讨论对3*3的卷积层急进行进一步分解。
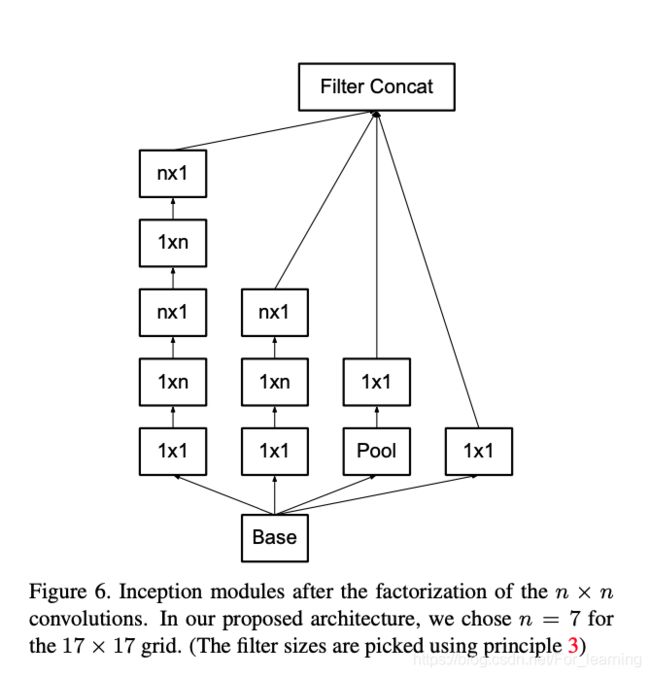
通过将5*5的卷积层分解为两层3*3的卷积层,在不改变感受野的前提下,降低了参数数量和卷积时的计算量。那么是否可以对3*3的卷积层进一步分解?针对这个问题,文中提出了非对称Filter分解,即将n*n的fitler分解为n*1和1*n的filter。
文中对比了3*3的filter分解为2个2*2的filter时和3*3的filter分解为3*1和1*3的filter时,卷积操作的参数数量变化情况。相比于3*3的卷积层,这两种分解方式分别减少了11%和33%的参数。由此看来非对称分解的收益更高。
基于上述思路,文中对Inception模块进行了进一步的改进,改进后的Inception模块的具体结构如下图。
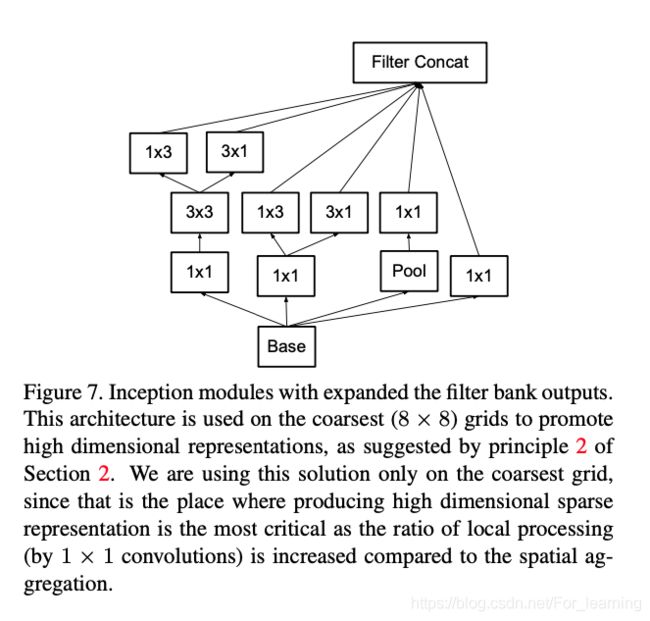
3.2 辅助分类器
在GoogLeNet Inception v1中,提出了使用辅助分类器加快模型收敛速度,避免梯度消失问题的论点。
文中针对辅助分类器进行了实验,发现辅助分类器对模型的收敛速度和准确度提升不大:在模型达到较高准确度之前,训练的速度相同;达到较高准确度后,辅助分类器稍微(slightly)提高了模型的准确度。总体来说,去掉辅助分类器对模型的收敛速度无不利影响。
文中又对辅助分类器的正则化效果进行了讨论,认为辅助分类器中加入Dropout或BN后,主分类器的表现会更好。
3.3 高效的feature mapping大小降低方法
卷积神经网络中,池化操作会降低feature mapping的大小,基于通用设计准则1,为了避免出现特征瓶颈(representational bottleneck),需要先增加filter的数量(feature mapping的通道维度),再使用pooling降低feature mapping空间维度的大小。
文中使用3*3的卷积操作来提高feature mapping的通道维度,将通道数量提高一倍;使用2*2的池化操作降低feature mapping空间维度,将大小缩减一倍。
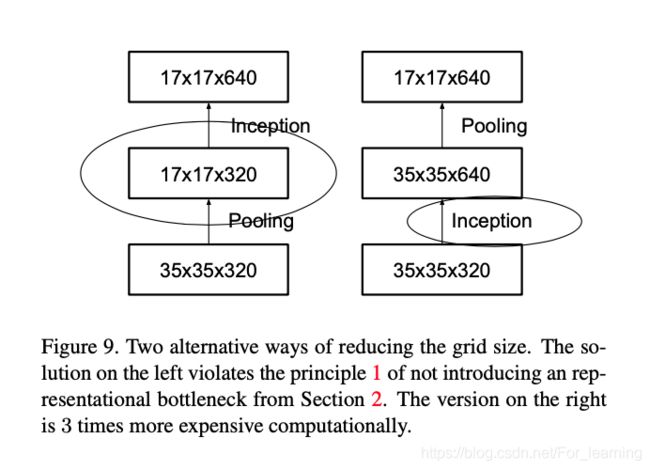
如上图所示,左图会违背通用设计准则1,导致模型出现特征瓶颈,通过改变卷积操作(提高通道维度)和池化操作(降低空间维度)的顺序,避免了特征瓶颈,如右图所示。
但是在没有降低feature mapping的空间维度前,通过卷积操作提高feature mapping的通道维度,会导致计算开销增大。
以上图为例,右图虽然可以避免特征瓶颈,但是计算开销比左图大了4.23倍。
针对这个问题,文中提出了同时进行卷积操作和池化操作。通过卷积操作和池化操作降低feature mapping的空间维度,最后将卷积操作和池化操作的结果在feature mapping的通道维度进行叠加,这样就实现了在降低feature mapping的空间维度的同时,提高了feature mapping的通道维度,具体结构如下图。
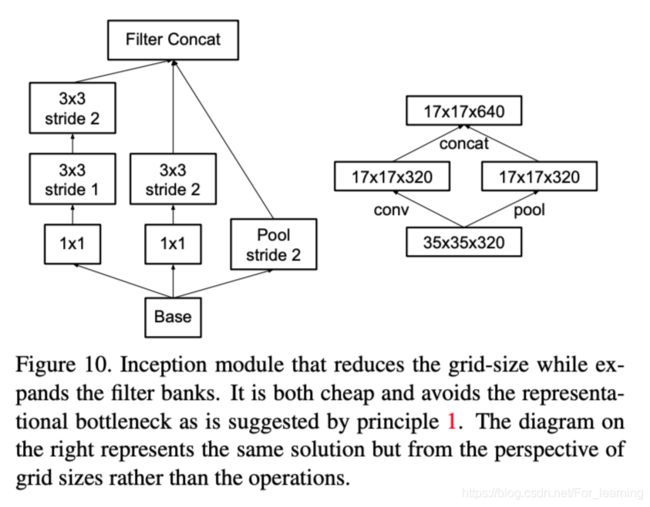
3.4 标签平滑正则化(LSN)
文中还提出了一种新的正则化方式:标签平滑正则化(Label Smoothing Normalization)。
使用LSN后,减小了模型对正类的更新幅度,以此来增加模型的泛化能力。

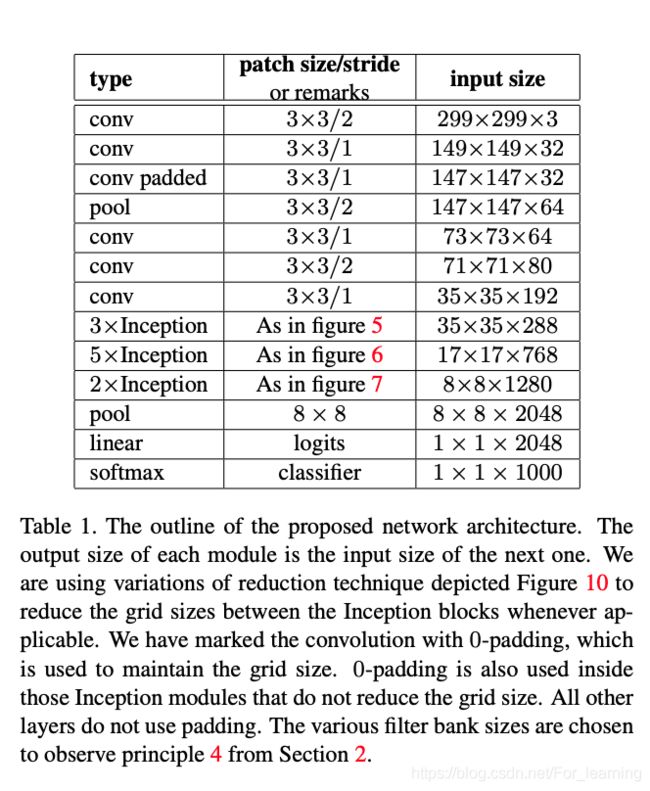
4 模型整体结构