Spark 3.0 - 1.Spark 新特性简介与 WordCount Demo 实践
目录
一.引言
二.Spark 3.0 特性
1.Improving the Spark SQL engine [改进的SQL引擎]
1.1 Dynamic Partition Pruning [动态分区修剪]
1.2 ANSI SQL compliant [兼容 ANSI SQL]
1.3 Join hints [连接提示]
2.Enhancing the Python APIs: PySpark and Koalas [增强Python API:PySpark和Koalas]
3.Hydrogen, streaming and extensibility [性能与容错的支持]
3.1 Accelerator-aware scheduling [加速器感知调度]
3.2 New UI for structured streaming [结构化流媒体的新UI]
3.3 Observable metrics [可观察指标]
3.4 New catalog plug-in API [新的目录插件 API]
4.Other updates in Spark 3.0 [其他更新]
三.搭建 Spark 3.0 Maven 项目
1.创建 Maven 项目
2.添加 Scala SDK
3.添加 POM 依赖
4.创建文件与文件夹
四.Spark 3.0 WordCount Demo
1.数据文件
2.WordCount
五.总结
一.引言
Spark 2.x 作为大数据开发的主力版本已经使用多时,自 2020 年6月18日 Spark 3.x 发布以来,随着 Spark 3.x 的逐渐完善,开发者也应该熟悉 Spark 3.x 相关内容与特性。本文将主要介绍 Spark 3.0 的新特性并通过 Idea 创建一个 Maven 工程实现 Spark 3.0 x Scala 的 WordCount Demo。
二.Spark 3.0 特性
以下是Spark 3.0 中最大的新功能:
- 高效:通过自适应查询执行、动态分区修剪和其他优化,TPC-DS的性能比 Spark 2.4 提高了 2 倍
- 兼容:兼容 ANSI SQL
- 优化:Pandas API 的重大改进,包括 Python 类型提示和其他 Pandas UDF
- 异常处理:更好的 Python 异常处理,简化 PySpark 异常
- 全新UI:结构化流媒体的新 UI
- 协作:调用 R 用户定义函数的速度可提高40倍
- 全面优化:解决了3400多个 Jira<项目与事务> 问题

上图为新版本解决的问题在 Spark 项目中的占比,除此之外,使用 Spark 3.x 无需对代码进行过多修改,但在集群提交或编译时可能略有不同,实战环境下同学们需要注意。从图中也可以看出来,SQL 的优化占比最高达到 46%,因此 Spark 3.x 最大的优化就是 SQL 效率的优化。
1.Improving the Spark SQL engine [改进的SQL引擎]

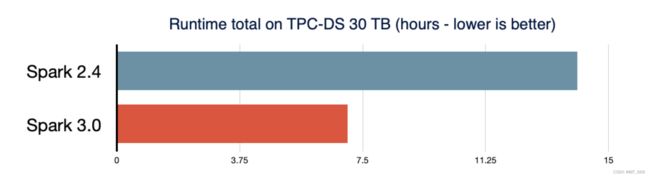
Spark SQL 是支持大多数 Spark 应用程序的引擎。例如,在 Databricks 上,我们发现 90% 以上的 Spark API 调用使用 DataFrame、Dataset 和 SQL API 以及 SQL 优化器优化的其他库。这意味着,即使是 Python 和 Scala 开发人员也会通过 Spark SQL 引擎来完成大部分工作。在Spark 3.0版本中,46% 的补丁都是针对 SQL 的,提高了性能和 ANSI 兼容性。如下图所示,Spark 3.0 在总运行时间上的表现大约是 Spark 2.4的两倍。接下来,我们将解释Spark SQL引擎中的四个新特性。
新的自适应查询执行(AQE)框架通过在运行时生成更好的执行计划来提高性能并简化优化,即使初始计划由于缺少 / 不准确的数据统计数据和错误估计的成本而不是最佳的。由于 Spark 中的存储和计算分离,数据到达可能是不可预测的。由于所有这些原因,Spark 的运行时适应性比传统系统更为关键。此版本引入了三种主要的自适应优化:
- Dynamically coalescing shuffle partitions [大小分区合并自适应]
动态合并混洗分区可以简化甚至避免调整混洗分区的数量。用户可以在开始时设置相对较多的shuffle分区,然后 AQE 可以在运行时将相邻的小分区合并为较大的分区。
- Dynamically switching join strategies [Join 连接优化自适应]
动态切换连接策略部分避免了由于缺少统计信息和/或大小估计错误而执行次优计划。这种自适应优化可以在运行时自动将排序合并联接转换为广播哈希联接,从而进一步简化优化并提高性能。
- Dynamically optimizing skew joins [数据倾斜感知自适应]
动态优化歪斜连接是另一个关键的性能增强,因为数据倾斜会导致工作的极度不平衡,并严重降低性能。AQE从 Shuffle 文件统计数据中检测到任何倾斜后,它可以将倾斜分区拆分为较小的分区,并将它们与另一侧的相应分区连接起来。这种优化可以并行化倾斜分区的处理并实现更好的总体性能。
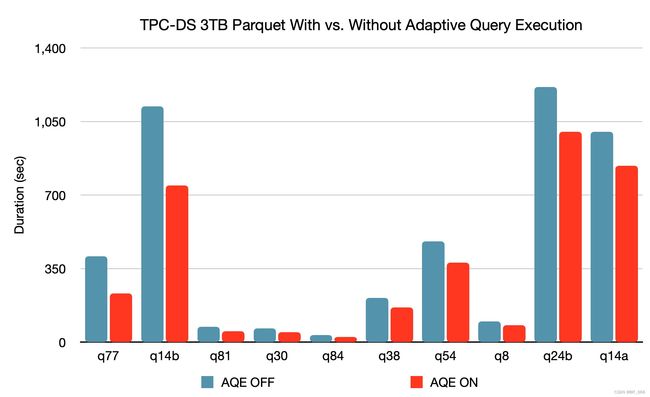
基于 3TB TPC-DS 基准测试,与没有 AQE 相比,使用 AQE 的 Spark 可以为两个查询提供 1.5 倍以上的性能加速,为另外 37 个查询提供 1.1 倍以上的加速。
Tips:
TPC-DS 是一套决策支持系统测试基准,主要针对零售行业。提供多个 SQL 查询,分析数据量大,测试数据与实际商业数据高度相似,其中 1TB、3TB 代表 TPC-DS 的标度因子,除此之外还有 10TB、30TB、100TB 的数据库规模用于进行有效性能测试。
1.1 Dynamic Partition Pruning [动态分区修剪]
当优化器无法在编译时识别它可以跳过的分区时,将应用动态分区修剪。这在星型模式中并不少见,星型模式由一个或多个引用任意数量维度表的事实表组成。在这样的联接操作中,我们可以通过识别筛选维度表所产生的分区来修剪联接从事实表中读取的分区。在 TPC-DS 基准测试中,102个查询中有 60 个查询的速度明显提高了2倍到18倍。

1.2 ANSI SQL compliant [兼容 ANSI SQL]
ANSI SQL 合规性对于从其他SQL引擎到 Spark SQL 的工作负载迁移至关重要。为了提高法规遵从性,此版本切换到 Proleptic Gregorian 日历,并允许用户禁止使用 ANSI SQL 的保留关键字作为标识符。此外,我们在数值操作中引入了运行时溢出检查,并在将数据插入具有预定义模式的表时引入了编译时类型强制。这些新的验证提高了数据质量。
Tips:
ANSI 即美国国家标准化组织是一个核准多种行业标准的组织。SQL 作为关系型数据库使用的标准语言,最初是基于 IBM 的实现 1986 年被批准的。1987年,国际标准化组织(ISO) 把ANSI SQL作为国际标准。这个标准在1992年进行了修订 (SQL-92),1999年再次修订 (SQL-99)。最新的是SQL-2011。我们可以理解 Spark 3.x SQL 符合行业标准。
1.3 Join hints [连接提示]
尽管我们继续改进编译器,但不能保证编译器在任何情况下都能做出最佳决策,联接算法的选择都是基于统计和启发式的。当编译器无法做出最佳选择时,用户可以使用联接提示来影响优化器选择更好的计划。此版本通过添加新的提示来扩展现有的连接提示:SHUFFLE_MERGE、SHUFFLE_HASH 和 SHUFFLE_REPLICATE_NL。
2.Enhancing the Python APIs: PySpark and Koalas [增强Python API:PySpark和Koalas]
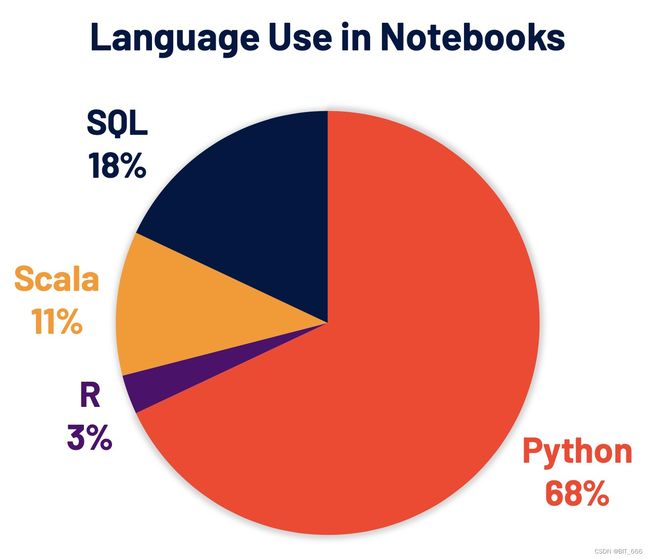
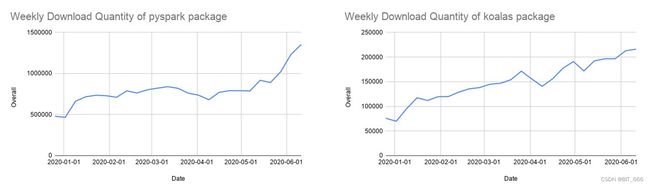
Python 现在是 Spark 上使用最广泛的语言,因此也是 Spark 3.0 开发的重点领域。Databricks 上68% 的笔记本命令使用 Python。Apache Spark Python API PySpark 在 PyPI(PythonPackage Index)上的月下载量超过500万,不过博主作为 Java 大数据开发工程师,日常使用中还是 Scala 居多,这个大家根据自己实际场景决定即可。
许多 Python 开发人员使用 Pandas API 进行数据结构和数据分析,但它仅限于单节点处理。我们还继续开发 Koalas,这是 Apache Spark 之上的 Pandas API 的实现,以使数据科学家在分布式环境中处理大数据时更高效。Koalas 消除了在 PySpark 中构建许多功能(例如,绘图支持)的需要,从而在集群中实现高效性能。
经过一年多的开发,Koalas API 对 Pandas API 的覆盖率接近 80%。Koalas 的每月 PyPI 下载量已迅速增长到 85 万,Koalas 正在以每两周发布一次的节奏快速发展。虽然 Koalas 可能是从单节点 Pandas 代码中迁移的最简单方法,但许多人仍然使用 PySpark API,这种 API 也越来越受欢迎。
Spark 3.0 为 PySpark API 带来了几个增强:
- New pandas APIs with type hints [带有类型提示的 Pandas API]
Pandas UDF 最初在 Spark 2.3 中引入,用于扩展 PySpark 中的用户定义函数,并将 Pandas API 集成到 PySpark 应用程序中。然而,当添加更多的 UDF 类型时,很难理解现有的接口。此版本引入了一个新的 pandas UDF接口,该接口利用 Python 类型提示来解决 pandas 的 UDF 类型激增问题。新界面变得更加 Pythonic 和可描述。
- New types of pandas UDFs and pandas function APIs [Pandas API 新类型]
此版本添加了两种新的 Pandas UDF 类型,系列迭代器到系列迭代者,多系列迭代尔到系列迭代器。它对于数据预取和昂贵的初始化非常有用。此外,还添加了两个新的 Pandas 函数API,map 和 co-grouped map。
- Better Error Handling [更好的异常处理]
PySpark 错误处理对 Python 用户并不总是友好的。此版本简化了 PySpark 异常,隐藏了不必要的 JVM 堆栈跟踪,并使其更具 Python 特性。
3.Hydrogen, streaming and extensibility [性能与容错的支持]
通过 Spark 3.0 完成了 Hydrogen 项目的关键组件,并引入了新的功能来改进流媒体和可扩展性。
3.1 Accelerator-aware scheduling [加速器感知调度]
Hydrogen 项目是 Spark 的一项重大计划,旨在更好地统一 Spark 上的深度学习和数据处理。GPU和其他加速器已广泛用于加速深度学习工作负载。为了使 Spark 充分利用目标平台上的硬件加速器,此版本增强了现有的调度器,使集群管理器能够感知加速器。用户可以在发现脚本的帮助下通过配置指定加速器。然后,用户可以调用新的 RDD API 来利用这些加速器。
Tips:
Spark 3.x 着重优化了 ML 机器学习大数据项目,而 RDD 对应的 MLLIb 项目后续的维护可能会越来越少。
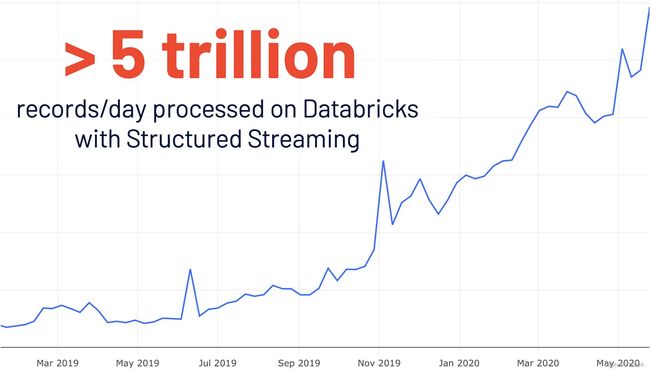
3.2 New UI for structured streaming [结构化流媒体的新UI]
结构化流媒体最初是在 Spark 2.0 中引入的。在 Databricks 上的使用量同比增长4倍后,使用结构化流媒体每天在 Databrick 上处理超过 5 万亿条记录。此版本添加了一个专用的新 Spark UI,用于检查这些流作业。这个新的UI提供了两组统计信息:1)已完成的流式查询作业的聚合信息和2)有关流式查询的详细统计信息。
3.3 Observable metrics [可观察指标]
持续监控数据质量的变化是管理数据管道的一个非常理想的特性。此版本引入了对批处理和流式应用程序的监控。可观测度量是可以在查询(DataFrame)上定义的任意聚合函数。一旦 DataFrame 的执行到达完成点(例如,完成批处理查询或到达流时代),就会发出一个命名事件,其中包含自上一个完成点以来处理的数据的度量。

上图为 Spark Streaming 流媒体指标。
3.4 New catalog plug-in API [新的目录插件 API]
新的目录插件API:现有的数据源API缺乏访问和操作外部数据源元数据的能力。此版本丰富了数据源V2 API,并引入了新的目录插件API。对于同时实现目录插件API和数据源V2 API的外部数据源,用户可以在注册相应的外部目录后,通过多部分标识符直接操作外部表的数据和元数据。
4.Other updates in Spark 3.0 [其他更新]
Spark 3.0 是社区的一个主要版本,解决了 3400 多个 Jira 问题。这是 440 多位贡献者的贡献,包括个人以及 Databricks、谷歌、微软、英特尔、IBM、阿里巴巴、Facebook、英伟达、Netflix、Adobe 等公司。本文强调了 Spark 中的一些关键 SQL、Python 和流媒体技术的进步,但在这个3.0 里程碑中还有许多其他功能没有在这里介绍。在发布说明中了解更多信息,并发现Spark的所有其他改进,包括数据源、生态系统、监控等。

Performance 性能优化 - 这里有我们熟悉的 AQE 自适应优化,Join 联结提示等等
Built-in Data Sources 内置数据源 - 常用的列式存储 Parquet、Orc 等等
Richer APIs 丰富的 API - 更多的内置函数提供,在实际使用中可以发现
SQL Compatibility 兼容性 - 更强的兼容性可以使得 Spark SQL 轻松高效的替代 HiveSql
Extensibility and Ecosystem 可扩展性与生态 - 新版 DataSource、Hadoop3、Hive 2/3、Java 11...
Monitoring and Debuggability 监控与调试 - 结构化 Streaming API、可视化统计指标...
三.搭建 Spark 3.0 Maven 项目
上面介绍了 Spark 3.0 的特性,除了 Scala 外,很多优化都基于 PySpark,下面的示例将基于 Idea + Spark 3.0.2 + Scala 2.12.10 介绍。
1.创建 Maven 项目
在 Idea 中选择 New -> Project 新建 Maven 项目:

2.添加 Scala SDK
新的 Maven 项目默认只能创建 java.class,所以需要引入 Scala SDK,通过 File -> Project Structure 选择添加:
A.添加 SDK

B.选择对应版本
传统 Spark 2.x 多见于使用 Scala 2.11.x,Spark 3.x 则使用 Scala 2.12.x 居多,这里选择 2.12.10

3.添加 POM 依赖
Spark 选择 3.0.2 版本,Scala 选择 2.12.10 版本,JAVA 选择 8,Spark Core、Sql、Mllib 均选择 2.12 系列。
4.0.0
org.example
sparkV3
1.0-SNAPSHOT
UTF-8
3.0.2
2.12.10
org.apache.spark
spark-sql_2.12
${spark.version}
provided
org.apache.spark
spark-mllib_2.12
${spark.version}
provided
org.apache.spark
spark-core_2.12
${spark.version}
provided
org.scala-lang
scala-library
${scala.version}
com.alibaba
fastjson
1.2.76
4.创建文件与文件夹
将 Java 目录 Rename 为 Scala,随后新建目录并创建 Scala Class 即完成 Spark 3.0 项目的创建。

四.Spark 3.0 WordCount Demo
WordCount 对于 Spark 就像是 HelloWordl 对于程序员一样,是 Spark 最基础最入门的示例。
1.数据文件
这里本地创建文件模拟几条逗号分隔的数据 test.txt:
flink,java,scala
spark,good,bad
spark,hadoop,flink
spark,hive,tensorflow
hbase,redis,spark2.WordCount
package org.example.Chap1
import org.apache.spark.internal.Logging
import org.apache.spark.sql.SparkSession
object WordCount extends Logging {
def main(args: Array[String]): Unit = {
val spark = SparkSession
.builder()
.master("local")
.appName("WordCount")
.getOrCreate()
spark.sparkContext.setLogLevel("error")
import spark.implicits._
// 读取为 Sql DataFrame 形式
val data = spark.read.text("~/sparkV3/src/main/scala/org/example/Chap1/test.txt")
data.as[String].rdd.flatMap(_.split(","))
.map((_, 1))
.reduceByKey(_ + _)
.collect()
.sortBy(-_._2)
.foreach(println(_))
}
}
SparkSession - Spark 会话,使用 read.text 读取文件后获得 sql.DataFram
as[String] - implict 隐式转换,将 Row 转换为 String
flatMap + map + reduceByKey - 累计数据
collect - 将结果下拉至本地
sortBy - 按照 count 频次降序排列
foreach + println - 遍历打印
上述操作都是 Spark 最基础的操作,与 Spark 2.x 差异很小,运行上述代码获取下述结果:

Tips:
A. import spark.implicits._
这里涉及到隐式转换,如果没有该引入,sql.DataFrame 的 Row 数据类型无法通过 as[String] 转换为 String 类型并进行后续的 split 操作。
B.Logging + setLogLevel
默认情况下,Spark 会打印很多 [info] 日志,影响运行结果的观察,可以继承 Logging 类并设置日志类型为 error 减少系统日志,下图为未设置 logLevel,日志数量非常多:

五.总结

上面简单介绍了 Spark 3.0 的特性以及如何通过 Idea 快速搭建一个 Spark 3.0 Demo 并运行,这些对于使用 2.x Spark 版本的同学来说十分轻松,因为二者差异很小,很多优化特性我们都是不感知的。后续将优先基于 Spark 3.0 + ML 介绍基于机器学习的大数据分析与挖掘,待该部分内容介绍完毕后讲解 Spark 3.x SQL 系列。
其中关于 Spark 3.0 特性的部分翻译自 www.databricks.com,参考链接:Introducing Apache Spark 3.0 - The Databricks Blog。