LeNet训练Cifar-10数据集代码详解以及输出结果
首先讲一下交叉熵损失函数,里面包含了Softmax函数和NLL损失函数
接下来讲一下NLL损失函数
Legative Log Likelihood Loss,中文名称是最大似然或者log似然代价函数
似然函数是什么呢?
似然函数就是我们有一堆观察所得得结果,然后我们用这堆观察结果对模型的参数进行估计。
举个例子:
抛一个硬币,假设正面朝上的概率是θ,那么反面朝上的概率就是1-θ
但是我们不知道θ是多少,这个θ就是模型的参数
我们为了获得θ的值,我们抛了十次,得到一个序列x=正正反反正反正正正正,获得这个序列的概率是θ⋅θ⋅(1-θ)⋅(1-θ)⋅θ⋅(1-θ)⋅θ⋅θ⋅θ⋅θ = θ⁷ (1-θ)³,我们尝试所有θ可能的值,绘制了一个图(θ的似然函数)
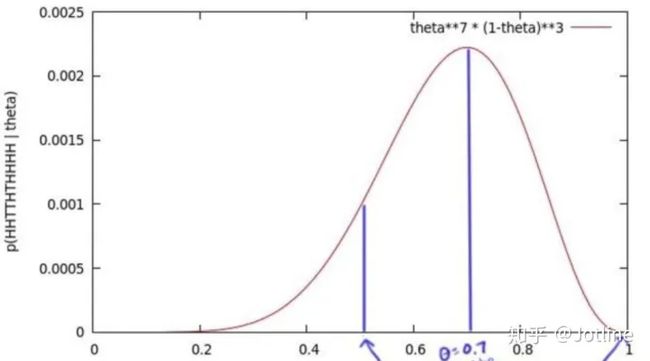
我们发现这个函数有最大值,当θ=0.7的时候,得到这个序列的概率最大,当我们实验的次数越来越多,这个最大值约接近真实值0.5。
损失函数的用途是衡量当前参数下模型的预测值和真实label的差距。似然函数损失函数当然也是如此。
在PyTorch中,CrossEntropyLoss其实是LogSoftMax和NLLLoss的合体。
交叉熵损失函数
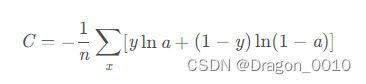
softmax函数
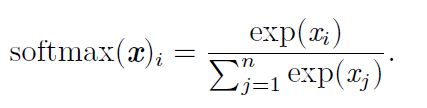
softmax一般用于多分类过程中,它将多个神经元的输出,映射到(0,1)区间内,可以看成概率来理解,从而来进行多分类!
loss(x,class)=−log(exp(x[class])∑jexp(x[j]))=−x[class]+log(∑jexp(x[j]))
什么叫做梯度下降法?
顺着梯度下滑,找到最陡的方向,迈一小步,然后再找当前位,置最陡的下山方向,再迈一小步…
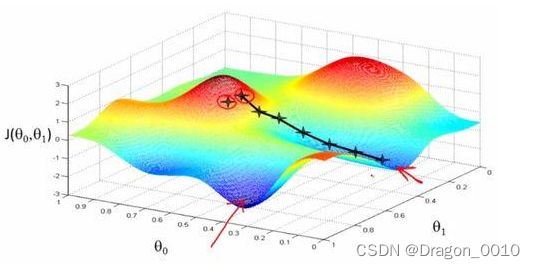
通过比较以上两个图,可以会发现,由于初始值的不同,会得到两个不同的极小值,所以权重初始值的设定也是十分重要的,通常的把W全部设置为0很容易掉到局部最优解,一般可以按照高斯分布的方式分配初始值。
当误差越大,梯度就越大,参数w(神经元之间的连接权重)调整得越快,训练速度也就越快
使用softmax函数之后,再使用交叉熵作为损失函数,也会使得求梯度变得十分简单,
学习率
将输出误差反向传播给网络参数,以此来拟合样本的输出。本质上是最优化的一个过程,逐步趋向于最优解。但是每一次更新参数利用多少误差,就需要通过一个参数来控制,这个参数就是学习率(Learning rate),也称为步长。

以上部分是10月25号写的,昨天满课,没时间写。今天早上10点的课,同门都8点就来实验室学习,卷的我好害怕O.o
import torch
import torchvision
import torch.nn as nn
from model import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
#def main():
transform = transforms.Compose(#transform函数对图像进行预处理 compose:将下面两个函数打包成一个整体
[transforms.ToTensor(),#Totensor函数 将H*W*C转换为C*H*W 并将像素值转换成0到1之间
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])#Normalize函数 标准化 使用均值和标准差来标准化这个tensor
#标准化处理:output = (input-0.5)/0.5
#反标准化处理: input = output/2+0.5
# # 50000张训练图片
# # 第一次使用时要将download设置为True才会自动去下载数据集 下载完之后设置为False
train_set = torchvision.datasets.CIFAR10(root='./data', train=True,#train=true 导入cifar10训练集的样本
download=False, transform=transform)#transform 是对图像进行预处理的一个函数
train_loader = torch.utils.data.DataLoader(train_set, batch_size=36,#将训练集导入进来,然后分成一个批次一个批次的,每一批拿出36张图片进行训练
shuffle=True, num_workers=0)#shuffle是否将数据集进行一个打乱 num_works载入数据的线程数win系统里面只能设置为0,不然报错
# # 10000张验证图片 测试集
# # 第一次使用时要将download设置为True才会自动去下载数据集
val_set = torchvision.datasets.CIFAR10(root='./data', train=False,
download=False, transform=transform)
val_loader = torch.utils.data.DataLoader(val_set, batch_size=10000,
shuffle=False, num_workers=0)
val_data_iter = iter(val_loader)#iter函数将参数转换成可迭代的迭代器 测试集
val_image, val_label = val_data_iter.next()#next方法就能够获取一批数据
classes = ('plane', 'car', 'bird', 'cat',#标签 元组类型,值是不能改变的 index 0就代表plane index 1就代表car
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# #展示数据集的图片
# def imshow(img):
# img = img / 2 + 0.5 # unnormalize反标准化处理
# npimg = img.numpy()
# plt.imshow(np.transpose(npimg, (1, 2, 0)))#因为之前的totensor做了处理c,w,h=0,1,2,现在还原成w,h,c=1,2,0
# plt.show()
# # print labels
# print(' '.join('%5s' % classes[val_label[j]] for j in range(4)))
# # show images
# imshow(torchvision.utils.make_grid(val_image))
net = LeNet()#实例化模型
loss_function = nn.CrossEntropyLoss()#定义损失函数 里面包含了softmax函数和NLL损失函数,所以在网络输出层的时候不需要再添加softmax函数
#Legative Log Likelihood Loss,中文名称是最大似然或者log似然代价函数
optimizer = optim.Adam(net.parameters(), lr=0.001)#优化器 这里使用的就是Adam优化器 net.parameter就是将LeNet所有可训练的参数都进行训练 lr代表的是learning rate学习率
for epoch in range(5): # loop over the dataset multiple times 会将训练集迭代5次
running_loss = 0.0#用来累加训练过程中的一些损失
for step, data in enumerate(train_loader, start=0):#遍历训练集样本 enumerate(枚举)函数不仅返回每一批的数据data 它还会返回data的步数index ,循环从0开始
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data#得到数据之后,将它分为inputs,即输入的图像,还有对应的标签
# zero the parameter gradients
optimizer.zero_grad()#zero_grad函数的作用是将历史损失梯度给清0
# forward + backward + optimize
outputs = net(inputs)#将图片输入到网络进行正向传播,得到输出
loss = loss_function(outputs, labels)#计算损失,output是网络预测的值,labels是真实标签
loss.backward()#然后将损失进行反向传播
optimizer.step()#通过优化器的step函数进行参数的更新
# print statistics
running_loss += loss.item()#每当计算完损失之后,就累加到running_loss这个变量里面来
if step % 500 == 499: # print every 500 mini-batches 每隔500步就打印一次数据的信息
with torch.no_grad(): #with是一个上下文管理器 在接下来的计算中,不用去计算误差损失梯度
outputs = net(val_image) # [batch, 10] 正向传播
predict_y = torch.max(outputs, dim=1)[1]# 寻找输出最大的index在什么位置 (网络预测最可能归于哪个类别) 维度为1(输出的10个节点)维度为0对应的是batch [1]表示只输出index值,就是它在哪个位置
accuracy = torch.eq(predict_y, val_label).sum().item() / val_label.size(0)
#将预测的标签类别和真实的标签类别进行比较 在相同的地方返回true(1) 不同的地方返回false(0) 然后通过sum函数知道本次预测中预测到了多少个样本
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, step + 1, running_loss / 500, accuracy))#这几个参数分别是第几轮,多少步,训练过程中累加的损失(500步当中平均的训练误差),测试样本的准确率
running_loss = 0.0# 将running_loss清零 来进行下一个500步的计算
print('Finished Training')
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)#save函数来将网络的参数进行保存
# if __name__ == '__main__':
# main()
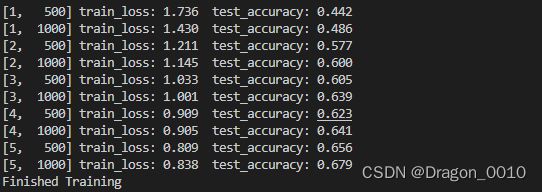
这个是训练结果,作为几十年前的网络,有68%的精度已经不错了
接下来找一张图片来测试网络模型,输出图片的类别

下面是预测模块的代码
#predict 就是调用模型权重进行预测的脚本
import torch
import torchvision.transforms as transforms
from PIL import Image
from model import LeNet
def main():
transform = transforms.Compose(
[transforms.Resize((32, 32)),#将下载的图片转换为32*32大小 因为LeNet模型里面就是32*32大小
transforms.ToTensor(),#totensor 转换为c h w
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
net = LeNet()
net.load_state_dict(torch.load('Lenet.pth'))#载入权重文件
im = Image.open('1.jpg')
im = transform(im) # [C, H, W]
im = torch.unsqueeze(im, dim=0) # [N, C, H, W] unsqueeze函数的作用是增加一个新的维度batch
with torch.no_grad():#不需要求损失梯度
outputs = net(im)
predict = torch.max(outputs, dim=1)[1].numpy()#可能性最高的类别索引
print(classes[int(predict)])#索引对应的类别
if __name__ == '__main__':
main()
预测结果
