让图像恢复的baselines简单点 [2022ECCV】
让图像恢复的baselines简单点 [2022ECCV】
- 摘要
- 介绍
-
- 目标
- 贡献
- Baseline模型
-
- 块内复杂度比较
- 普通块 A Plain Block
- 激活 Activation
- 注意力机制
- Nonlinear Activation Free Network
-
- SimpleGate
- SCA(Simplified Channel Attention)
- 实验结果
题目:Simple Baselines for Image Restoration
单位:旷视
代码:https://github.com/megvii-research/NAFNet
论文:https://arxiv.org/abs/2204.0467
摘要
- 揭示了非线性激活函数,例如Sigmoid,ReLu,GELU,Softmax等是不必要的: 它们可以用乘法替换或删除
- 简化之前复杂的网络设计并计算成本更小,最终提出的模型只通过卷积、LayerNorm、通道注意力等结构的简单堆叠就可以在较少的计算量下成为SOTA。
- 提出了一个非线性无激活网络 NAFNet(Nonlinear Activation Free Network)
介绍
作者认为系统复杂度分解为两部分: 块间(inter-)复杂度和块内(intra-)复杂度,其中inter-block的复杂度是指网络的宏观结构,比如multi-stage, UNet等,文章就简单的选择了Unet为宏观结构,作者宏观结构不是影响效果的关键("We believe the architecture will not be a barrier to performance. ")
目标
作者的目标是使用块间低和块内复杂度低的网络实现SOTA
贡献
解释了GELU,GA和GLU的关系:
激活函数GELU和通道注意力GA都是门控线性单元GLU的特例,为降低计算量,作者用实验证明可以用特征图的哈达玛积来代替
Baseline模型
块内复杂度比较
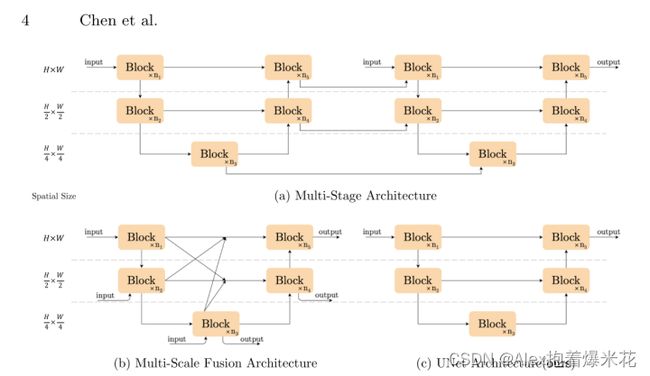
作者罗列了几种结构,很明显采用传统的U-Net模型最简单,作者认为结构不影响性能
块间复杂度比较
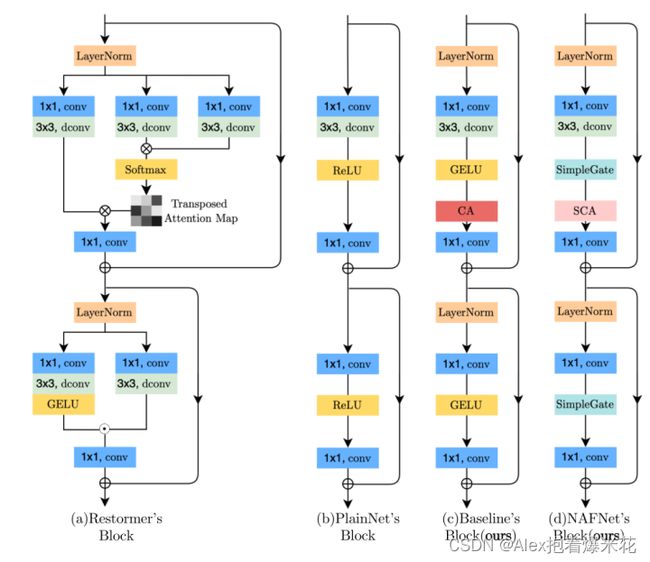
普通块 A Plain Block
首先,尽管transformers在计算机视觉方面表现出良好的性能,它们可能不是实现SOTA结果所必需的,有可能就是其中的一小步。其次,深度卷积比自注意机制更简单,能获得丰富的局部信息。
transformers在底层视觉的成功是得益于MSA本身还是与之配套的其他模块/结构/trick的效果是值得思考,这个文章告诉我们复杂或者简单(Restormer,PlainNet两个类似的结构)都可以实现SOTA
归一化 Normalization
文章采用了Transformer里被通常采用的LayerNorm,虽然学习率上会提高10倍+但是会让训练稳定!
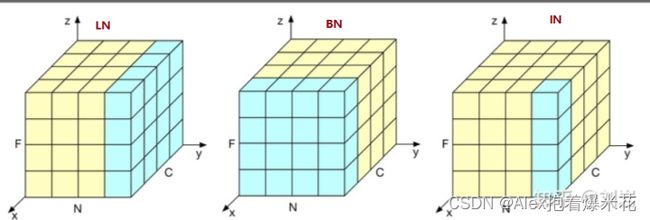
解释:
韩国团队在2017NTIRE图像超分辨率中取得了top1的成绩,主要原因竟是去掉了网络中的batchnorm层,由此可见,BN并不是适用图像恢复image-to-image的任务中,比如超分辨率上,因为我们这个领域的图像的绝对差异(具体来说就是增强细节)是非常重要的,所以batchnorm并不适合。底层视觉一般是不太会增加BN,因为在batch中进行统计很容易将其他图片的信息引入,忽略了恢复图像的特定信息,导致降点而且让图像模糊。之前底层视觉里面用的比较多的norm是instance Norm(比较多的是在风格迁移,近期恢复这边有HI-Net),instance Norm是对同一个样本的同一个通道所有元素做归一化,更适合对单个像素有更高要求的场景。LayerNorm是对同一个样本的不同通道做归一化,关注了整幅图。
激活 Activation
SOTA方法大都采用在普通块中用GELU代替ReLU
注意力机制
使用了简化的channel attention,减少计算量的同时引入channel的交互,避免了计算问题,同时在每个特征中保持全局信息。
从swin到restormer,其实tranformer的全局attention可能没有想象的那么重要,swin里切成window-based仍然可以保持很好的效果,restormer里面干脆放弃了spatial的MSA而使用深度卷积和传统的spatial attention,有可能CA对恢复任务更重要一些
Nonlinear Activation Free Network
SimpleGate
G a t e ( X , f , g , σ ) = f ( X ) ⊙ σ ( g ( X ) ) Gate(X,f,g,σ)=f(X)⊙σ(g(X)) Gate(X,f,g,σ)=f(X)⊙σ(g(X))
G E L U ( x ) = x Φ ( x ) GELU(x)=xΦ(x) GELU(x)=xΦ(x)
从公式可以注意到GELU是GLU的特例,即 f , g f,g f,g取恒等函数,并取 σ σ σ 为 Φ Φ Φ。
通过相似性,作者从另一个角度推测GLU可以被视为激活函数的推广,并且它可能能够替代非线性激活函数。
即使去除 σ σ σ, G a t e ( X ) = f ( X ) ⊙ g ( X ) Gate(X)=f(X)⊙g(X) Gate(X)=f(X)⊙g(X) 也包含非线性。基于这些,提出了一个简单的GLU变体: 在通道维度中直接将特征图分为两部分并将其相乘,称为SimpleGate
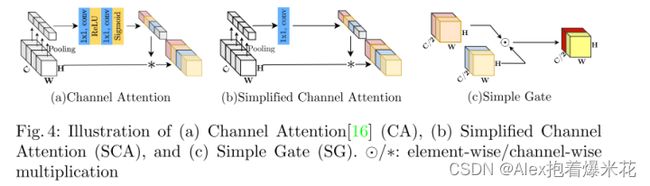
SCA(Simplified Channel Attention)
原本的CA的公式如下,
C A ( X ) = X ∗ σ ( W 2 m a x ( 0 , W 1 p o o l ( X ) ) ) CA(X)=X∗σ(W2max(0,W1pool(X))) CA(X)=X∗σ(W2max(0,W1pool(X)))
如果我们将通道注意计算视为一个函数,用输入 X X X记为 Ψ Ψ Ψ
C A ( X ) = X ∗ Ψ ( X ) CA(X)=X∗Ψ(X) CA(X)=X∗Ψ(X)
作者将CA也和GELU一样,视为GLU的特例
最终的结果是
S C A ( X ) = X ∗ W p o o l ( X ) SCA(X)=X∗Wpool(X) SCA(X)=X∗Wpool(X)
实验结果
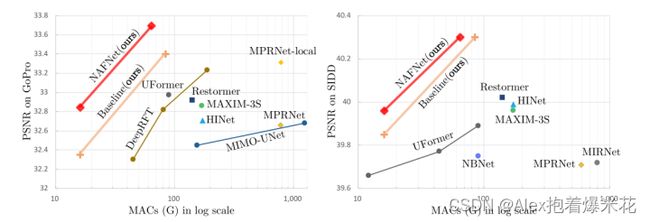
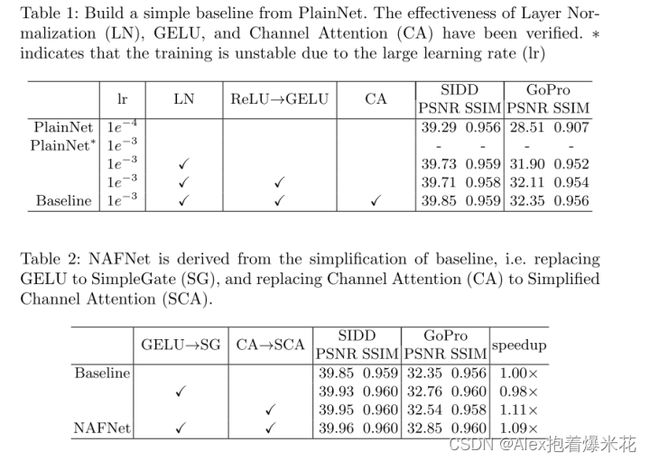
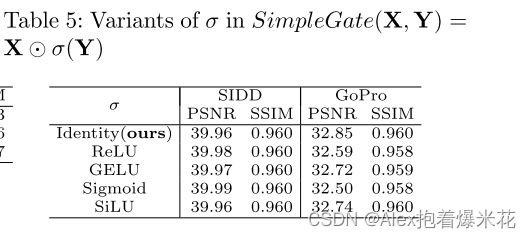
其他实验结果看论文,下面主要展示消融结果:
如果觉得对你有帮助的话:
点赞,你的认可是我创作的动力!
收藏,你的青睐是我努力的方向!
评论,你的意见是我进步的财富!