神经网络笔记一:Non-stationary Transformers: Exploring the Stationarity in Time Series Forecasting
摘要
现在Transformer在时间序列预测上发挥巨大作用,但对于非平稳的现实时间序列表现并不好。之前的一些研究着重在于将时间序列平稳化,这样的方法减弱了对突发事件的预测,同时在时间序列预测方面的效果下降。本文称之为过度平稳化(over-stationarization),即Transformer对于不同的时间序列产生了相似的Attention,减弱了模型预测能力。针对这种现象,本文进而提出了Non-stationary Transformers框架,其中包含两个模块:
分别是序列平稳化模块(Series Stationarization)以及逆平稳化模块(De-stationary Attention)。序列平稳化模块之中,本文将模块输入的数据的统计量与模块输出结合。逆平稳化模块则设计为从不同时间序列中习得不同Attention,利用这些Attention恢复时间序列固有的非平稳性。
时间序列的非平稳性:时间序列的统计特征和联合分布随着时间变化而变化,非平稳性使得时间序列更加不可预测。
上图为三段不平稳时间序列的Attention的可视化图。我们可以看到在本文的模型中,不平稳时间序列的Attention能够产生明显的差异,说明不平稳时间序列本身的固有属性能够帮助我们进行预测。而Over stationarization问题就是将时间序列平稳化,而没有利用到非平稳序列的固有属性。
本文贡献
- 发现了非平稳时间序列的预测能力,以及现有平稳化方法造成的过平稳化问题。
- 提出了Non-stationary Transformers 避免过平稳化的现象。
- Non-stationary Transformers 在六个基准上,超过了四个现今主流的Transformer模型。
Non-stationary Transformers
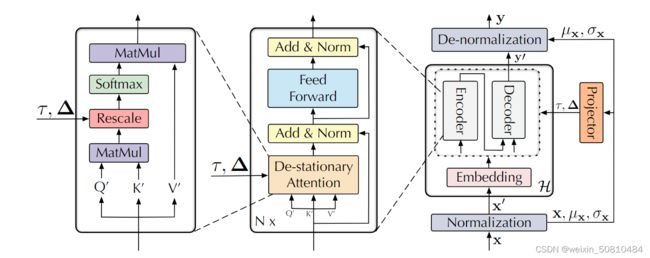
1 Series Stationarization
1.1 Normalization module
class MyDataset(Dataset):
...
def __getitem__(self,index):
s_begin = index
#其中S就是seq_len
s_end = s_begin + self.seq_len
# seq_x[0,0]的长度为C
seq_x = self.data_x[s_begin:s_end]
seq_y = self.data_y[s_begin:s_end]
return(seq_x,seq_y)
通过移动窗口的方式得 S S S长度的序列,每个序列具有 C C C长度的特征。
μ x = 1 S ∑ i = 1 S x i , σ x 2 = 1 S ∑ i = 1 S ( x i − μ x ) 2 , x i ′ = 1 σ x ⊙ ( x i − μ x ) \mu_x = \frac{1}{S}\sum_{i=1}^{S}x_i,\sigma_x^2 = \frac{1}{S}\sum_{i=1}^{S}(x_i-\mu_x)^2,x_i^{'}=\frac{1}{\sigma_x} \odot(x_i-\mu_x) μx=S1i=1∑Sxi,σx2=S1i=1∑S(xi−μx)2,xi′=σx1⊙(xi−μx)
其中 x = [ x 1 , x 2 , . . . , x S ] T ∈ R S × C , x ′ = [ x 1 ′ , x 2 ′ , . . . , x S ′ ] T ∈ R S × C x=[x_1,x_2,...,x_S]^{T} \in\mathbb R^{S\times C},x^{'}=[x_1^{'},x_2^{'},...,x_S^{'}]^{T} \in\mathbb R^{S\times C} x=[x1,x2,...,xS]T∈RS×C,x′=[x1′,x2′,...,xS′]T∈RS×C, S S S 和 C C C 分别是序列的长度和变量个数。
1.2 De-normalization module
在经过整个模型 H H H后,可以得到O长度的向量 y ′ = [ y 1 ′ , y 2 ′ , . . . , y O ′ ] y^{'} = [y_1^{'},y_2^{'},...,y_O^{'}] y′=[y1′,y2′,...,yO′],将其利用先前计算的 σ x , μ x \sigma_x,\mu_x σx,μx进行标准化逆变换,我们可以得到 y ^ = [ y ^ 1 , y ^ 2 , . . . , y ^ O ] \hat{y}=[\hat{y}_1,\hat{y}_2,...,\hat{y}_O] y^=[y^1,y^2,...,y^O].这个过程可以总结为以下公式: y ′ = H ( x ′ ) , y ^ i = σ x ⊙ ( y i ′ + μ x ) y^{'}=H(x^{'}),\hat{y}_{i}=\sigma_x\odot(y_i^{'}+\mu_x) y′=H(x′),y^i=σx⊙(yi′+μx)
1.3 De-stationary Attention
我们仅仅通过1.2中的逆标准化,并没法还原时间序列的非平稳性,所以要通过模型内部更加复杂的机制实现这件事情。为了实现这个事情,我们利用De-stationary Attention 机制去获得原始非平稳数据的时间相依关系。
1.3.1对一般模型的分析
从Self-Attention 开始: A t t n ( Q , K , V ) = S o f t m a x ( Q K T d k ) V Attn(Q,K,V)=Softmax(\frac{QK^{T}}{\sqrt{d_k}})V Attn(Q,K,V)=Softmax(dkQKT)V
其中 Q , K , V ∈ R S × d k Q,K,V\in\mathbb R^{S\times d_k} Q,K,V∈RS×dk 。输入数据为 x = [ x 1 , x 2 , . . . , x S ] T x=[x_1,x_2,...,x_S]^{T} x=[x1,x2,...,xS]T,并且 Q = [ q 1 , q 2 , . . . , q S ] T = [ f ( x 1 ) , f ( x 2 ) , . . . , f ( x S ) ] T Q=[q_1,q_2,...,q_S]^{T}=[f(x_1),f(x_2),...,f(x_S)]^{T} Q=[q1,q2,...,qS]T=[f(x1),f(x2),...,f(xS)]T。通过标准化后, x ′ = [ x 1 ′ , x 2 ′ , . . . , x S ′ ] T = ( x − 1 μ x T ) / σ x , Q ′ = [ q 1 ′ , q 2 ′ , . . . , q S ′ ] T = [ f ( x 1 ′ ) , f ( x 2 ′ ) , . . . , f ( x S ′ ) ] T x^{'}=[x_1^{'},x_2^{'},...,x_S^{'}]^{T}=(x-1\mu_x^{T})/\sigma_x,Q^{'}=[q_1^{'},q_2^{'},...,q_S^{'}]^{T}=[f(x_1^{'}),f(x_2^{'}),...,f(x_S^{'})]^{T} x′=[x1′,x2′,...,xS′]T=(x−1μxT)/σx,Q′=[q1′,q2′,...,qS′]T=[f(x1′),f(x2′),...,f(xS′)]T。假设 f f f是线性函数, Q ′ = ( Q − 1 μ Q T ) / σ x Q^{'}=(Q-1\mu_Q^{T})/\sigma_x Q′=(Q−1μQT)/σx。同样的我们对于 K ′ , V ′ K^{'},V^{'} K′,V′有类似的结果。可以得到以下结果:
Q ′ K ′ T = ( Q − 1 μ Q T ) / σ x [ ( K − 1 μ K T ) / σ x ] T = 1 σ x 2 ( Q K T − 1 ( μ Q T K T ) − ( Q μ K ) 1 T + 1 ( μ Q T μ K ) 1 T ) Q^{'}K^{'T}=(Q-1\mu_Q^{T})/\sigma_x[(K-1\mu_K^{T})/\sigma_x]^{T}\\=\frac{1}{\sigma_x^{2}}(QK^{T}-1(\mu_Q^{T}K^{T})-(Q\mu_K)1^{T}+1(\mu_Q^{T}\mu_K)1^{T}) Q′K′T=(Q−1μQT)/σx[(K−1μKT)/σx]T=σx21(QKT−1(μQTKT)−(QμK)1T+1(μQTμK)1T)
S o f t m a x ( Q K T ) = S o f t m a x ( σ x 2 Q ′ K ′ T + 1 ( μ Q T K T ) + ( Q μ K ) 1 T − 1 ( μ Q T μ K ) 1 T d k ) Softmax(QK^{T}) = Softmax(\frac{\sigma^2_x Q^{'} K^{'T}+1(\mu_Q^T K^T)+(Q\mu_K)1^T-1(\mu_Q^T\mu_K)1^T}{\sqrt{d_k}}) Softmax(QKT)=Softmax(dkσx2Q′K′T+1(μQTKT)+(QμK)1T−1(μQTμK)1T)
因为 μ Q T μ K \mu_Q^T\mu_K μQTμK是常数, ( Q μ K ) 1 T (Q\mu_K)1^T (QμK)1T每一列都相同故可化简为以下形式
S o f t m a x ( Q K T ) = S o f t m a x ( σ x 2 Q ′ K ′ T + 1 ( μ Q T K T ) d k ) Softmax(QK^{T}) = Softmax(\frac{\sigma^2_x Q^{'} K^{'T}+1(\mu_Q^T K^T)}{\sqrt{d_k}}) Softmax(QKT)=Softmax(dkσx2Q′K′T+1(μQTKT))
S o f t m a x ( Q K T ) Softmax(QK^{T}) Softmax(QKT)从非平稳序列 x x x可以直接算出,从式子可以看出原序列的信息不仅仅包含平稳化后的信息 Q ′ , K ′ Q^{'},K^{'} Q′,K′,而且包括 σ x , μ Q , K \sigma_x,\mu_Q,K σx,μQ,K等非平稳序列的信息。
1.3.2 De-stationary Attention
为了恢复初始的Attention,即 S o f t m a x ( Q K T ) Softmax(QK^{T}) Softmax(QKT),我们需要得到 σ X 2 , Δ = K μ Q ∈ R S × 1 \sigma_X^2,\Delta=K\mu_Q\in\mathbb R^{S\times1} σX2,Δ=KμQ∈RS×1。我们将这些所需量,定义为逆平稳因子(de-stationary factors)。值得注意的是,我们先前对 f f f的线性假设,通常是不成立的,因此我们要从 x , Q , K x,Q,K x,Q,K学习到相应的逆平稳因子。我们对De-stationary Attention的定义如下:
l o g τ = M L P ( σ x , x ) , Δ = M L P ( μ x , x ) , A t t n ( Q ′ , K ′ , V ′ , τ , Δ ) = S o f t m a x ( τ Q ′ K ′ T + 1 Δ T d k ) V ′ log\tau = MLP(\sigma_x,x),\Delta = MLP(\mu_x,x),\\Attn(Q^{'},K^{'},V^{'},\tau,\Delta)=Softmax(\frac{\tau Q^{'} K^{'T}+1\Delta^T}{\sqrt{d_k}})V^{'} logτ=MLP(σx,x),Δ=MLP(μx,x),Attn(Q′,K′,V′,τ,Δ)=Softmax(dkτQ′K′T+1ΔT)V′
代码实现
Nonstationary_Transformers