Datawhale-车道渲染数据智能质检
车道渲染数据智能质检
- 学习任务及时间点
- 1. 报名并理解赛题任务
- 2. 配置环境
-
- 2.1 基本概念
- 2.2 CUDA安装
- 2.3 相关shell指令
- 2.4 下载并解压数据
- 2.5 创建虚拟环境,并安装需要的库
- 3. baseline实践
-
- 3.1 配置jupyter notebook
- 3.2 运行代码
- 4. 数据处理、算法应用技能学习
-
- 4.1 多GPU运行设置
- 4.2 提升方法
-
- 4.2.1 设置数据扩增
- 4.2.2 模型优化
- 4.2.3 伪标签
- 4.3 结果记录
- 5.相关知识参考学习
-
- 5.1 类似比赛信息收集
- 5.2 关于数据扩增
-
- 5.2.1 深度学习训练中为什么要将图片随机剪裁
- 5.2.2 torchvision.transforms
-
- 1. 裁剪Crop
- 2. 翻转和旋转——Flip and Rotation
- 3. 图像变换
- 4. 操作随机选择、组合
学习任务及时间点
- 报名并理解赛题任务(9.12-9.13)
- 配置环境(9.14)
- baseline实践(9.15)
- 数据处理、算法应用技能学习(9.16-9.17)
- 相关知识参考学习(9.18)
1. 报名并理解赛题任务
车道渲染数据智能质检赛事介绍
-
赛题背景:为什么需要做视觉缺陷检测?
导航过程中所看到的背景道路界面是基于地图数据渲染生成,渲染过程中部分数据会存在不同程度的问题。为了更高效的检测这部分数据,降低人工成本,质检模型需要达到更高的准确度。
评价指标:AUC(Area Under Curve) -
赛题数据:赛题提供了一些什么数据?需要根据数据完成什么任务?
车道渲染数据,分为训练集和测试集(A/B),标注为csv文件,每行包括图片名及该图片是否存在问题标注。
数据包括7类问题,只需检测是否存在问题。 -
赛题任务:可将任务抽象为一个什么类型的基本模型?
图像二分类问题
2. 配置环境
2.1 基本概念
- 显卡: 简单理解这个就是我们前面说的
GPU,尤其指NVIDIA公司生产的GPU系列。 - 显卡驱动:通常指
NVIDIA Driver,其实它就是一个驱动软件,而前面的显卡就是硬件。 CUDA:并行计算平台和编程模型。cudnn是一个专门为深度学习计算设计的软件库,里面提供了很多专门的计算函数,如卷积等。
2.2 CUDA安装
- 到
CUDA Toolkit Download下载所需版本,建议选择使用 .run 文件安装,因为使用 .deb可能会将已经安装的较新的显卡驱动替换。 - 进入到放置
cuda_9.0.176_384.81_linux.run的目录:
sudo chmod +x cuda_9.0.176_384.81_linux.run # 为 cuda_9.0.176_384.81_linux.run 添加可执行权限
./cuda_9.0.176_384.81_linux.run # 安装 cuda_9.0.176_384.81_linux.run
参考链接
2.3 相关shell指令
- 查看cuda版本:
nvcc -Vorcat /usr/local/cuda/version.txtorprint(torch.version.cuda) - 查看pytorch版本:
print(torch.__version__) - 查看pytorch和cuda版本是否匹配:
print(torch.cuda.is_available())返回True说明版本是匹配的。
2.4 下载并解压数据
# 1.下载数据
wget https://digix-algo-challenge.obs.cn-east-2.myhuaweicloud.com/2022/AI/1d91a246f2b211ec82f95c80b6c7dac5/2022_2_data.zip
# 2. 安装rar解压(root权限下安装)并解压文件
unrar e Filename.rar # 解压指定压缩包内的文件到当前工作目录
2.5 创建虚拟环境,并安装需要的库
# 1. 创建并激活虚拟环境
conda create -n chedao python=3.7
conda activate chedao
# 2. 安装必要的库
pip3 install torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu113
pip3 install pillow pandas numpy opencv-python glob
3. baseline实践
3.1 配置jupyter notebook
配置 jupyter notebook
pip install jupyter
jupyter notebook # 默认打卡8888端口
# 映射远程服务器8888端口到本地8888端口
ssh -L8888:localhost:8888 <user>@<远程服务器IP地址>
# 在本地浏览器访问 localhost:8888
3.2 运行代码
新建 trian.ipynb 文件,输入代码并运行
代码和说明可参见CV项目baseline
实践过程的 train.ipynb 文件:https://download.csdn.net/download/qq_38869560/86539767
输出得到 submission.csv 文件并提交。
4. 数据处理、算法应用技能学习
4.1 多GPU运行设置
多GPU运行设置
因为全部数据集数据量约30G,单GPU训练较慢,故采用多GPU并行计算。采用4块GPU,并进行如下设置:
os.environ['CUDA_VISIBLE_DEVICES'] = '0,1,2,3'
device = 'cuda' if torch.cuda.is_available() else 'cpu'
#输出cuda说明使用gpu,输出cpu说明使用cpu,最好使用gpu训练
print(device)
# 传入训练数据
image, label = image.to(device), label.to(device)
#模型并行化
if torch.cuda.device_count() > 1:
print("Let's use", torch.cuda.device_count(), "GPUs!")
model = nn.DataParallel(model)
model = model.to(device) #使用GPU
4.2 提升方法
根据教程提示,以下方法会有效果:
- 设置数据扩增:根据数据特点进行数据扩增,可能有效的:
randcrop、randnoise、flip - 更强大的模型:需要考虑输入图像的尺寸,模型最终精度
- 利用无标签的数据:利用伪标签进行打标
4.2.1 设置数据扩增
根据图像特点,图片上下边缘存在大量无关,故计划采取中心裁剪,提取中间关键区域
%matplotlib inline
import torch
import torchvision
from torch import nn
from d2l import torch as d2l
d2l.set_figsize()
img = d2l.Image.open('./train_image/train_25885.png')
d2l.plt.imshow(img);
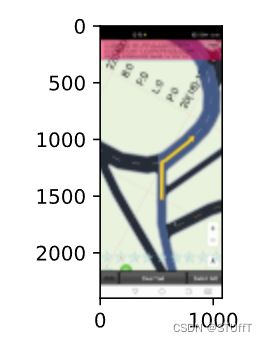
apply(img, torchvision.transforms.RandomHorizontalFlip())

augs = torchvision.transforms.Compose([
torchvision.transforms.Resize((448, 448)),
torchvision.transforms.CenterCrop((224, 224))])
apply(img, augs)
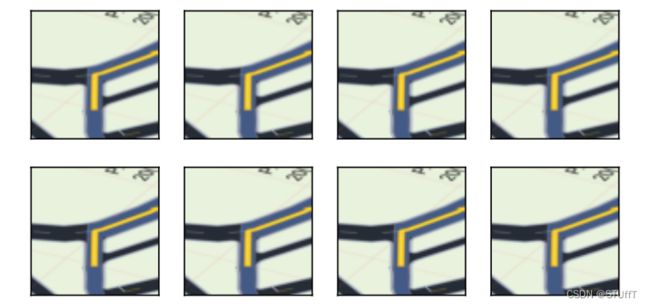
4.2.2 模型优化
torchvision 中给出的预训练模型和预训练权重:
MODELS AND PRE-TRAINED WEIGHTS
选择一个模型参数较少同时精度较高的模型:
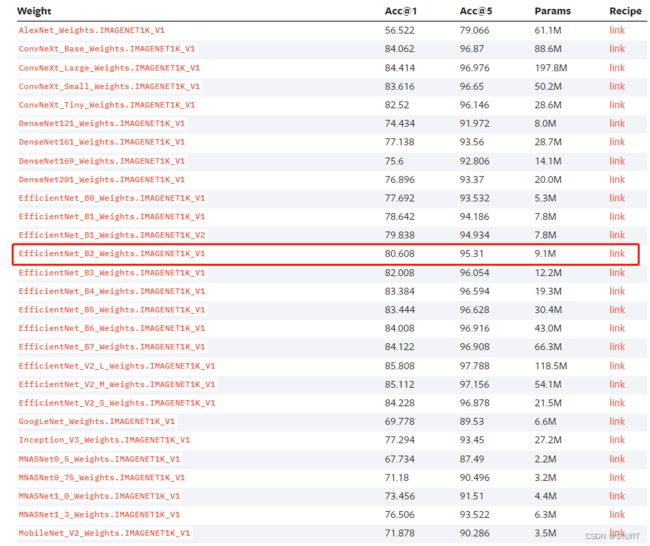
4.2.3 伪标签
半监督学习之伪标签(pseudo label,entropy minimization,self-training)
该种方法并未进行尝试。
4.3 结果记录
- 训练了 三个epoch, AUC比 baseline 提高了 0.05左右,达到了
0.787655,但仍是一个比较低的值。
- 接着尝试更改epoch=10,AUC达到
0.799951。
 仍然是一个较低的AUC值,离0.9还差很远。
仍然是一个较低的AUC值,离0.9还差很远。
5.相关知识参考学习
5.1 类似比赛信息收集
- 【图像分类】实战——使用EfficientNetV2实现图像分类(Pytorch)
- 脑PET图像分析和疾病预测挑战赛baseline——结果可达0.76左右——科大讯飞2020年度开发者大赛
- 科大讯飞2020脑PET图像分析和疾病预测—单模型进决赛前五
1 自适应裁剪填充:尽可能针对不同尺度的大脑进行自适应裁剪边界,使得处理后的图片能尽可能贴合大脑外壳,从而增大其ROI的区域
2 迭代微调交叉验证:在交叉验证中,在整个交叉验证过程中,只保存一个最好的模型,并从第i折起,加载前面保存好的最好的模型的参数进行迭代微调,最后也只得到唯一一个模型
3 预训练模型efficientNetb8以及交叉验证的方式进行finetune迭代
5.2 关于数据扩增
5.2.1 深度学习训练中为什么要将图片随机剪裁
- 推荐阅读:深度学习训练中为什么要将图片随机剪裁(random crop),其中提到的“俄罗斯坦克问题”直观形象。
随机裁剪可以使深度学习网络在训练时,找到对预测有用的特征组。
例如:假设输入图像中包含特征组 ( A , B , C , X , Y ) (A,B,C,X,Y) (A,B,C,X,Y)。其中, A , B , C A,B,C A,B,C为对预测有用的特征组, X , Y X,Y X,Y为噪声。
随机裁剪会将图片裁剪成包含如下特征的小图:
( A , B , X , Y ) ( A , B , C , Y ) ( A , B , C , X ) ( A , B , C ) . . . (A,B,X,Y)\\(A,B,C,Y)\\(A,B,C,X)\\(A,B,C)\\... (A,B,X,Y)(A,B,C,Y)(A,B,C,X)(A,B,C)...
这样,经过大量数据训练后,模型会发现 ( X , Y ) (X,Y) (X,Y)是对预测无用的特征, ( A , B , C ) (A,B,C) (A,B,C)对预测起作用。
5.2.2 torchvision.transforms
torchvision.transforms使用详解
-
torchvision包含以下子包
- torchvision.datasets
- torchvision.models
- torchvision.transforms
torchvision.transforms这个包中包含resize、crop等常见的data augmentation操作。
-
该包主要包含两个脚本 :
-
transformas.py定义了各种data augmentation的类 -
functional.py每个类中通过调用functional.py中对应的函数完成data augmentation操作
使用例子
import torchvision
import torch
data_transforms = {
'train': transforms.Compose([
transforms.ToPILImage(),
transforms.Resize(256),
# transforms.RandomResizedCrop(224,scale=(0.5,1.0)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
]),
'val': transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir, x), transform=data_transforms[x], loader=None),for x in ['train', 'val']}
1. 裁剪Crop
| 功能 | 函数 |
|---|---|
| 随机裁剪 | transforms.RandomCrop |
| 中心裁剪 | transforms.CenterCrop |
| 随机长宽比裁剪 | transforms.RandomResizedCrop |
| 上下左右中心裁剪 | transforms.FiveCrop |
| 上下左右中心裁剪后翻转 | transforms.TenCrop |
2. 翻转和旋转——Flip and Rotation
| 功能 | 函数 |
|---|---|
| 依概率p水平翻转 | transforms.RandomHorizontalFlip |
| 依概率p垂直翻转 | transforms.RandomVerticalFlip |
| 随机旋转 | transforms.RandomRotation |
3. 图像变换
| 功能 | 函数 |
|---|---|
| resize | transforms.Resize |
| 标准化 | transforms.Normalize |
| 转为tensor | transforms.ToTensor |
| 填充 | transforms.Pad |
| 修改亮度、对比度和饱和度 | transforms.ColorJitter |
| 转灰度图 | transforms.Grayscale |
| 线性变换 | transforms.LinearTransformation() |
| 仿射变换 | transforms.RandomAffine |
| 依概率p转为灰度图 | transforms.RandomGrayscale |
| 将数据转换为PILImage | transforms.ToPILImage |
| transforms.Lambda |
4. 操作随机选择、组合
| 函数 | 功能 |
|---|---|
| transforms.RandomChoice(transforms) | 从给定的一系列transforms中选一个进行操作 |
| transforms.RandomApply(transforms, p=0.5) | 给一个transform加上概率,以一定的概率执行该操作 |
| transforms.RandomOrder | 将transforms中的操作顺序随机打乱 |