【ECCV22】【low-level】Simple Baselines for Image Restoration
Authors: Liangyu Chen*, Xiaojie Chu*, Xiangyu Zhang, and Jian Sun (MEGVII, China)
Link: [2204.04676] Simple Baselines for Image Restoration (arxiv.org)
Code: github.com/megvii-research/NAFNet
向孙剑老师致敬!
1 Intro
现在的SOTA模型都太复杂了,将他们分成两种复杂:inter-block complexity和intra-block complexity。
inter-block complexity:宏观上不同block之间互相连接,不同尺寸的feature进行交互;
intra-block complexity:block内的设计过于复杂
Motivation
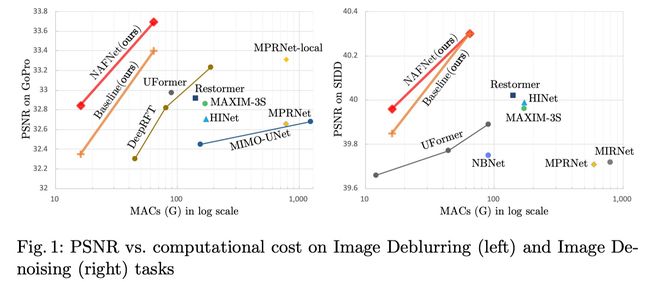
能否用简单的模型达到SOTA结果?
解析了SOTA模型,提取出了最基本的单元组成PlainNet;
提出的Baseline在denoising和deblurring上达到了SOTA;
分析了Baseline,发现许多结构可以被化简或移除,由此提出了一个不含非线性激活函数的网络NAFNet。虽然被简化了,但是效果提高了。
2 Realated Works
Image Restoration
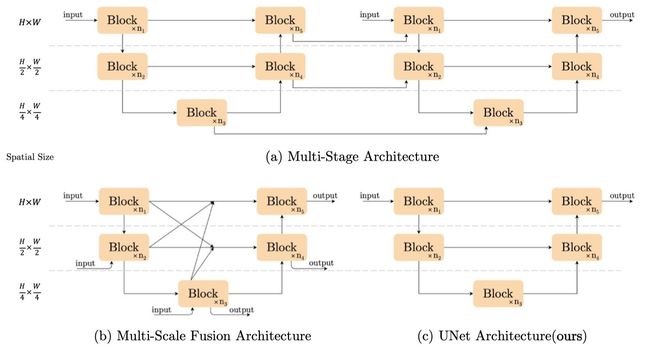
当前Image Restoration任务大部分SOTA模型都是基于UNet结构。
Inter-block Complexity
宏观网络结果,许多是多阶段网络,course to fine;
单阶段的网络要么在不同尺寸的feature map之间连接,要么在intra-block很复杂
Intra-block Complexity
微观结构,各种各样的魔改Attention,以及Gated Linear Units和Depth Conv的应用,使得block内的结构很臃肿。
3 Bulid A Simple Baseline
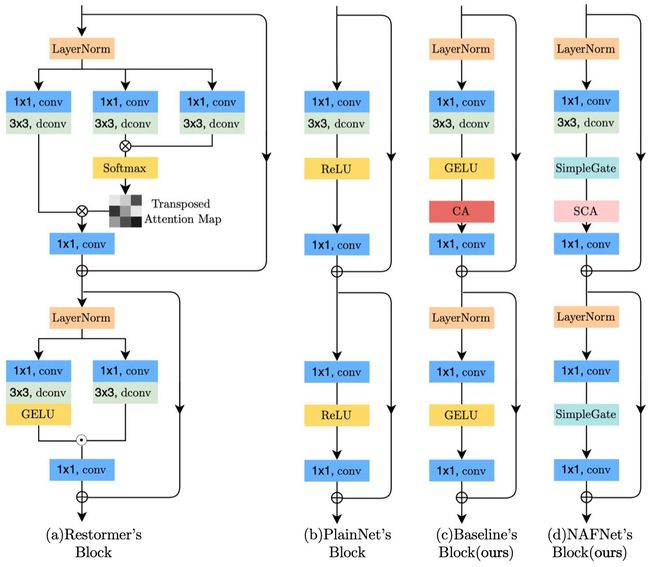
从0构建一个以简单为主的baseline,从现在的SOTA模型中汲取灵感,只使用了简单的component进行模型搭建:LayerNorm,Convolution,GELE,Channel Attention(CA),却以很小的计算复杂度超过了之前的SOTA,取名Baseline。
3.1 Architecture
为了减小inter-block complexity,使用单阶段的UNet架构。
3.2 A Plain Block
先从最常见的component中挑选,使用convolution、ReLU、short cut进行堆叠,称为PlainNet。
使用CNN而不是Transformer是因为:
1、尽管Transformer在CV中的效果很好,但是一些工作也证明这不是好效果的必须;
2、depth-conv比self-attention简单;
3、本文不是来讨论CNN和Transformer谁好,只是提供一个简单的baseline
3.3 Normalization
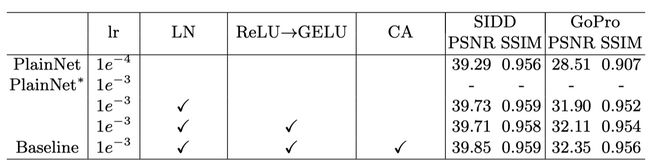
SOTA方法中都是用的LayerNorm,故我们推断LayerNorm对结果很重要,所以添加了LayerNorm至PlainNet。
这一改动使得训练更加平滑,即使Learning Rate增大了10倍。
+0.44 dB (39.29 dB to 39.73 dB) on SIDD;
+3.39 dB (28.51 dB to 31.90 dB) on GoPro。
总结,添加LayerNorm因为它能使训练更加稳定。
3.4 Activation
目前有使用GELU取代ReLU的趋势,故也使用GELU。
39.73 dB to 39.71 dB on SIDD
31.90 dB to 32.11 dB on GoPro
总结,使用GELU代替ReLU,因为它能提高指标。
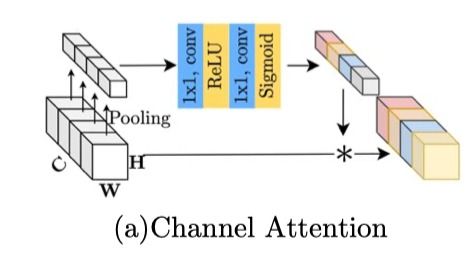
3.5 Attention
对于Attention的讨论是Transformer模型不可避免的。原始self-attention计算复杂度高,难以用于low-level场景。
故寻多模型遵循Swin,使用window-based attention,本文不使用这种,因为局部信息可以被Depth-Conv捕获。
还有模型(Restormer)使用channel-wise attention降低复杂度,同时还能保留global infomation。
故由此启发,SENet中的channel attention(CA)满足计算效率和保留全局信息这两个要求,且之前已有工作证明CA在image restoration中的有效性,故选择加入CA只PlainNet。
+0.14 dB (39.71 dB to 39.85 dB) on SIDD,
+0.24 dB (32.11 dB to 32.35 dB) on GoPro.
总结,添加Channel Attention(CA)
4 Nonlinear Activation Free Network
Baseline model已经简单且有效,能不能保持简单的同时再提高性能呢?
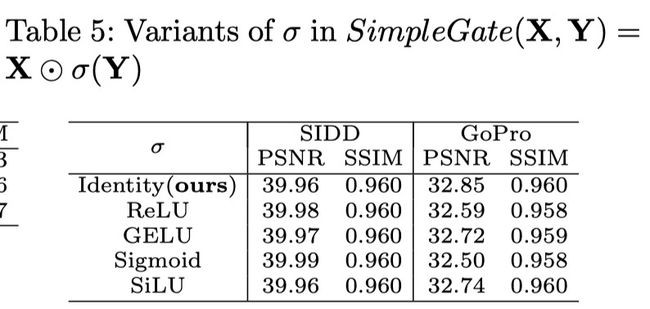
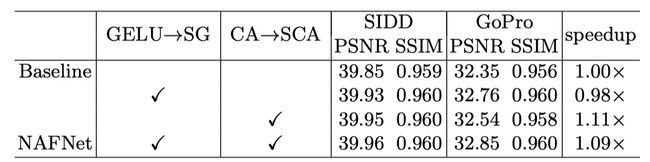
将GELU换为SimpleGate,CA换为SCA,变简单的同时效果提高了,且完全取消了非线性层,故取名Nonlinear Activation Free Network (NAFNet)
从SOTA模型的相同点中寻找思路,发现Gated Linear Units(GLU)被使用。

4.1 Gated Linear Units(GLU)
GLU可以被表示为
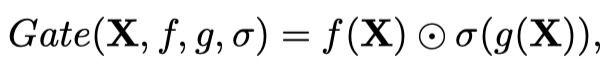
f f f 和 g g g 是线性变换, σ σ σ是非线性激活函数,如sigmoid。
将GLU直接加入baseline能增加性能,但同时增加了计算量,这不是我们所期望的。
重新观察GELU:
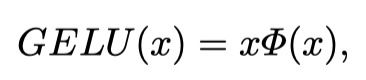
从GLU和GELU的形式上可以发现,GELU是一种特殊的GLU,也就是 f f f 和 g g g 是identity function,将 σ σ σ 换为 φ φ φ 。
还发现即使去除 σ σ σ ,即
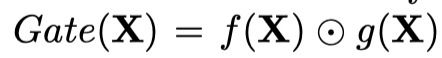
也包含非线性。
基于此,提出GLU变体SimpleGate,将feature map在通道维度分成两份,然后进行相乘:
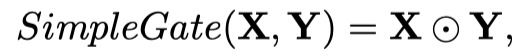
通过将GELU变为SimpleGate,
Denoising +0.08 dB (39.85 dB to 39.93 dB) on SIDD;
Deblurring +0.41 dB (32.35 dB to 32.76 dB) on GoPro.
4.2 Simplified Channel Attention
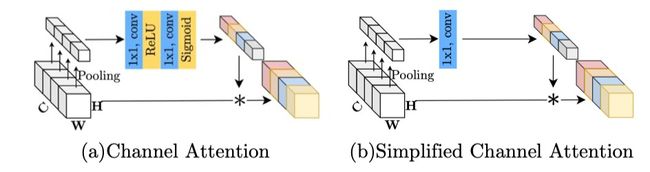
Channel Attention(CA)的
可以表示为:
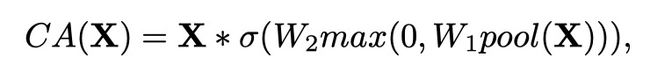
如果将CA表示成函数,发现形式很像GLU,于是可以沿用该思路进行简化:
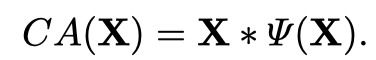
为了保留CA最重要的两个作用:整合全局信息和进行通道间的交互,提出Simplified Channel Attention(SCA):
![]()
将CA变为SCA,虽然简单了,但是效果更好了。
Denoising +0.03 dB (39.93 dB to 39.96 dB) on SIDD;
Deblurring +0.09 dB (32.76 dB to 32.85 dB) on GoPro.
5 Experiments
TASKS:
RGB image denoising
image deblurring
raw image denoising
image deblurring with JPEG artifacts
5.1 Ablations
Inference时使用了TLC,比较了TLC与”Test by patches“,还用了skip-init去稳定训练。
5.1.1 From PlainNet to the simple baseline
5.1.2 From the simple baseline to NAFNet
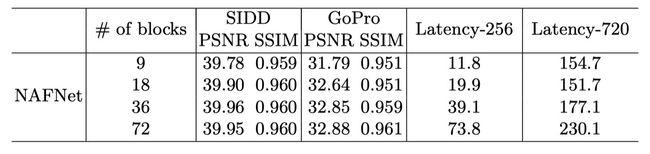
5.1.3 Number of blocks
36 blocks default for performance/latency balance
5.1.4 Variants of σ σ σ in SimpleGate