基于YOLOv3的口罩佩戴检测
摘 要
为解决市民口罩佩戴目标检测中因小尺寸目标较多导致其识别精度不高的问题,提出一种基于 YOLOv3改进的算法 M_YOLOv3。重构特征金字塔机制,把原本3*3的类金字塔结构扩建为4*4尺寸,把先验框数量由9增加到16,通过 以上方法降低神经网络感受野,增强 M_YOLOv3对小尺寸目标的敏感度。将原有的损失函数IoU 替 换 为 DIoU ,解决边框回归时难以确认梯度下降方向的问题。基于网络公开的4065张口罩数据集的实验结果表明,M_YOLOv3的 mAP(平均精 度均值)为88.4,较 Tiny_YOLOv3和 YOLOv3的 mAP分别提升了15.9和7.2。
关键词 目标检测;YOLOv3;口罩佩戴检测;特征金字塔;卷积神经网络
引言
2020年,新冠肺炎肆虐全球,正确佩戴口罩是阻止病毒在人与人之间相互传播的重要举措。通用算法几乎都能运用于口罩佩戴检测[1],但像 人员遮挡、目标对象较小、密集人群等问题,通用算法检测出来的效果并不是十分理想。为了解决这些问题,研究者们进行了大量的研究工作并取得了显著进展:Pang等[2]设计了基于掩码的空间注意 力机制模块,让模型更加关注于行人未被遮挡部分的特征; Liu等[3]将全卷积网络与可变性卷积思想相结合,为了增加模型特征编码的灵活性,采用了位置敏感的DCN [4]池化,让模型尽可能多地从行人可见的部分中学习相应特征,来预防其它物体的遮挡干扰。随着计算机视觉技术不断的发展,目标检测技术也在不断优化,大致分为两类:双步 (Two-Stage) 法和单步(One-Stage)法。相比而言,这两类算法也是相互对立的,双步法检测精度高,而单步法检测速度快。最经典的单步法有SSD[5] (singleshot multibox detector)、YOLO[6-9] (youonlylookonce)系列算法;双步法有R-CNN(region conventionalneuralnetwork)系列算法。考虑到在实际监控下的人员检测任务中需要达到一种能实时检测的状态,而YOLO系列网络在检测速度方面可以保证实时性,其中第3代版本 YOLOV3同时兼顾了检测的时间和精度,相比其 它更高的版本,YOLOV3有着更成熟、更稳定的技术,所以本文在通用的目标检测算法 YOLOV3的基础上,对该算法进行改进,希望得到更好的检测效果。
1 YOLOV3算法原理
YOLOV3是Redmon 等提出的,主要由骨干网络Darknet-53和YOLO检测层组成,Darknet-53结构主要作 用是提取图像的特征信息,YOLO 层是用来预测其类别和 位置信息。该算法的骨干网络结构如图1所示。YOLOV3 算法有明显的两大优势:第一大优势是采用了以Darknet53 [10]网络作为主干特征提取网络,并结合了 ResNet残差 网络结构的思想[11]。卷积层主要包括两类滤波器,分别是 1×1和3×3,前一种滤波器是用于压缩特征,后一种滤波 器的作用主要是通过减少宽度和高度,来扩展通道的数量。这种结构的最大特点之一就是能通过增加相应的深度来提 高准确率,但是也会在训练模型中发生梯度爆炸以及梯度 消失的问 题,YOLOV3 算法内部的残差块使用了跳跃连接,促进了多个不同特征的融合学习。

图1 YOLOV3主要网络结构
针对尺寸不同的检测图像,YOLOV3算法运用了13×13, 26×26,52×52尺度的特征图实行检测[12],由于每个尺度 的感受野都各不相同,检测图像的大小也有所区分,尺度 越小的反而检测大的图像,即13×13检测大尺寸图像,而 52×52检测小尺寸图像,26×26检测中等图像。对于每个 尺度分支来说,在每个网格中会检测出3个结果,这是因 为每个 尺 度 下 会 有 3 个 先 验 框 (anchorbox), 是 根 据 K-Means聚类生成的。最后将3次检测的结果整合使用非 极大 值 抑 制 (non-maximumsuppression,NMS),获 得 结 果。举例来说,输入一张需要检测的图像,刚开始将其划 分为S×S的网格,需要预测C 个类别,则最终3个规模获 得的张量是S×S× [3× (5+C)],其中包含了目标边框的 4个偏移坐标和置信度得分,因而增强了对小尺度对象的 检测能力。这也是 YOLOV3算法与其它算法相比的另一大 优势。但是直接应用于自然场合下的口罩佩戴检测任务还 是有一些不足。其一,YOLOV3虽然在小目标的检测精度 上有一定的提升,但同时也出现了浅层特征提取不充分的 问题;其二,YOLOV3预测的准确性是使用IoU (intersectionoverunion)损失函数来判定预测框的好坏,但当IoU 的值增大时,检测的精确率会有所下降;其三,对于自然 场景下被遮住、密集人群以及小尺度的目标检测 等 问 题, YOLOV3仍有不足的地方。针对以上问题,本文为了提升 口罩在自然环境下的目标检测算法的准确率,以 YOLOV3 算法为基础进行了改进和优化。
2 改进的YOLOv3算法
本文对 YOLOV3的改进主要包括3个方面,分别是对主网络结构、特征增强网络和IoU 损失函数的改进。
2.1 特征提取网络Darknet_D
Darknet_3作为YOLOv3的特征提取网络,在 原 算 法 中把图片信息进行特征提取后传递给检测器进行边框回归运算,且经原 作 者 RedmonJ实 验 证 明,Darknet53在 性 能 和效率上较 早 期 Darknet系列的网络都有显著提升[1]。由 于 M_YOLOv3会增添一个预测通道,若在浅层网络直接添 加此通道进行 预 测,因 卷 积 层 较 少,此时的特征图并无 有 效的语义信息,在此基础上进行预测几乎没有任何参考价 值。故 M_YOLOv3提 出 了 Darknet_D 网 络,它 是 于 Dark- net53的基础上,在其尾部增添了一个残差结构的特征提取 网络。改进后的类特征金字塔使用残差结构3、4、5、6处 理后的特征图来进行多尺度预测,如图3所示。

图3 M_YOLOv3的特征提取网络
2.2 类特征金字塔改造
YOLOv3算法原使用的是3*3结构的类特征金字塔结 构,对应9个 尺 寸 的 边 框。原 理 是 通 过 Darknet53的 3层 Res_body结 构 (其 全 称 为 Resblock_body)类 似 残 差 网 络 的相加原理把各个特征图进行叠加,并 且 因 此 得 出3个 尺 寸的预测输 出 Y。改 进 算 法 M_YOLOv3算法将其改造为 4*4 的类特征金子塔结构,不仅层次更加分明,对不同尺寸更加敏感,且在每一个类特征金字塔输出层额外增加一 个预测候选边框供其使用,则输出的预测值 Y 会更加准确。 此外,在残差结 构 Resblock_body中,M_YOLOv3保 留了 YOLOv3的 DBL结构但对其进行参数修改,这种集卷 积、归一化、激活函数于一体的网络模块,能 够 很 好 保 留 图像信息并进行特征提取。 经过特征金字塔处理后的数据,模型把它打包成4个 Y 值,每一 个 Y 值 由4个’anchor结 构’组 成,每 一 个’anchor 结构’又包含此预测值的中心坐标x、y,偏移值和预测边 框的宽高 w、h,及 其 预 测 类 别classes和 置 信 度score,如 图4所示。
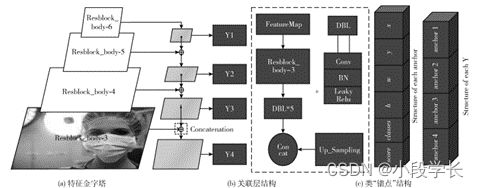
图4 改进后的类似特征金字塔结构
2.3 先验边框数量增加
原YOLOv3算法一共有9个 先 验 边 框,并 且 用 这9个 不同大小 的 边 框 分 成 3 组,对 不 同 尺 度 的 3 个 特 征 图 进 行预测。
本次实验数据的目标物体尺寸差别较大,某 些 口 罩 的 像素小于64*64px,某些口罩的像素大于512*512px。这 些过大的尺寸差别导致原 YOLOv3算法在口罩数据集上表 现欠佳。改进算法 M_YOLOv3使 用 了16个预测边框作为 候选框。其中每4个候选框对应一个特征图,每 个 特 征 图 使用4个候选边 框 进 行 预 测。故增加先验边框数量这一做 法,能 更 好 适 应 数 据,提 高 算 法 识 别 精 度,并 增 强 其 泛 化能力。
2.4 交并比损失函数替换

IoU (intersectionoverunion) 的 中 文 名 称 是 “交 并 比”,即为预测边框和真实边框的交集,与两个框的并集之 比,在诸多基于深度学习的目标检测算法中,IoU 都 是 一 项重要的区域计 算 指 标,如 式 (1)所 示,其 中 B 和Bgt 分 别代表预测框和真实框的面积。
YOLOv3使用1和IoU 的差值进行梯度回归,使 用 该 损失函数能够简单有效地收敛训练网络损失值,如 式 (2) 所示。但此损失函数在特定情况下无法正常使用,例 如 真 实边框和预测边框出现无交集的情况,无 论 边 框 远 近,此 时 LIoU都恒等于1,那么预测边框和真实边框的远近就没有 意义。在这种情况下算法无法判定两个边框的好坏以及损 失值收敛的方向,如图5所示


图5 边框无交集情况
针对这个问题,Rezatofighi H提出了〖G_IoU〗^([10])理念,在原来的损失函数加上了惩罚项,出现边框无交集情况时,两个边框距离越远损失值越大,如式(3)所示。

式中:C是两个边框的最小外接矩形,在此情况下,出现边框之间无交集情况时,也能判断距离的远近,并因此找到下降梯度。
G_IoU也无法适用于所有情况,若两个边框存在包含关系,如一大一小两边框A和B,小边框A 面积和B面积的并集等于A的面积,即B^A ⋃▒〖BB=BA 〗。则在任意包含情况下Loss值始终相等,这就和 上 述L_IoU出现的问题相似,算法无法找到损失值下降方向,如图6所示。

图6 边框存在包含关系
D_IoU是zhengzhaohui等^([12])在G_IoU的基础上进行了改 进从而推论出的另一种交并比损失函数
![]()
式中:d表示两个边框中心点的欧氏距离。c是最小外接矩形的对角线距离。它的计算方式和G_IoU类 似,也是在原IoU损失函数的基础上加上了惩罚项。不同的是G_IoU的惩罚项更为合理,能够解决边框出现包含情况时难以找到回归梯度的问题,如图7所示。

图7 DIoU边框
D_IoU同样也能提供预测边框的移动方向。但若出现两框包含的情况,G_IoU无法适应,而D_IoU不仅能找到预测框移动的方向,并且损失函数收敛十分迅速。
在上述提到的IoU损失函数,其作用都是辅助最终Loss收敛,更合理的IoU损失函数能够使算法更好地拟合数据。
在M_YOLOv3算法中使用D_IoU来替换原有的 L_IoU作为损失函数,在此基础上进行预测框和真实框的交并比计算,经实验验证有更好的检测效果。
2.5 比例系数的增大
在YOLOv3算法中,训练网络的损失函数实际上是由中心点损失、宽高损失、分类损失和置信度损失,这个损失值相加得出,如式(5)所示
Loss=L_xy+L_wh+L_c+L_s (5)
2.4节提到的D_IoU损失函数会改进L_xy和L_wh的 计 算,使这两个损失值的计算更加合理。由于YOLOv3是多尺度 检 测,在损失值收敛时会把每个边框都计算一次。那么宽高较 大 的 边框Lxy和 Lwh的值会偏高,对总体的 Loss值产生了错误的影响。
为了解决这个问题,原作者提出了比例系数box_loss_ scale这一指标,它是由数字2和偏移值 w 和h 的乘积做差 值计算得出,其中 w 和h 是0到1之间的ground_truth宽 高偏移值,如式 (6)所示。在Lxy和Lwh计算的最后一步都会进行比例系 数 放 缩,增加小尺寸边框的影响权重,进而减小因先验框尺寸不同而导致的无意义影响
2.6 损失函数的加权修正
如式 (5)所示,总 Loss值由4个独立 的Loss相加而得。因 M_YOLOv3使用了DIoU 且增大了比例系数,在式(5)中等号右边4个相加项除 Lc外都进行了加权计算。为平衡4个损失值的影响权重,M_YOLOv3 在 最 终 Loss 计算时,把 分 类 损 失 值 Lc 进行了加权计算, 如式(8)所示
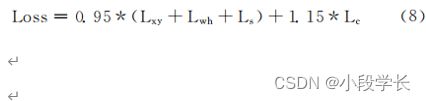
3 实验结果及分析
3.1 实验数据准备
3.1.1数据集介绍
本次实验选用公开口罩数据集1,该数据集来自网络,由labelimg软件标注。按照300px为界限把输入图片分为,小尺寸、中尺 寸、大 尺 寸、超 大 尺 寸 (长宽任意属性大于900px),分别 有 658 张、1557 张、566 张、134 张,未 注 明大小有1150张,共计4065张图片。本数据集与 VOC2007数据集格式一致,每一条数据都采用图片与其相对应的 xml相 结 合。每一张图片对应一个xml文件,记录图片上目标物体的各种属性,如目标物体在图片的中心点、标记框的宽高、目标物体的类别等信息。本次数据集中只有两个类,”face_mask”和”face”。在上述的目标物体的属性中,目标物体标记框的长和宽显得 尤 为 重 要,它们可以表示目标物体的尺寸。因 YOLOv3原版算法 的 实 验 是 在 VOC2007数据集上进行的,而本次实验的数据是检测人脸和口罩,与VOC2007数据集相比则目标尺寸普遍偏小。故在此把本次数据集和VOC2007数据集的目标物尺寸作比较,按照单边64、128、256、512为界限进行尺寸大小归类,见表1。

由此可见,本次数据集的分布更加广泛和细致,且小目标尺寸偏多。改进算法提出的4层金字塔结构,并将 anchors 数目从9 增 加 到16的做法, 在理论上支持 M_YOLOv3 能得出更好的识别效果。
3.1.2 数据增强
在深度学习理论中,训练数据越充足,训练模型的效果越好。由于本次实验数据仅4000余张图片并不充足,使用数据增强手段来模拟更多数据样本就具有很强的必要性。不但能使算法模型有更多的学习样本,同时也因数据增强增加了噪声,减少模型过拟合的现象。
在本次实验中,使用了缩放图片、平移变换、翻转、颜色抖动 (RGB->HSV->RGB)以及boxes的重定位等数据增强手段,确保本次实验数据充足,增强模型的泛化能力,提高算法鲁棒性。
3.2 训练模型的过程
为得到合适的先验框大小,最常用的手段就是对标记数据进行聚类。在诸多聚类方法中,在事先设定好簇的个数条件下,K-Means无疑成为了首选方案。
K-Means算法思路非常直观,初始人为设定常数K,K代表算法最终划分出来的类别数量值。算法会随机选定初始点为质心,并通过计算每一个样本与质心之间的相似度(一般使用欧氏距离),将样本点分类到最相似的一个簇中,接着,重新计算每个簇的质心(即为簇 心),重复这样的过程,直到簇心不再改变,最终就确定了每个样本所属的簇以及簇心。 M_YOLOv3使用了 簇数量为16的 K-Means算法进行聚类。得到的16组anchors后又进行了类似归一化的处理,最终 得 出 anchors尺 寸 如 下:(23,23),(35,34),(44,44), (53,54),(65,63),(76,75),(89,91),(108,105),(121,123),(142,142),(164,175),(167,158),(190,190),(215,212), (253,254),(372,362)。括号中的两个值 (width,hight)分 别代表anchor的宽和高。
考虑到本次实验的硬件条件,输入图片尺寸统一resize为352*352,初始学习率设置为 0.001,在回调过程中使用监视val_loss变化的方法来减小学习率,其 中 的参数设置为 patience=6,factor=0.4。总 训 练 批 次 epoch= 800,batch_size=10,训 练 网 络 Loss值的收敛情况如图8所示。

图8 Loss收敛
3.3 评价指标及实验结果
3.3.1 对于小目标的识别效果
在对输入图片进行检测的时候,一张图片往往包括很多个目标,就容易发生漏检的情况,尤其是小尺寸目标物的漏检情况更为常见,如图9所示(文本框较长的矩形框 代表 “口罩”,文本框较短的矩形框代表 “人脸”)。 图9中 YOLOv3算法和 Tiny_YOLOv3算法发生了漏检情况,而M_YOLOv3凭借多种改进措施,对小目标物更为 敏感,不容易发生漏检情况。实验结果表明,改进后的算法,一定程度上改善了对小目标物体识别困难的问题,如图9所示。

图9 3种算法检测效果对比
3.3.2 困难条件下的识别效果
在实验中,3种检测算法对于多数图片的检测效果比较良好,错误主要发生 在混淆和遮挡的数据上。如 图10 中,第一排图片的口罩和人脸颜色非常接近,只有M_ YOLOv3算法 判 定 正 确(文本框较长的矩形框代表 “口罩”,文本框较短的矩形框代表 “人脸”);第二排图片则是纸折扇遮挡面目,其形状颜色大小都与口罩十分类似,所有算法的识别结果均错误。
3.3.3 mAP评价指标
目标 检测领域使用的评价指标主要是 mAP(mean averageprecision),平均精度均值,即为AP的平均值。而AP则是通过式 (9)得出,本质上是选取0.1作为γ的间隔,把每个γ 对 应 的 Pinterp值相加,最后取均值。其中Pinterp是 PR曲线中,以召回率(recall)作为横坐标点,曲线所对应的纵坐标值,如式(10)所示(在计算过程 中,若横坐标x1无对应的纵坐标值,则使用最靠近两点 x2、x3所对应曲线上的点,做延长线与x=x1直线相交,交点即为x1对应纵坐标值)

图11是类别”face”对应的P-R曲线,在图中可得出M_YOLOv3的PR曲线略优于未改动的算 法。本次实验总共有两 个 类,”face_mask”类 和”face”类。mAP值就是对两个类的AP值求和取平均。
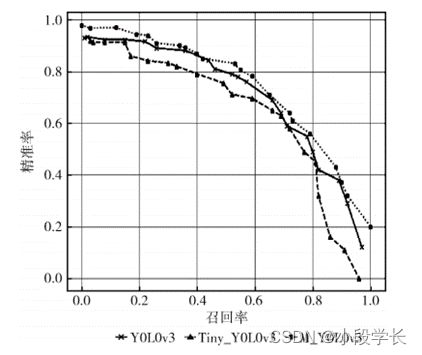
图11 “face”类别 P-R曲线
3.3.4 实验结果
经实验得出,M _YOLOv3算法对比原版Tiny_ YOLOv3和 YOLOv3算法在 mAP值上分别提升了15.9和7.2,检测能力优于原版算法。M_YOLOv3的fps值为24,能够在一定程度上做到实时检测口罩佩戴情况见表2。

4 结束语
改进算法M_YOLOv3算法在YOLOv3的基础上加深特征提取网络并增添预测通道,且使用了更合理的损失函数,改善了YOLOv3算法对小尺寸目标识别困难的问题,适用于小目标物体的检测。在基于小尺寸目标偏多的口罩数据集实验中得出结论,mAP指数相较于原版 YOLOv3提升了7.2。在实验中,部分数据迷惑性极强,例如图10中女性用纸折扇遮挡口部,文中几个算法都全部错误判定它是口罩。针对这个问题,暂时 无法解决,值得下一步去思考并寻找答案,或许使用类似DOTA 数据集四点坐标的数据格式会 改善这一问题。除 YOLOv3算法外,其它目标检测算法也百家争鸣。作为学者应该紧随时代脚 步,不断地学习理解其它的目标检测算法及其网络结构,如单阶段的RetinaNet[13]、
YOLOv4,双阶段的 DCR、SNIP[14]、SNIPER等。
参考文献:
[1]NIUZuodong,QINTao,LIHandong,etal.Improvedalgo-
rithmofretinafacefornaturalscenemaskweardetection [J].
ComputerEngineeringandApplications,2020,56 (12):1-7
(inChinese). [牛作东,覃涛,李捍东,等.改进 RetinaFace
的自然场 景 口 罩 佩 戴 检 测 算 法 [J]. 计 算 机 工 程 与 应 用,
2020,56 (12):1-7.]
[2]PangY,XieJ,HarisKhan M,etal.Mask-guidedattention
networkforoccludedpedestriandetection [C]//IEEE/CVF
InternationalConferenceon Computer Vision.arXiv,2019:
4967-4975.
[3]Liu T,Luo W, Ma L,etal.Couplednetworkforrobust
pedestriandetection with gated multi-layerfeatureextraction
anddeformableocclusionhandling [J].IEEE Transactionson
ImageProcessing,2020,30:1.
[4]ZhuX,HuH,LinS,etal.DeformableConvNetsV2:More
deformable,betterresults [C]//IEEE/CVF Conferenceon
ComputerVisionandPatternRecognition.IEEE,2019:9308-
9316.
[5]LiuW,AnguelovD,ErhanD,etal.SSD:Singleshotmulti-
boxdetector [C]//EuropeanConferenceonComputerVision.
SpringerInternationalPublishing,2016:21-37.
[6]RedmonJ,DivvalaS,GirshickR,etal.Youonlylookonce:
Unified,real-timeobjectdetection [C]//ComputerVision &
PatternRecognition.IEEE,2016:779-788.
[7]RedmonJ,FarhadiA.YOLO9000:Better,faster,stronger
[C]//IEEEConferenceonComputerVision& PatternRecog-
nition.IEEE,2017:6517-6525.
[8]REDMON J, FARHADI A. YOLOV3: An incremental
improvement [C]//ProceedingsofIEEEConferenceonCom-
puter Vision and Pattern Recognition.Washington:IEEE
Press,2018:1-6.
[9]BochkovskiyA, Wang CY,Liao HYM.YOLOv4:Optimal
speedandaccuracyofobjectdetection [J].arXiv:2004.10934,
2020.
[10]WangY,ZhengJC.Real-timefacedetectionbasedonYOLO
[C]//IEEEInternationalConferenceon KnowledgeInnova-
tionandInvention,2018:221-224.
欢迎大家加我微信交流讨论(请备注csdn上添加)
