智能优化算法:向量加权平均算法-附代码
智能优化算法:向量加权平均算法
文章目录
- 智能优化算法:向量加权平均算法
-
- 1.算法原理
-
- 1.1初始化
- 1.2更新规则阶段
- 1.3 向量合并阶段
- 1.4 局部搜索阶段
- 2.实验结果
- 3.参考文献
- 4.Matlab代码
摘要:向量加权平均算法(Weighted mean of vectors algorithm, INFO),是于2022年提出的一种新型智能优化算法。该算法通过向量的不同加权平均规则,来达到寻优目的。具有寻优能力强,收敛速度快等特点。
1.算法原理
1.1初始化
与其他优化算法一样,种群个体在搜索空间内随机初始化。
1.2更新规则阶段
INFO使用基于均值的规则(MeanRule)更新向量的位置,这是从一组随机向量的加权均值中提取的。此外,为了提高全局搜索能力,在更新规则算子中加入了收敛加速部分(CA)。更新规则的主要公式定义为:
z 1 l g = { x l g + σ × MeanRules + randn × x b s − x a 1 g f ( x b s ) − f ( x a 1 g ) + 1 , rand < 0.5 x b s + σ × MeanRules + randn × x a 2 g − x a 3 g f ( x a 2 g ) − f ( x a 3 g ) + 1 , rand ≥ 0.5 z 2 l g = { x b s + σ × MeanRule + randn × x a 1 g − x b g f ( x a 1 g ) − f ( x a 2 g ) + 1 , rand < 0.5 x b t + σ × MeanRule + randn × x a 1 g − x a 2 g f ( x a 1 g ) − f ( x a 2 g ) + 1 , rand ≥ 0.5 (1) \begin{array}{l} z 1_{l}^{g}=\left\{\begin{array}{ll} x_{l}^{g}+\sigma \times \text { MeanRules }+\text { randn } \times \frac{x_{b s}-x_{a 1}^{g}}{f\left(x_{b s}\right)-f\left(x_{a 1}^{g}\right)+1}, & \text { rand }<0.5 \\ x_{b s}+\sigma \times \text { MeanRules }+\operatorname{randn} \times \frac{x_{a 2}^{g}-x_{a 3}^{g}}{f\left(x_{a 2}^{g}\right)-f\left(x_{a 3}^{g}\right)+1}, & \text { rand } \geq 0.5 \end{array}\right. \\ z 2_{l}^{g}=\left\{\begin{array}{ll} x_{b s}+\sigma \times \text { MeanRule }+\operatorname{randn} \times \frac{x_{a 1}^{g}-x_{b}^{g}}{f\left(x_{a 1}^{g}\right)-f\left(x_{a 2}^{g}\right)+1}, & \text { rand }<0.5 \\ x_{b t}+\sigma \times \text { MeanRule }+\operatorname{randn} \times \frac{x_{a 1}^{g}-x_{a 2}^{g}}{f\left(x_{a 1}^{g}\right)-f\left(x_{a 2}^{g}\right)+1}, & \text { rand } \geq 0.5 \end{array}\right. \end{array} \tag{1} z1lg=⎩⎨⎧xlg+σ× MeanRules + randn ×f(xbs)−f(xa1g)+1xbs−xa1g,xbs+σ× MeanRules +randn×f(xa2g)−f(xa3g)+1xa2g−xa3g, rand <0.5 rand ≥0.5z2lg=⎩⎨⎧xbs+σ× MeanRule +randn×f(xa1g)−f(xa2g)+1xa1g−xbg,xbt+σ× MeanRule +randn×f(xa1g)−f(xa2g)+1xa1g−xa2g, rand <0.5 rand ≥0.5(1)
其中, z 1 l g z1_l^g z1lg和 z 2 l g z2_l^g z2lg为第 g g g次迭代的新位置向量; σ \sigma σ为向量缩放率,通过式(2)计算所得; a 1 ≠ a 2 ≠ a 3 ≠ l a1\neq a2\neq a3\neq l a1=a2=a3=l是从 [ 1 , N P ] [1,NP] [1,NP]中随机选择的不同整数; r a n d n randn randn是一个标准正态分布随机值。应注意的是,在式(2)中, α \alpha α可以根据式(2.1)中定义的指数函数进行更新。
σ = 2 α × r a n d − α (2) \sigma = 2\alpha\times rand-\alpha \tag{2} σ=2α×rand−α(2)
α = 2 × exp ( − 4 g M a x g ) (2.1) \alpha=2\times \text{exp}(-4\frac{g}{Maxg})\tag{2.1} α=2×exp(−4Maxgg)(2.1)
M e a n R u l e MeanRule MeanRule定义如下:
MeanRule = r × W M 1 l g + ( 1 − r ) × W M 2 l g , l = 1 , 2 , ⋯ , N P (3) \text { MeanRule }=r \times W M 1_{l}^{g}+(1-r) \times W M 2_{l}^{g}, l=1,2, \cdots, N P \tag{3} MeanRule =r×WM1lg+(1−r)×WM2lg,l=1,2,⋯,NP(3)
其中, r r r是 [0,0.5]之间的随机数; W M 1 l g WM1_l^g WM1lg和 W M 2 l g WM2_l^g WM2lg定义如下:
W M 1 l g = δ × w 1 ( x a 1 − x a 2 ) + w 2 ( x a 1 − x a 3 ) + w 3 ( x a 2 − x a 3 ) w 1 + w 2 + w 3 + ε + ε × rand , l = 1 , 2 , ⋯ , N P (3.1) W M 1_{l}^{g}=\delta \times \frac{w_{1}\left(x_{a 1}-x_{a 2}\right)+w_{2}\left(x_{a 1}-x_{a 3}\right)+w_{3}\left(x_{a 2}-x_{a 3}\right)}{w_{1}+w_{2}+w_{3}+\varepsilon}+\varepsilon \times \operatorname{rand}, l=1,2, \cdots, N P \tag{3.1} WM1lg=δ×w1+w2+w3+εw1(xa1−xa2)+w2(xa1−xa3)+w3(xa2−xa3)+ε×rand,l=1,2,⋯,NP(3.1)
其中:
w 1 = cos ( ( f ( x a 1 ) − f ( x a 2 ) ) + π ) × exp ( − f ( x a 1 ) − f ( x a 2 ) ω ) (3.2) w_{1}=\cos \left(\left(f\left(x_{a 1}\right)-f\left(x_{a 2}\right)\right)+\pi\right) \times \exp \left(-\frac{f\left(x_{a 1}\right)-f\left(x_{a 2}\right)}{\omega}\right) \tag{3.2} w1=cos((f(xa1)−f(xa2))+π)×exp(−ωf(xa1)−f(xa2))(3.2)
w 2 = cos ( ( f ( x a 1 ) − f ( x a 3 ) ) + π ) × exp ( − f ( x a 1 ) − f ( x a 3 ) ω ) (3.3) w_{2}=\cos \left(\left(f\left(x_{a 1}\right)-f\left(x_{a 3}\right)\right)+\pi\right) \times \exp \left(-\frac{f\left(x_{a 1}\right)-f\left(x_{a 3}\right)}{\omega}\right) \tag{3.3} w2=cos((f(xa1)−f(xa3))+π)×exp(−ωf(xa1)−f(xa3))(3.3)
w 3 = cos ( ( f ( x a 2 ) − f ( x a 3 ) ) + π ) × exp ( − f ( x a 2 ) − f ( x a 3 ) ω ) (3.4) w_{3}=\cos \left(\left(f\left(x_{a 2}\right)-f\left(x_{a 3}\right)\right)+\pi\right) \times \exp \left(-\frac{f\left(x_{a 2}\right)-f\left(x_{a 3}\right)}{\omega}\right) \tag{3.4} w3=cos((f(xa2)−f(xa3))+π)×exp(−ωf(xa2)−f(xa3))(3.4)
ω = max ( f ( x a 1 ) , f ( x a 2 ) , f ( x a 3 ) ) (3.5) \omega=\max \left(f\left(x_{a 1}\right), f\left(x_{a 2}\right), f\left(x_{a 3}\right)\right) \tag{3.5} ω=max(f(xa1),f(xa2),f(xa3))(3.5)
W M 2 l g = δ × w 1 ( x b s − x b t ) + w 2 ( x b s − x w s ) + w 3 ( x b t − x w s ) w 1 + w 2 + w 3 + ε + ε × rand , l = 1 , 2 , ⋯ , N P (3.6) W M 2_{l}^{g}=\delta \times \frac{w_{1}\left(x_{b s}-x_{b t}\right)+w_{2}\left(x_{b s}-x_{w s}\right)+w_{3}\left(x_{b t}-x_{w s}\right)}{w_{1}+w_{2}+w_{3}+\varepsilon}+\varepsilon \times \operatorname{rand}, l=1,2, \cdots, N P \tag{3.6} WM2lg=δ×w1+w2+w3+εw1(xbs−xbt)+w2(xbs−xws)+w3(xbt−xws)+ε×rand,l=1,2,⋯,NP(3.6)
其中:
w 1 = c o s ( ( f ( x b s ) − f ( x b t ) ) + π ) × exp ( − f ( x b s ) − f ( x b t ) w ) (3.7) w_1=cos((f(x_{bs})-f(x_{bt}))+\pi)\times \text{exp}(-\frac{f(x_{bs})-f(x_{bt})}{w})\tag{3.7} w1=cos((f(xbs)−f(xbt))+π)×exp(−wf(xbs)−f(xbt))(3.7)
w 2 = c o s ( ( f ( x b s ) − f ( x w s ) ) + π ) × exp ( − f ( x b s ) − f ( x w s ) w ) (3.8) w_2=cos((f(x_{bs})-f(x_{ws}))+\pi)\times \text{exp}(-\frac{f(x_{bs})-f(x_{ws})}{w})\tag{3.8} w2=cos((f(xbs)−f(xws))+π)×exp(−wf(xbs)−f(xws))(3.8)
w 3 = c o s ( ( f ( x b t ) − f ( x w s ) ) + π ) × exp ( − f ( x b t ) − f ( x w s ) w ) (3.9) w_3=cos((f(x_{bt})-f(x_{ws}))+\pi)\times \text{exp}(-\frac{f(x_{bt})-f(x_{ws})}{w})\tag{3.9} w3=cos((f(xbt)−f(xws))+π)×exp(−wf(xbt)−f(xws))(3.9)
w = f ( x w s ) (3.10) w=f(x_{ws}) \tag{3.10} w=f(xws)(3.10)
δ = 2 β × r a n d − β (3.11) \delta =2\beta\times rand-\beta \tag{3.11} δ=2β×rand−β(3.11)
β = α = 2 × exp ( − 4 g M a x g ) (3.12) \beta=\alpha=2\times\text{exp}(-4\frac{g}{Maxg})\tag{3.12} β=α=2×exp(−4Maxgg)(3.12)
其中, w 1 , w 2 , w 3 w_1,w_2,w_3 w1,w2,w3是三个加权函数,用于计算向量的加权平均值,有利于算法在解空间中全局搜索; x b s , x b t , x w s x_{bs},x_{bt},x_{ws} xbs,xbt,xws 分别是第 g g g代种群中最优、次优和最差的解向量。事实上,这些解向量是在每次迭代时对种群向量进行排序后确定的。
1.3 向量合并阶段
根据式(5),INFO将前一阶段中计算的两个向量 ( z 1 l g , z 2 l g ) (z1_l^g,z2_l^g) (z1lg,z2lg)与条件 r a n d < 0.5 rand<0.5 rand<0.5的向量 ( u l g ) (u_l^g) (ulg)相结合,生成新向量。事实上,该算子用于提升局部搜索能力,以提供一个新的更好的向量。
u l g = { { z 1 l g + μ ∣ z 1 l g − z 2 l g ∣ , r a n d 1 < 0.5 & & r a n d 2 < 0.5 z 2 l g + μ ∣ z 1 l g − z 2 l g ∣ , r a n d 1 < 0.5 & & r a n d 2 ≥ 0.5 x l g , r a n d 1 < 0.5 (4) u_l^g=\begin{cases} \begin{cases} z1_l^g+\mu|z1_l^g-z2_l^g|,rand1<0.5\&\&rand2<0.5\\ z2_l^g+\mu|z1_l^g-z2_l^g|,rand1<0.5\&\&rand2 \geq0.5 \end{cases}\\ x_l^g,rand1<0.5 \end{cases}\tag{4} ulg=⎩⎪⎨⎪⎧{z1lg+μ∣z1lg−z2lg∣,rand1<0.5&&rand2<0.5z2lg+μ∣z1lg−z2lg∣,rand1<0.5&&rand2≥0.5xlg,rand1<0.5(4)
其中, u l g u_l^g ulg是第 g g g代中的向量合并得到的新向量; μ = 0.05 × r a n d n \mu =0.05\times randn μ=0.05×randn
1.4 局部搜索阶段
INFO使用局部搜索阶段来防止陷入局部最优解。根据该算子,如果 r a n d < 0.5 rand<0.5 rand<0.5,则可以围绕生成一个新的向量,其中是[0,1]中的随机值。
u l g = { x b s + r a n d n × ( M e a n R u l e + r a n d n × ( x b s g − x a 1 g ) ) , r a n d 1 < 0.5 & & r a n d 2 < 0.5 x r n d + r a n d n × ( M e a n R u l e + r a n d n × ( v 1 × x b s − v 2 × x r n d ) ) , r a n d 1 < 0.5 & & r a n d 2 ≥ 0.5 (5) u_l^g=\begin{cases} x_{bs}+randn\times(MeanRule+randn\times(x_{bs}^g-x_{a1}^g)),rand1<0.5\&\& rand2<0.5\\ x_{rnd}+randn\times(MeanRule+randn\times(v_1\times x_{bs}-v_2\times x_{rnd})),rand1<0.5\&\& rand2\geq 0.5 \end{cases}\tag{5} ulg={xbs+randn×(MeanRule+randn×(xbsg−xa1g)),rand1<0.5&&rand2<0.5xrnd+randn×(MeanRule+randn×(v1×xbs−v2×xrnd)),rand1<0.5&&rand2≥0.5(5)
其中:
x r n d = ϕ × x a v g + ( 1 − ϕ ) × ( ϕ × x b t + ( 1 − ϕ ) × x b s ) (5.1) x_{rnd}=ϕ\times x_{avg}+(1-ϕ)\times(ϕ\times x_{bt}+(1-ϕ)\times x_{bs})\tag{5.1} xrnd=ϕ×xavg+(1−ϕ)×(ϕ×xbt+(1−ϕ)×xbs)(5.1)
x a v g = x a + x b + x c 3 (5.2) x_{avg}=\frac{x_a+x_b+x_c}{3} \tag{5.2} xavg=3xa+xb+xc(5.2)
其中, ϕ \phi ϕ表示(0,1)的随机数; x r n g x_{rng} xrng是由 x a v g x_{avg} xavg , x b t x_{bt} xbt和 x b s x_{bs} xbs组成的新解,这增加了所提出算法的随机性,以更好地在解空间中搜索; v 1 v_1 v1和 v 2 v_2 v2是两个随机数,定义如下:
v 1 = { 2 × r a n d , p > 0.5 1 , p ≤ 0.5 (5.3) v_1=\begin{cases} 2\times rand,p>0.5\\ 1,p\leq 0.5 \end{cases} \tag{5.3} v1={2×rand,p>0.51,p≤0.5(5.3)
v 2 = { r a n d , p > 0.5 1 , p ≤ 0.5 (5.4) v_2=\begin{cases} rand,p>0.5 \\ 1,p\leq0.5 \end{cases} \tag{5.4} v2={rand,p>0.51,p≤0.5(5.4)
算法流程图如下:
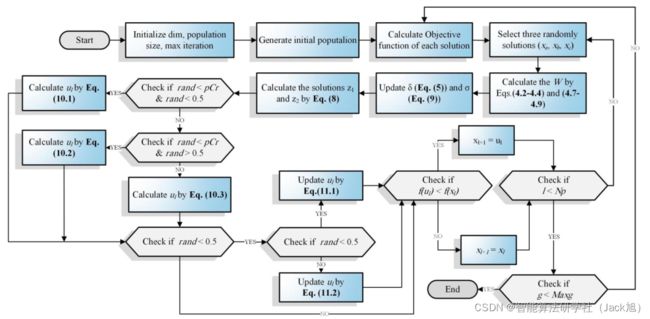
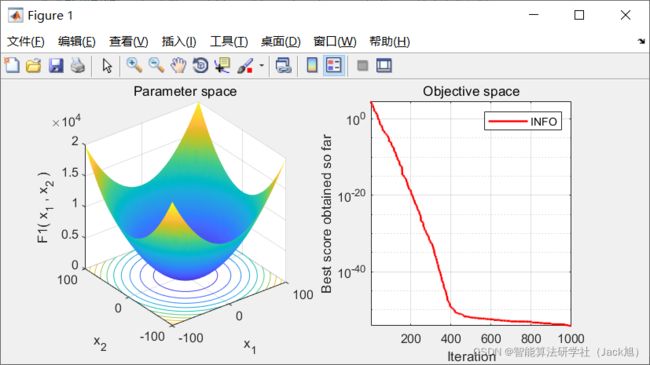
2.实验结果
3.参考文献
[1] Iman Ahmadianfar, Ali Asghar Heidari, Saeed Noshadian. INFO: An efficient optimization algorithm based on weighted mean of vectors[J]. Expert Systems With Applications, 2022, 195: 116516.