图神经网络--pytorch_geometric基本使用
GCN论文地址:https://arxiv.org/abs/1609.02907
1.pytorch_geometric的安装
不建议直接使用pip install直接进行安装,参考其GITHUB:GitHub - pyg-team/pytorch_geometric: Graph Neural Network Library for PyTorch
首先打开github,点击此处,进入到所需要的依赖文件的界面:

选择合适的版本,进行安装,可以下载的本地,再进入到下载路径,用pip install安装

2.绘制图结构
使用network库可以绘制图结构
%matplotlib inline
import torch
import networkx as nx # 绘制整个图
import matplotlib.pyplot as plt
# 绘制整个图函数
def visualize_graph(G, color):
plt.figure(figsize=(7,7))
plt.xticks([])
plt.yticks([])
nx.draw_networkx(G, pos=nx.spring_layout(G, seed=42), with_labels=False,
node_color=color, cmap="Set2")
plt.show()
# 绘制图中的每个点
def visualize_embedding(h, color, epoch=None, loss=None):
plt.figure(figsize=(7,7))
plt.xticks([])
plt.yticks([])
h = h.detach().cpu().numpy()
plt.scatter(h[:, 0], h[:, 1], s=140, c=color, cmap="Set2")
if epoch is not None and loss is not None:
plt.xlabel(f'Epoch: {epoch}, Loss: {loss.item():.4f}', fontsize=16)
plt.show()3.Graph Neural Networks
- 致力于解决不规则数据结构(图像和文本相对格式都固定,但是社交网络与化学分子等格式肯定不是固定的)
- GNN模型迭代更新主要基于图中每个节点及其邻居的信息,基本表示如下:
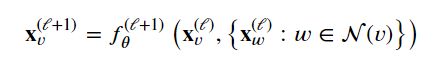
![]()
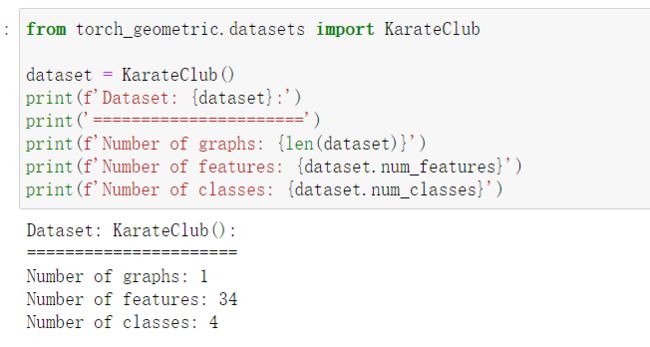
4.数据集:Zachary's karate club network.
该图描述了一个空手道俱乐部会员的社交关系,以34名会员作为节点,如果两位会员在俱乐部之外仍保持社交关系,则在节点间增加一条边。 每个节点具有一个34维的特征向量,一共有78条边。 在收集数据的过程中,管理人员 John A 和 教练 Mr. Hi(化名)之间产生了冲突,会员们选择了站队,一半会员跟随 Mr. Hi 成立了新俱乐部,剩下一半会员找了新教练或退出了俱乐部。
任务:预测会员的去向
数据集可以直接参考其API:https://pytorch-geometric.readthedocs.io/en/latest/modules/datasets.html#torch_geometric.datasets.KarateClub
数据集由一个图构成,每个点有34个features,需要对每个节点进行四分类。
图的表示:torch_geometric.data — pytorch_geometric documentation
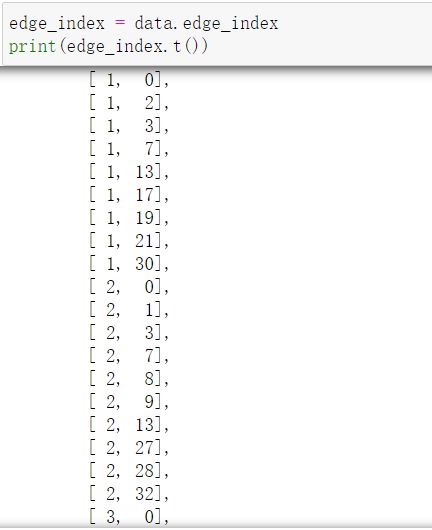
x表示数据,一共有34个点,每个点有34个特征。edge_index:表示图的连接关系(start,end两个序列),y表示标签,train_mask表示哪些点存在标签,只用存在标签的点计算损失。

edge_index表示图的连接关系(start,end两个序列),index是稀疏表示的,并不是n*n的邻接矩阵。
使用networkx可视化展示
from torch_geometric.utils import to_networkx
G = to_networkx(data, to_undirected=True)
visualize_graph(G, color=data.y)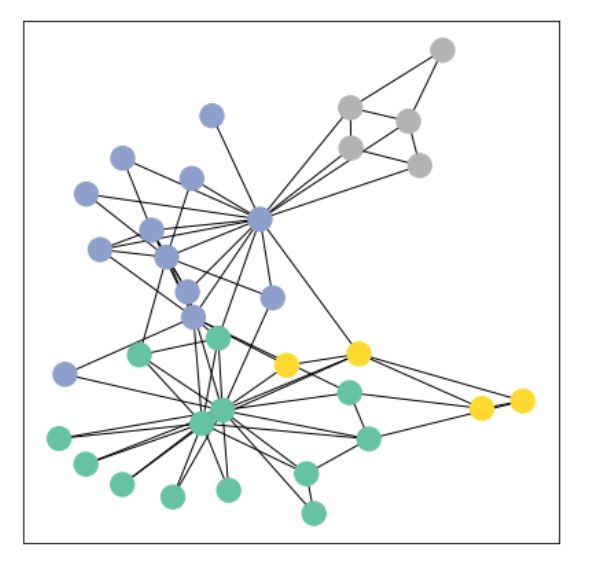
Graph Neural Networks 网络定义:
import torch
from torch.nn import Linear
from torch_geometric.nn import GCNConv
class GCN(torch.nn.Module):
def __init__(self):
super().__init__()
torch.manual_seed(1234)
self.conv1 = GCNConv(dataset.num_features, 4) # 只需定义好输入特征和输出特征即可
self.conv2 = GCNConv(4, 4)
self.conv3 = GCNConv(4, 2)
self.classifier = Linear(2, dataset.num_classes)
def forward(self, x, edge_index):
h = self.conv1(x, edge_index) # 输入特征与邻接矩阵(注意格式,上面那种)
h = h.tanh()
h = self.conv2(h, edge_index)
h = h.tanh()
h = self.conv3(h, edge_index)
h = h.tanh()
# 分类层
out = self.classifier(h)
return out, h
model = GCN()
print(model)GCN( (conv1): GCNConv(34, 4) (conv2): GCNConv(4, 4) (conv3): GCNConv(4, 2) (classifier): Linear(in_features=2, out_features=4, bias=True) )
输出特征展示
模型初始化的特征
model = GCN()
_, h = model(data.x, data.edge_index)
print(f'Embedding shape: {list(h.shape)}')
visualize_embedding(h, color=data.y)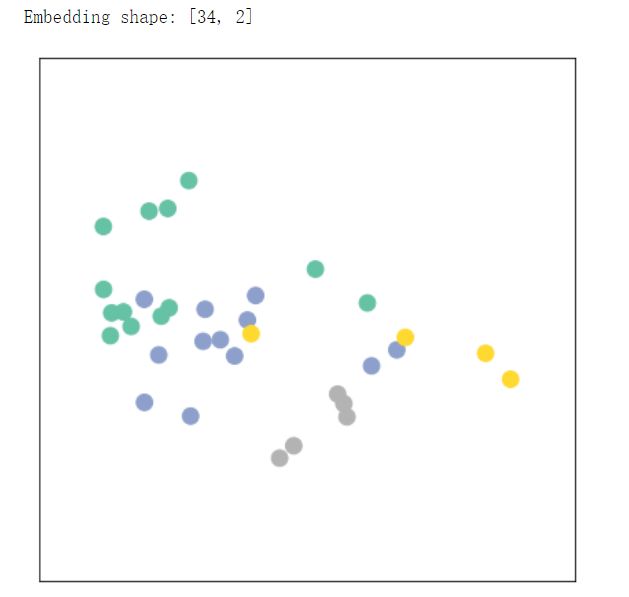
训练模型(semi-supervised)
import time
model = GCN()
criterion = torch.nn.CrossEntropyLoss() # Define loss criterion.
optimizer = torch.optim.Adam(model.parameters(), lr=0.01) # Define optimizer.
def train(data):
optimizer.zero_grad()
out, h = model(data.x, data.edge_index) #h是两维向量,主要是为了咱们画个图
loss = criterion(out[data.train_mask], data.y[data.train_mask]) # semi-supervised
loss.backward()
optimizer.step()
return loss, h
for epoch in range(401):
loss, h = train(data)
if epoch % 10 == 0:
visualize_embedding(h, color=data.y, epoch=epoch, loss=loss)
time.sleep(0.3)特征区分度逐渐明显

图分类任务
对于图分类任务,我们还是采取相同的特征提取方式,但在输出层,我们只需要聚合整个图的信息即可。
把各个节点特征汇总成全局特征就相当于得到了整个图的编码:
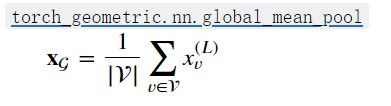
from torch.nn import Linear
import torch.nn.functional as F
from torch_geometric.nn import GCNConv
from torch_geometric.nn import global_mean_pool
class GCN(torch.nn.Module):
def __init__(self, hidden_channels):
super(GCN, self).__init__()
torch.manual_seed(12345)
self.conv1 = GCNConv(dataset.num_node_features, hidden_channels)
self.conv2 = GCNConv(hidden_channels, hidden_channels)
self.conv3 = GCNConv(hidden_channels, hidden_channels)
self.lin = Linear(hidden_channels, dataset.num_classes)
def forward(self, x, edge_index, batch):
# 1.对各节点进行编码
x = self.conv1(x, edge_index)
x = x.relu()
x = self.conv2(x, edge_index)
x = x.relu()
x = self.conv3(x, edge_index)
# 2. 平均操作
x = global_mean_pool(x, batch) # [batch_size, hidden_channels]
# 3. 输出
x = F.dropout(x, p=0.5, training=self.training)
x = self.lin(x)
return x
model = GCN(hidden_channels=64)
print(model)GCN( (conv1): GCNConv(7, 64) (conv2): GCNConv(64, 64) (conv3): GCNConv(64, 64) (lin): Linear(in_features=64, out_features=2, bias=True) )
model = GCN(hidden_channels=64)
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
criterion = torch.nn.CrossEntropyLoss()
def train():
model.train()
for data in train_loader: # Iterate in batches over the training dataset.
out = model(data.x, data.edge_index, data.batch) # Perform a single forward pass.
loss = criterion(out, data.y) # Compute the loss.
loss.backward() # Derive gradients.
optimizer.step() # Update parameters based on gradients.
optimizer.zero_grad() # Clear gradients.
def test(loader):
model.eval()
correct = 0
for data in loader: # Iterate in batches over the training/test dataset.
out = model(data.x, data.edge_index, data.batch)
pred = out.argmax(dim=1) # Use the class with highest probability.
correct += int((pred == data.y).sum()) # Check against ground-truth labels.
return correct / len(loader.dataset) # Derive ratio of correct predictions.
for epoch in range(1, 171):
train()
train_acc = test(train_loader)
print(f'Epoch: {epoch:03d}, Train Acc: {train_acc:.4f}')
遇到特别大的图该怎么办?
cluster gcn 是graphsage之后,由google提出的一种新的gcn的拓展,解决了gcn的两个问题:
1 计算量高,显存压力太大,尤其是GCN的基于批梯度下降法(没有mini-batch直接whole batch ,一个epoch 训练全部节点),显存压力非常高,并且随着GCN layer的层数增长,显存占用指数增长;
2 GCN无法insductive(这里指的是没有使用sage这类的策略来辅助而是单纯指最原始的GCN,不过感觉cluster gcn其实本质上还是要通过sage的采样策略才能实现indstuctive,这一点有待商榷)
cluster gcn是怎么进行mini-batch的
Cluster GCN的思路很巧妙,和graphsage中做节点领域采样的方式不同,cluster是通过社区发现对图进行分区,例如将一个大图聚类为n个小图,然后每个小图作为一个batch分别使用GCN(当然其它gnn也可以)训练,这一方面大大降低了显存压力,另一方面限制了节点的邻域的范围。
参考:cluster GCN - 知乎