线性模型——最小二乘法,梯度下降,线性回归,logistic回归
线性模型——最小二乘法,梯度下,线性回归,logistic回归(逻辑回归)
(一)基本形式
- 线性模型: 给定d个属性描述的示例X = (x1;x2;……;xd)(X为列向量),xi是第i个属性上的取值。 线性模型(linear model)试图学得一个通过属性的线性组合进行预测的函数。
f ( X ) = w 1 x 1 + w 2 x 2 + … + w d x d + b f(X) = w_1x_1 + w_2x_2+…+w_dx_d+b f(X)=w1x1+w2x2+…+wdxd+b
向量形式:
f ( X ) = W T X + b f(X)=W^TX+b f(X)=WTX+b
其中W = (w1;w2;……;wd)。学习过程就是调整W和b。
线性模型的优点:
- 线性模型形式简单,易于建模,却蕴含着机器学习中的一些重要的基本思想。许多功能更为强大的非线性模型(nonlinear model)可在线性模型基础上通过引入层级结或更高维映射而得。
- 线性模型有很好得可解释性(comprehensibility):因为W直观表达了各属性在预测中得重要性。
(二)线性回归(linear regression)
- 线性回归(linear regression): 给定数据集D = {(X1,y1),(X2,y2),……,(Xm,ym)},其中Xi = (xi1;xi2;……xid),yi ∈ R,线性回归试图学得一个线性模型以尽可能准确地预测实值输出标记。
- 若属性值之间存在“序”的关系:可通过连续化将其转化为连续值,如身高地高、矮可转化为{1.0, 0.0}。
- 若属性之间不存在"序“的关系,假定有k个属性值,则通常转换为k维向量,例如西瓜、南瓜、黄瓜可转化为{(0, 0, 1), (0, 1, 0), (1, 0, 0)}。
1.最小二乘法(least square method)
- 最小二乘法(least square method): 基于均方误差最小化来进行模型求解的方法称为最小二乘法。
- 均方误差具有非常好的几何意义,它对应了常用的欧几里得距离(欧氏距离)。
( w ∗ , b ∗ ) = a r g m i n ∑ i = 1 m ( f ( x i ) − y i ) 2 = a r g m i n ∑ i = 1 m ( y i − w x i − b ) 2 ( w ∗ , b ∗ 表 示 w , b 的 解 ) (w^*,b^*) = arg min\sum_{i=1}^{m}{(f(x_i) - y_i)^2} = argmin\sum_{i=1}^{m}{(y_i-wx_i-b)^2}(w^*,b^*表示w,b的解) (w∗,b∗)=argmini=1∑m(f(xi)−yi)2=argmini=1∑m(yi−wxi−b)2(w∗,b∗表示w,b的解)
E ( w , b ) = ∑ i = 1 m ( y i − w x i − b ) 2 E(w,b) = \sum_{i=1}^{m}{(y_i - wx_i - b)^2} E(w,b)=i=1∑m(yi−wxi−b)2
- 参数估计(parameter estimation): 求解w和b使均方误差最小化的过程,称为对线性回归模型的最小二乘“参数估计”

以上是针对一个属性的样本求解,对于一般情形,样本由d个属性描述,此时我们试图学得
f ( x i ) 1 = w T x i + b , 使 得 f ( x i ) − > i f(x_i)1 = w^Tx_i+b,使得f(x_i)->_i f(xi)1=wTxi+b,使得f(xi)−>i
这称为多元线性回归(multivariate linear regression)。以下是采用最小二乘法的正则化求解过程:
使用正则方程组必须满足XTX可逆,即为满秩矩阵。但是在实际问题中,数据集的特征数n可能大于数据集规模m,这导致矩阵不可逆。因此,通常在计算(xTx)^-1之前在xTx加上一个较小的可逆矩阵,如0.001E(E为单位矩阵)。


- *有关最小二乘法的概率解释:

注:上述的最小二乘估计解释和下面的梯度下降算法都来自于《机器学习入门基于数学原理的Python实战》戴璞微,潘斌。
2.梯度下降算法
虽然迭代更新的算法有很多种,但是梯度下降算法是最好理解的一种。当前梯度下降算法主要分为三种:
- 批量梯度下降算法(Batch Gradient Descent, BGD)
- 随机梯度下降算法(Stochastic Gradient Descent, SGD)
- 小批量梯度下降算法(Mini Batch Gradient Descent, MBGD)
- 算法思想:每次迭代遍历数据集时,保存每组训练数据对应的梯度增量。遍历结束后,计算数据集的梯度增量之和,最后调整所有模型参数。显然,不断迭代优化后,BGD算法能收敛于全局最优解。BGD算法的伪代码如下:

- m为训练数据集规模、α为学习率、w为待优化参数、Δw为参数w的梯度增量。
- 优缺点:BGD算法虽然收敛于全局最优解,但是收敛速度缓慢,因此适用性不强。
随机梯度下降算法(SGD):
- 算法思想:在每次迭代训练中,首先将训练集随机打乱,依次遍历数据集中的每一组数据,利用数据对应的梯度增量来调整模型参数。也就是说,对于一个含有m组数据的数据集,在每次迭代训练中,必须调整模型参数m次。算法伪代码如下:

- 优缺点: 从SGD算法的思想上来看,SGD属于贪心算法。每次迭代训练过程中,SGD算法相比于BGD算法虽然频繁地调整参数,加快了收敛速度,但SGD算法也会存在偏差,每次迭代只用一组数据进行参数调整,而一组数据不能代表整体数据集地梯度方向,因此不可能都沿着全局最优解方向,故而陷入局部最优解。SGD理论上不能收敛到全局最优解,而在全局最优解地附近领域内震荡。
小批量梯度下降算法(MBGD):
- 算法思想: 每次迭代训练将数据集随机打乱,并划分为若干均等小样本,每次迭代训练地过程中遍历每个小样本,计算小批量样本地梯度增量平均值,并根据计算的平均值调整参数。算法伪代码如下:

- 优缺点:MBGD算法兼顾了BGD和SGD算法的优点,所以MBGD算法相比于BGD算法加快了收敛速度,相比于SGD算法降低了迭代训练中陷入局部最优解的风险。
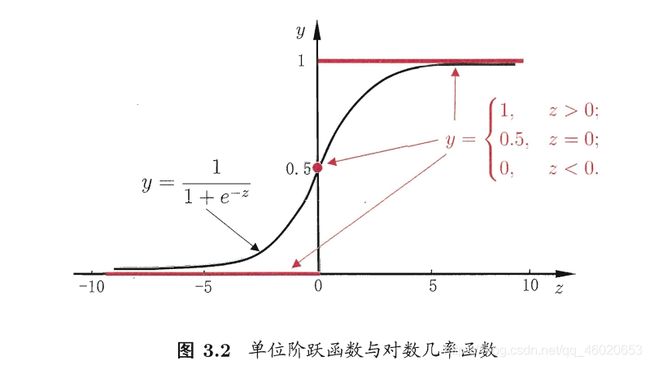
综合上述的三种算法,当损失函数为均方误差(MSE)时,可以得到一个统一的更新公式: y = g − 1 ( w t x + b ) y = g^{-1}(w^{t}x + b) y=g−1(wtx+b) 这样得到的模型称为"广义线性模型",其中g(·)称为“联系函数”。 虽然名称为对数几率回归,但是是用来解决分类问题的。 y = 1 1 + e − z y = \frac{1}{1 + e^{-z}} y=1+e−z1 y = 1 1 + e − z = > z = l n y 1 − y z = w T x + b = > y = 1 1 + e − ( w T x + b ) l n y 1 − y = w T x + b y = \frac{1}{1 + e^{-z}} \quad = >\quad z = ln\frac{y}{1-y}\\ z = w^Tx +b\quad=>\quad y=\frac{1}{1+e^{-(w^{T}x+b)}}\\ ln\frac{y}{1-y}=w^{T}x+b y=1+e−z1=>z=ln1−yyz=wTx+b=>y=1+e−(wTx+b)1ln1−yy=wTx+b 先来看看对数几率回归这种分类学习算法的优点:
w j = w j − α ξ ∑ i = 1 ξ Δ w j w_j= w_j- \frac{\alpha}{\xi}\sum^{\xi}_{i=1}\Delta w_j wj=wj−ξαi=1∑ξΔwj
公式中ξ为常数,Δw为参数w的梯度增量,m为数据集规模。当ξ=1时,对应的就是SGD;当ξ=m时,对应的就是BGD;当ξ=n(1

(三)广义线性模型(generalized linear model)
(四)对数几率回归(logistic regression/logit regression)

有关机器学习其他博客(下方为链接):