【语音信号处理】1语音信号可视化——时域、频域、语谱图、MFCC详细思路与计算、差分
基本语音信号处理操作入门
- 1. 数据获取
- 2. 语音信号可视化
-
- 2.1 时域特征
- 2.2 频域特征
- 2.3 语谱图
- 3. 倒谱分析
- 4. 梅尔系数
-
- 4.1 梅尔频率倒谱系数
- 4.2 Mel滤波器原理
- 4.3 MFCC特征提取思路
- 4.4 计算Mel filterbank
- 4.5 代码实现
-
- 4.5.1 通过python_speech_features提取mfcc
- 4.5.2 通过librosa提取mfcc
- 5. 差分
- 6. 完整代码
- 小结
1. 数据获取
数据集来自:
- 中国科学院自动化所的CASIA汉语情感语料库——共包括四个专业最佳人,六种情绪生气(怒),高兴(高兴) ),害怕(fear),悲伤(sad),其他(surprise)和中性(neutral),共9600句不同最佳。其中300句是相同文本的,也就是说对相同的文本赋以不同的情感来阅读,这些语料可以利用对比分析不同的情感状态下的声学和韵律表现;另外100句是不同文本的,这些文本从字面意思就可以修剪其情感归属,以便录音人更准确地表现出情感,但完整的CASIA数据集是收费的,因此只找到了1200句残缺数据集,压缩包共58.2MB
- 好未来 TAL_SER语音情感数据集——该数据集为好未来老师上课音频,共包含4541条音频,总时长12.5小时。录音在安静的室内环境中录制,每条音频只有一个说话人。标注包括愉悦度(Pleasure)和激情度(Arousal)两个维度,每个音频片段对应一个P值和A值,范围都在[-3,3]之间,值越大表示愉悦度或激情度越高。音频长度:10s,采样率:16kHz
- 一个多模态英文数据集,在此申请获得许可,《Multimodal Language Analysis in the Wild_ CMU-MOSEI Dataset and Interpretable Dynamic Fusion Graph》数据集下载地址
- 《CH-SIMS: A Chinese Multimodal Sentiment Analysis Dataset with Fine-grained Annotations of Modality》–【中文多模态情绪】,Github地址,论文地址
2. 语音信号可视化
参考Python语音信号处理一文,MFCC特征提取与神经网络可见此文:基于CNN+MFCC的语音情感识别,以及有个专栏,其中有很多关于语音信号处理基础的Blog,还有这个Speech Recognition 专栏
2.1 时域特征
使用wave模块读取wav音频文件,画图时域图像:
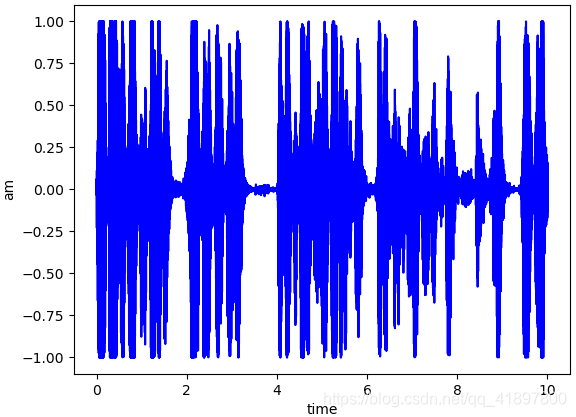
2.2 频域特征
numpy模块自带了快速傅里叶变换的函数,对上面的音频数据进行傅里叶变换:

2.3 语谱图
语音信号用频谱向量序列表示
语音的时域分析和频域分析是语音分析的两种重要方法,但是都存在着局限性。时域分析对语音信号的频率特性没有直观的了解,频域特性中又没有语音信号随时间的变化关系。语谱图的原理如下:
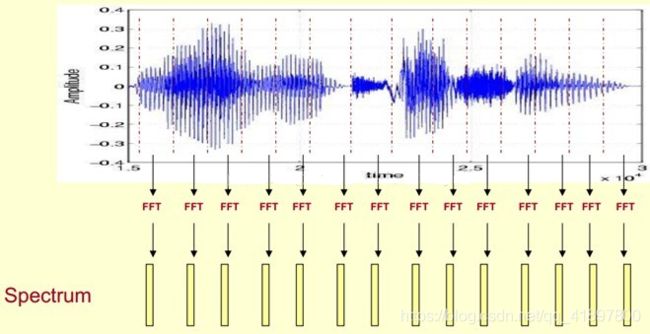
语音被分为很多帧,每帧语音都对应于一个频谱(通过短时FFT计算),频谱表示频率与能量的关系。在实际使用中,频谱图有三种,即线性振幅谱、对数振幅谱、自功率谱(对数振幅谱中各谱线的振幅都作了对数计算,所以其纵坐标的单位是dB(分贝)。这个变换的目的是使那些振幅较低的成分相对高振幅成分得以拉高,以便观察掩盖在低幅噪声中的周期信号)
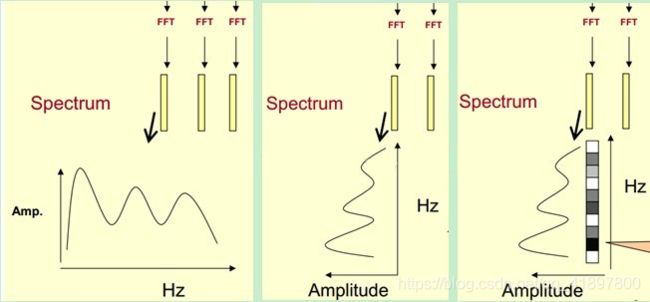
将其中一帧语音的频谱通过坐标表示出来,如上图左。现在我们将左边的频谱旋转90度。得到中间的图。然后把这些幅度映射到一个灰度级表示,0表示黑,255表示白色。幅度值越大,相应的区域越黑。这样就得到了最右边的图。那为什么要这样呢?为的是增加时间这个维度,这样就可以显示一段语音而不是一帧语音的频谱,而且可以直观的看到静态和动态的信息
这样会得到一个随着时间变化的频谱图,这个就是描述语音信号的spectrogram语谱图或声谱图:

语谱图综合了时域和频域的优点,明显的显示出了语音频谱随时间的变化情况、语谱图的横轴为时间,纵轴为频率,任意给定频率成分在给定时刻的强弱用颜色深浅来表示。颜色深的,频谱值大,颜色浅的,频谱值小。语谱图上不同的黑白程度形成不同的纹路,称之为声纹,不同讲话者的声纹是不一样的,可用作声纹识别。
语谱图分为功率谱,幅度谱,相位谱。使用matplotlib可以直接获得语谱图:
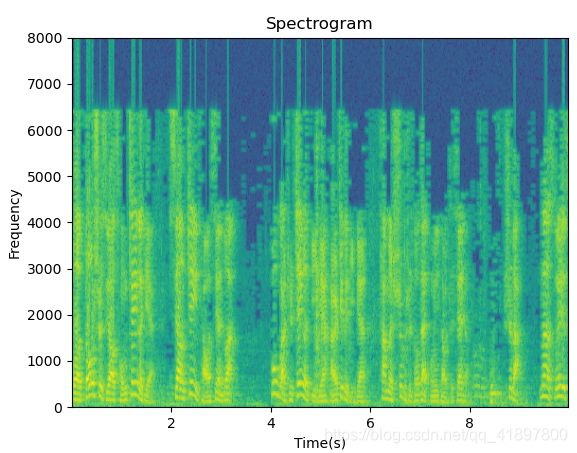
具体函数的参数可见matplotlib官方文档
语谱图分为窄带和宽带语谱图。“窄带”,顾名思义,带宽小,则时宽大,则短时窗长,窄带语谱图就是长窗条件下画出的语谱图。“宽带”,正好相反。至于“横竖条纹”,窄带语谱图的带宽窄,那么在频率上就“分得开”,即能将语音各次谐波“看得很清楚”,即表现为“横线”。“横”就体现出了频率分辨率高。分辨率可以直观的看做“分开能力”。“频率分辨率”高就是在频率上将各次谐波分开的能力高,表现为能分辨出各次谐波的能力高,频率分辨率越高,越容易分辨各次谐波。类似的,宽带语谱图的时宽窄,那么在时间上就“分得开”,即能将语音在时间上重复的部分“看得很清楚”,即表现为“竖线”。“竖”就体现出了时间分辨率高。时间分辨率越高,谱图上的竖线看得越清楚。图1和图2分别示出了一条语音句子的窄带语谱图和宽带语谱图。短时窗长度分别是20ms和2ms
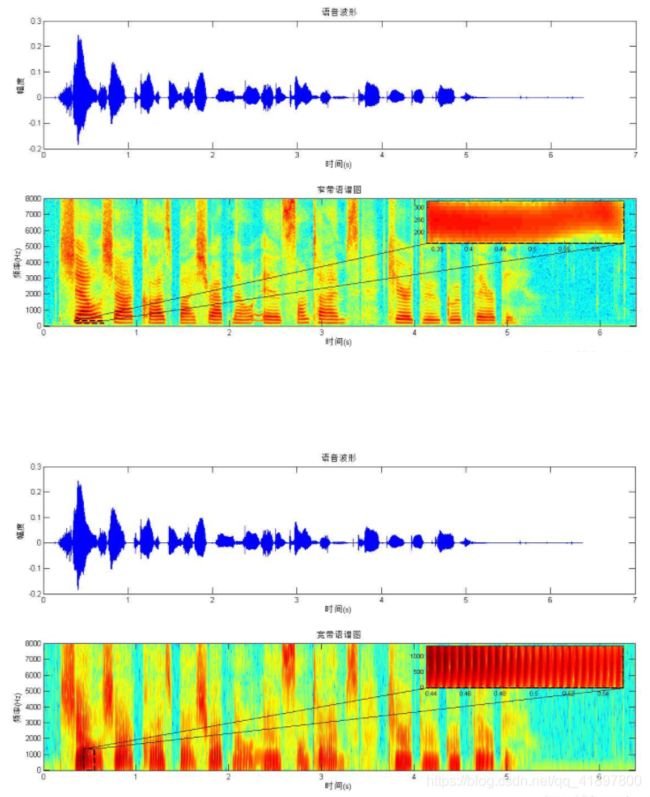
我们为什么要为语谱图而烦恼?在语谱图中可以更好地观察到音素Phone及其特性,通过声母和它们的转换可以更好地识别声音,隐马尔可夫模型对这些谱图进行隐性建模,以进行语音识别
语谱图的作用:
- 语音信号的时间-频率表示方法
- 语谱图是研究语音(音素Phone)的工具
- 语音学家对音素Phone及其特性进行直观研究
- 隐马尔科夫模型隐含了语音到文本系统的语谱图模型
- 有助于评估文本到语音系统——一个高质量的文本到语音系统应该产生合成语音,其频谱图应该与自然句子几乎一致
3. 倒谱分析
Cepstral Analysis
MFCC的PPT,以及对应的这篇Blog写的很好
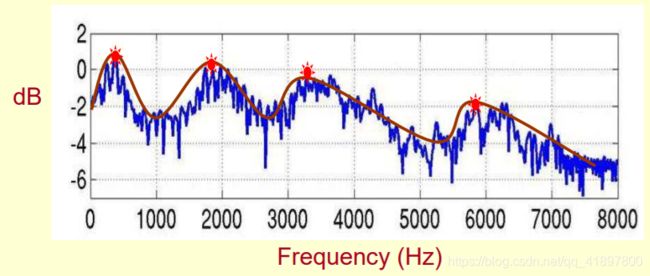
语音频谱样本:

- 峰值表示语音信号中的主导频率成分
- 峰值被称为共振峰(formants)
- 共振峰带有声音的特征
我们要提取什么?-语音频谱包络
- 共振峰和连接它们的平滑曲线
- 这种平滑曲线被称为频谱包络线
log X[k] = log H[k] + log E[k]
- 我们的目标:我们希望将频谱包络和频谱细节从频谱中分离出来
- 即给定对数X[k],得到对数H[k]和对数E[k],使对数X[k]=对数H[k]+对数E[k]
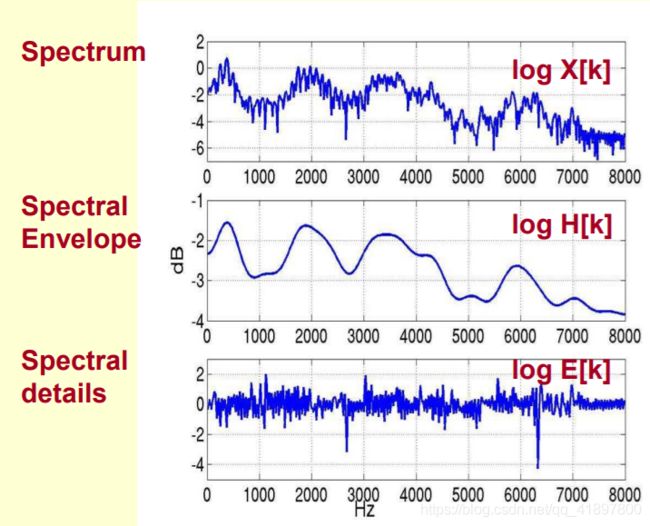
怎么实现这个分离?
- 技巧:取频谱的FFT!
- 频谱上的FFT被称为反向FFT(IFFT)
- 注:我们处理的是对数域的频谱(部分技巧)
- 对数频谱的IFFT将在伪频轴上表示信号


- 在实际操作中,你所能接触到的只有对数X[k],因此你可以得到x[k]
- 如果知道x[k] 过滤低频区域,得到h[k]
- x[k]简称为Cepstrum
- h[k]是通过考虑x[k]的低频区域得到的
- h[k]代表频谱包络,被广泛用于语音识别的特征
现在总结下倒谱分析,它实际上是这样一个过程:
- 将原语音信号经过傅里叶变换得到频谱:X[k]=H[k]E[k];只考虑幅度就是:|X[k] |=|H[k]||E[k] |;
- 我们在两边取对数:log||X[k] ||= log ||H[k] ||+ log ||E[k] ||
- 再在两边取逆傅里叶变换得到:x[k]=h[k]+e[k]
专业的名字叫做同态信号处理。它的目的是将非线性问题转化为线性问题的处理方法。对应上面,原来的语音信号实际上是一个卷性信号(声道相当于一个线性时不变系统,声音的产生可以理解为一个激励通过这个系统),第一步通过卷积将其变成了乘性信号(时域的卷积相当于频域的乘积)。第二步通过取对数将乘性信号转化为加性信号,第三步进行逆变换,使其恢复为卷性信号。这时候,虽然前后均是时域序列,但它们所处的离散时域显然不同,所以后者称为倒谱频域
总结下,倒谱(cepstrum)就是一种信号的傅里叶变换经对数运算后再进行傅里叶反变换得到的谱。它的计算过程如下:

4. 梅尔系数
4.1 梅尔频率倒谱系数
Mel Frequency Cepstral Coefficient (MFCC) tutorial,MFCC特征原理,这篇关于MFCC的计算过程很详细
人的听觉系统是一个特殊的非线性系统,它响应不同频率信号的灵敏度是不同的。在语音特征的提取上,人类听觉系统做得非常好,它不仅能提取出语义信息, 而且能提取出说话人的个人特征,这些都是现有的语音识别系统所望尘莫及的。如果在语音识别系统中能模拟人类听觉感知处理特点,就有可能提高语音的识别率
梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient, MFCC)考虑到了人类的听觉特征,先将线性频谱映射到基于听觉感知的Mel非线性频谱中,然后转换到倒谱上
我们将频谱通过一组Mel滤波器就得到Mel频谱。公式表述就是:log X[k] = log (Mel-Spectrum)。这时候我们在log X[k]上进行倒谱分析:
- 取对数:log X[k] = log H[k] + log E[k]
- 进行逆变换:x[k] = h[k] + e[k]
在Mel频谱上面获得的倒谱系数h[k]就称为Mel频率倒谱系数,简称MFCC
4.2 Mel滤波器原理
将普通频率转化到Mel频率的公式是:
mel ( f ) = 2595 ∗ log 10 ( 1 + f / 700 ) \operatorname{mel}(f)=2595 * \log _{10}(1+f / 700) mel(f)=2595∗log10(1+f/700)
由下图可以看到,它可以将不统一的频率转化为统一的频率,也就是统一的滤波器组
import math
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文标签
plt.rcParams['axes.unicode_minus'] = False
x = list(range(5500)) # [300, 8000]
y = [2595 * math.log((1 + i/700), 10) for i in x] # [401.9705861630035, 2840.0230467083184]
y = [1125 * math.log(1 + i/700) for i in x] # [401.25931193107397, 2834.997715799179]
plt.plot(x,y)
plt.xlim(0,)
plt.ylim(0,)
plt.xlabel('普通频率(HZ)',fontsize=12)
plt.ylabel('Mel频率(HZ)',fontsize=12)
plt.show()

在Mel频谱上面获得的倒谱系数h[k]就称为Mel频率倒谱系数,简称MFCC
4.3 MFCC特征提取思路
这篇文章有详细的计算
(梅尔语谱图)
提取MFCC特征的过程:
- 预加重:减小噪声的高频分量,但是对噪声并没有影响,因此可有效提高输出信噪比
- 波形图分帧
- 对每一帧进行加窗:例如使用汉明窗(hamming window)对信号进行加窗处理
- 对每一帧进行离散傅里叶变化(DFT)
- 计算功率谱
- 计算Mel-spaced filterbank
- 对上述128维的mel功率谱取log,得到128维的 log-mel filer bank energies
具体的,我们从一个语音信号开始,我们假设采样频率为16kHz:
- 将信号框成20-40ms的帧。25ms是标准的。这意味着16kHz信号的帧长是0.025*16000=400个采样。帧步长通常是10ms(160个样本)这样的东西,这允许帧有一些重叠。第一个400个采样帧从0号采样开始,下一个400个采样帧从160号采样开始,等等,直到到达语音文件的终点。如果语音文件没有被分成偶数帧,就用0垫起来,这样就可以了
接下来的步骤应用于每一个单帧,每帧提取一组12个MFCC系数。一个简短的旁白符号:我们称我们的时域信号为 s ( n ) s(n) s(n) 。一旦它被定格,我们有 s i ( n ) s_i(n) si(n)其中n范围在1-400(如果我们的帧是400个样本)和 i i i范围超过帧数。当我们计算复数DFT时,我们得到 S i ( k ) S_i(k) Si(k)–其中 i i i表示对应于时域帧的帧数, P i ( k ) P_i(k) Pi(k)那么就是帧 i i i的功率谱 - 要对帧进行离散傅里叶变换,请执行以下操作:
S i ( k ) = ∑ n = 1 N s i ( n ) h ( n ) e − j 2 π k n / N 1 ≤ k ≤ K S_{i}(k)=\sum_{n=1}^{N} s_{i}(n) h(n) e^{-j 2 \pi k n / N} \quad 1 \leq k \leq K Si(k)=n=1∑Nsi(n)h(n)e−j2πkn/N1≤k≤K
其中 h ( n ) h(n) h(n)是一个样本长为N的分析窗口(例如hamming window),K是DFT的长度,基于周期图的语音帧 s i ( n ) s_i(n) si(n)功率谱估计方法:
P i ( k ) = 1 N ∣ S i ( k ) ∣ 2 P_{i}(k)=\frac{1}{N}\left|S_{i}(k)\right|^{2} Pi(k)=N1∣Si(k)∣2
这就是所谓的功率谱的周期图估计。我们取复数傅里叶变换的绝对值,并将结果平方。我们一般会执行512个点的FFT,只保留前257个系数 - 计算Mel间隔滤波库。这是一组20-40(26是标准的)三角滤波器,我们将其应用于步骤2中的周期图功率谱估计。我们的滤波库是以26个长度为257的向量的形式出现的(假设FFT设置为第2步)。每个向量大部分都是零,但在某段频谱中是非零。为了计算滤波组的能量,我们将每个滤波组与功率谱相乘,然后将系数相加。一旦这样做,我们就会得到26个数字,这些数字可以让我们知道每个滤波组有多少能量。关于如何计算滤波组的详细解释请看下文。下面是一张
Mel Filterbank和窗口功率谱图,希望能说明问题

- 取步骤3中26个能量的对数。这样我们就有26个对数滤波库(filterbank)能量
- 对26个对数滤波库能量进行离散余弦变换(DCT),得到26个表观系数。对于ASR,只保留26个系数中较低的12-13个
- 由此产生的特征(每帧12个数字)称为Mel频率倒数系数
4.4 计算Mel filterbank
在本节中,本例将使用10个filterbanks,因为它更容易显示,在现实中你会使用26-40个过滤库
为了得到图(a)所示的滤波库filterbanks,我们首先要选择一个下频和上频。好的值是下限频率为300Hz,上限频率为8000Hz。当然如果语音的采样频率为8000Hz,我们的上频就会被限制在4000Hz。然后按照以下步骤进行:
- 使用从频率到梅尔音阶的转换公式为:
M ( f ) = 1125 ln ( 1 + f / 700 ) M(f)=1125 \ln (1+f / 700) M(f)=1125ln(1+f/700)
将上、下频率转换为Mels。在我们的例子中,300Hz是401.25 Mels,8000Hz是2834.99 Mels - 在这个例子中,我们将做10个滤波库,为此我们需要12个点。这意味着我们需要在401.25和2834.99之间再增加10个点的线性间隔。这就得出了:
[ 401.25931193 622.50825774 843.75720354 1065.00614935 1286.25509516 1507.50404096 1728.75298677 1950.00193257 2171.25087838 2392.49982419 2613.74876999 2834.9977158 ]
- 现在用公式:
M − 1 ( m ) = 700 ( exp ( m / 1125 ) − 1 ) M^{-1}(m)=700(\exp (m / 1125)-1) M−1(m)=700(exp(m/1125)−1)
把这些换算回赫兹,注意到,我们的起始点和终点都在我们想要的频率上:
[300.0, 517.3370529507943, 781.9095004869245, 1103.9833440625362, 1496.0557676334065, 1973.3400562864445, 2554.3559056550503, 3261.6480274431315, 4122.660934555949, 5170.803849453262, 6446.747056545612, 7999.999999999999]
- 我们不具备在上面计算的精确点上放滤波器所需的频率分辨率,所以我们需要将这些频率舍入到最近的FFT bin。这个过程不会影响特征的准确性。为了将频率单位转换为FFT bin数,我们需要知道FFT大小和采样率:
[ 9. 16. 25. 35. 47. 63. 81. 104. 132. 165. 206. 256.]
我们可以看到,最终的滤波库在bin 256处完成,相当于8kHz,FFT大小为512点
- 现在我们创建我们的滤波组。第一个滤池从第一点开始,在第二点达到峰值,然后在第三点回到零。第二个滤岸将从第2点开始,在第3点达到最大值,然后在第4点为零,等等。计算公式如下:
H m ( k ) = { 0 k < f ( m − 1 ) k − f ( m − 1 ) f ( m ) − f ( m − 1 ) f ( m − 1 ) ≤ k ≤ f ( m ) f ( m + 1 ) − k f ( m + 1 ) − f ( m ) f ( m ) ≤ k ≤ f ( m + 1 ) 0 k > f ( m + 1 ) H_{m}(k)=\left\{\begin{array}{cl} 0 & k
其中M是我们想要的滤波器数量,f()是M+2个Mel间隔频率的列表,所有10个滤波器相互叠加的最终图:
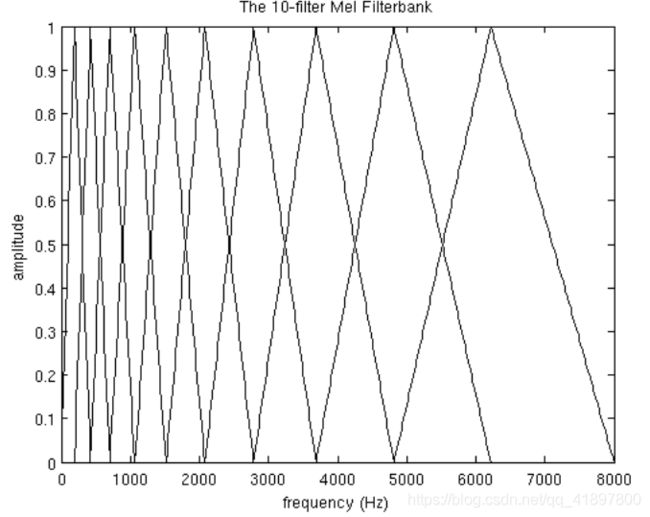
一个包含10个滤波器的Mel滤波库。这个滤波器库从0Hz开始,到8000Hz结束。这只是一个指南,上面的工作例子开始在300Hz
部分创建Filterbanks的代码:
import math
import numpy as np
# import matplotlib.pyplot as plt
import scipy.signal
# plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文标签
# plt.rcParams['axes.unicode_minus'] = False
x = [300,8000]
mel = [1125 * math.log(1 + i/700) for i in x]
# print(mel)
mel_domain_hz = np.linspace(mel[0],mel[1],12)
# print(mel_domain_hz)
time_domain_hz = [700*(math.exp(i/1125)-1) for i in mel_domain_hz]
# print(time_domain_hz)
nfft=512
samplerate = 16000
FFT = np.floor((nfft+1)*np.array(time_domain_hz)/samplerate)
print(FFT)
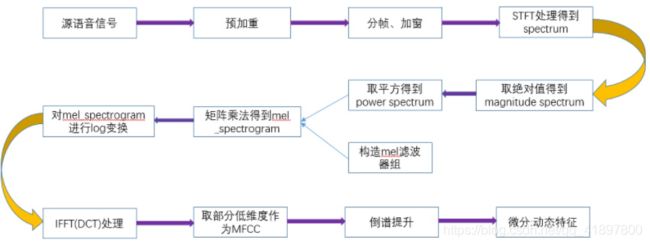
MFCCs(Mel-frequency cepstral coefficients)即梅尔频率倒谱系数,mfcc特征在梅尔语谱图的基础上增加了dct倒谱环节,DCT也可以理解为没有虚部的FFT,通过python提取MFCCs有两种方式,通过librosa模块或者python_speech_features模块,具体区别可见语音MFCC提取:librosa && python_speech_feature,整个梅尔语音特征的提取过程如下:
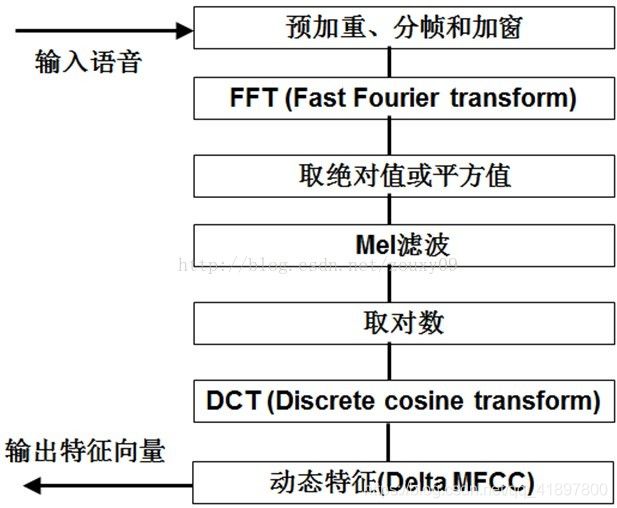
Deltas and Delta-Deltas
又称微分系数和加速度系数。MFCC特征向量只描述了单帧的功率谱包络,但似乎语音也会有动态的信息,即MFCC系数随时间的轨迹是什么。事实证明,计算MFCC轨迹,并将其附加到原始特征向量上,会使ASR性能提高不少(如果我们有12个MFCC系数,我们也会得到12个delta系数,两者相加就会得到一个长度为24的特征向量)
4.5 代码实现
4.5.1 通过python_speech_features提取mfcc
官方文档,首先安装python_speech_features模块
pip install python_speech_features
结果:
MFCC:
窗口数 = 999
每个特征的长度 = 13
Filter bank:
窗口数 = 999
每个特征的长度 = 26
![]()
![]()
4.5.2 通过librosa提取mfcc

官方文档,首先安装librosa模块:
pip install librosa
结果:

从以上结果可以看到,这两个库提取出的mfcc是不一样的,原因在于一个nFFT为512,另一个为2048
5. 差分
a = [1 2 3 4 5 1 3 5 7]
b = liborsa.feature.delta(a, width=3)
> b= [ 0.5 1. 1. 1. -1.5 -1. 2. 2. 1. ]
6. 完整代码
import wave
import numpy as np
import matplotlib.pyplot as plt
from scipy.io import wavfile
from python_speech_features import mfcc, logfbank
import librosa
dic = {}
path = '... your path\\TAL_SER语音情感数据集\\TAL-SER\\'
path_label = path + 'label\\' + 'label' # label:标签
path_utt2gen = path + 'label\\' + 'utt2gen' # Gender:性别
path_utt2spk = path + 'label\\' + 'utt2spk' # Speaker:说话人
path_wav = path + 'label\\' + 'wav.scp' # wav地址
total = -1 # 4188
with open(path_label, 'r', encoding='utf-8') as file:
for line in file.readlines():
total += 1
if total == 0:
continue
tmp = line.strip().split(' ')
dic[eval(tmp[0])] = {'P':eval(tmp[1]), 'A':eval(tmp[2])}
with open(path_utt2gen, 'r', encoding='utf-8') as file:
for line in file.readlines():
tmp = line.strip().split(' ')
dic[eval(tmp[0])].update({'Gender':tmp[1]})
with open(path_utt2spk, 'r', encoding='utf-8') as file:
for line in file.readlines():
tmp = line.strip().split(' ')
dic[eval(tmp[0])].update({'Speaker':tmp[1]})
with open(path_wav, 'r', encoding='utf-8') as file:
for line in file.readlines():
tmp = line.strip().split(' ')
dic[eval(tmp[0])].update({'Wav': tmp[1][1:]})
def read_wav(path_wav):
f = wave.open(path_wav, 'rb')
params = f.getparams()
nchannels, sampwidth, framerate, nframes = params[:4] # 通道数、采样字节数、采样率、采样帧数
voiceStrData = f.readframes(nframes)
waveData = np.frombuffer(voiceStrData, dtype=np.short) # 将原始字符数据转换为整数
waveData = waveData * 1.0 / max(abs(waveData)) # 音频数据归一化, instead of .fromstring
waveData = np.reshape(waveData, [nframes, nchannels]).T # .T 表示转置, 将音频信号规整乘每行一路通道信号的格式,即该矩阵一行为一个通道的采样点,共nchannels行
f.close()
return waveData, nframes, framerate
def draw_time_domain_image(waveData, nframes, framerate): # 时域特征
time = np.arange(0,nframes) * (1.0/framerate)
plt.plot(time,waveData[0,:],c='b')
plt.xlabel('time')
plt.ylabel('am')
plt.show()
def draw_frequency_domain_image(waveData): # 频域特征
fftdata = np.fft.fft(waveData[0, :])
fftdata = abs(fftdata)
hz_axis = np.arange(0, len(fftdata))
plt.figure()
plt.plot(hz_axis, fftdata, c='b')
plt.xlabel('hz')
plt.ylabel('am')
plt.show()
def draw_Spectrogram(waveData, framerate): # 语谱图
framelength = 0.025 # 帧长20~30ms
framesize = framelength * framerate # 每帧点数 N = t*fs,通常情况下值为256或512,要与NFFT相等, 而NFFT最好取2的整数次方,即framesize最好取的整数次方
nfftdict = {}
lists = [32, 64, 128, 256, 512, 1024]
for i in lists: # 找到与当前framesize最接近的2的正整数次方
nfftdict[i] = abs(framesize - i)
sortlist = sorted(nfftdict.items(), key=lambda x: x[1]) # 按与当前framesize差值升序排列
framesize = int(sortlist[0][0]) # 取最接近当前framesize的那个2的正整数次方值为新的framesize
NFFT = framesize # NFFT必须与时域的点数framsize相等,即不补零的FFT
overlapSize = 1.0 / 3 * framesize # 重叠部分采样点数overlapSize约为每帧点数的1/3~1/2
overlapSize = int(round(overlapSize)) # 取整
spectrum, freqs, ts, fig = plt.specgram(waveData[0], NFFT=NFFT, Fs=framerate, window=np.hanning(M=framesize),
noverlap=overlapSize, mode='default', scale_by_freq=True, sides='default',
scale='dB', xextent=None) # 绘制频谱图
plt.ylabel('Frequency')
plt.xlabel('Time(s)')
plt.title('Spectrogram')
plt.show()
def mfcc_python_speech_features(path):
sampling_freq, audio = wavfile.read(path) # 读取输入音频文件
mfcc_features = mfcc(audio, sampling_freq) # 提取MFCC和滤波器组特征
filterbank_features = logfbank(audio, sampling_freq) # numpy.ndarray, (999, 26)
print(filterbank_features.shape) # (200, 26)
# print('\nMFCC:\n窗口数 =', mfcc_features.shape[0])
# print('每个特征的长度 =', mfcc_features.shape[1])
# print('\nFilter bank:\n窗口数 =', filterbank_features.shape[0])
# print('每个特征的长度 =', filterbank_features.shape[1])
# mfcc_features = mfcc_features.T # 画出特征图,将MFCC可视化。转置矩阵,使得时域是水平的
# plt.matshow(mfcc_features)
# plt.title('MFCC')
# filterbank_features = filterbank_features.T # 将滤波器组特征可视化。转置矩阵,使得时域是水平的
# plt.matshow(filterbank_features)
# plt.title('Filter bank')
# plt.show()
def mfcc_librosa(path):
y, sr = librosa.load(path, sr=None)
'''
librosa.feature.mfcc(y=None, sr=22050, S=None, n_mfcc=20, dct_type=2, norm='ortho', **kwargs)
y:声音信号的时域序列
sr:采样频率(默认22050)
S:对数能量梅尔谱(默认为空)
n_mfcc:梅尔倒谱系数的数量(默认取20)
dct_type:离散余弦变换(DCT)的类型(默认为类型2)
norm:如果DCT的类型为是2或者3,参数设置为"ortho",使用正交归一化DCT基。归一化并不支持DCT类型为1
kwargs:如果处理时间序列输入,参照melspectrogram
返回:
M:MFCC序列
'''
mfcc_data = librosa.feature.mfcc(y, sr, n_mfcc=13)
plt.matshow(mfcc_data)
plt.title('MFCC')
plt.show()
if __name__ == '__main__':
# for key in dic:
# print(dic[key])
# print(dic[2])
# path_wav = path + dic[2]['Wav']
path_wav = '... your path\\CASIA database\\liuchanhg\\surprise\\201.wav'
waveData, nframes, framerate = read_wav(path_wav)
# draw_time_domain_image(waveData, nframes, framerate)
# draw_frequency_domain_image(waveData)
# draw_Spectrogram(waveData, framerate)
mfcc_python_speech_features(path_wav)
# mfcc_librosa(path_wav)
小结
大致入门了一下语音部分的基本操作:
- 时域、频域、语谱图绘制过程
- 倒谱分析,先经过短时傅里叶变化到频域,此时为乘积形式,求Log,转成加法形式,再分别求逆傅里叶变换,即可求得h[k],MFCC就是在Mel频率下进行上述的计算
- MFCC具体的过程,Filterbanks设计比较简单,之后对每一帧加重、分帧、加窗、求STFT、绝对值取平方、经过滤波器(矩阵乘法)、log、DCT、取低维部分为MFCC(倒谱提升、微分动态特征)