积跬步至千里 || Python 常用的结构化数据读取方法
Python 读取常用的结构化数据及基本操作
文章目录
- Python 读取常用的结构化数据及基本操作
-
- 1. pandas 读取 excel 文件
- 2. pandas 读取 csv 文件
- 3. pandas 读取 txt 文件
- 4. 利用 scipy 读取 mat 格式文件数据
结构化数据也称作行数据,是由二维表结构来逻辑表达和实现的数据,严格地遵循数据格式与长度规范,主要通过关系型数据库进行存储和管理。与其对应的是非结构化数据,如语音、文本、图像、视频等。
结构化数据是普通的数据分析经常用到的数据类型,其本地存储的文件格式又有所不同,如 excel、csv、txt 等。下面我们将介绍三种常用的数据文件Python pandas 库读取方式。
1. pandas 读取 excel 文件
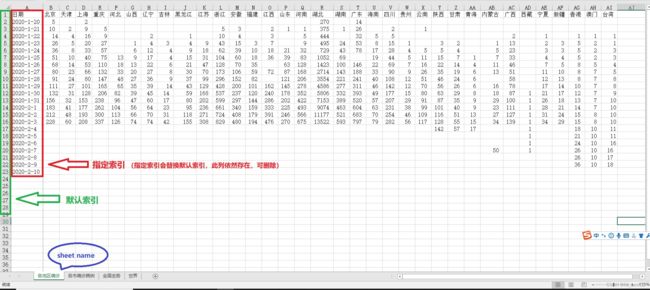
import numpy as np
import pandas as pd
#读取疫情数据、数据格式变换
df = pd.read_excel('data/01感染人数分布数据.xlsx',sheet_name='各地区确诊')#读取历史疫情数据
df.index = df['日期'] #修改索引值为日期
df1 = df.drop(['日期'], axis=1)#删除多余日期列
df1
2. pandas 读取 csv 文件
import pandas as pd
df = pd.read_csv('data/sanya12345.csv',index_col=0)#读取数据
print(df.info())
‘’‘
<class 'pandas.core.frame.DataFrame'>
Int64Index: 184568 entries, 125282 to 127953
Data columns (total 20 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 orderAll 184568 non-null float64
1 order 184568 non-null float64
2 工单编号 184568 non-null int64
3 工单分类 184567 non-null object
4 工单来源 184567 non-null object
5 来电时间 184567 non-null object
6 来电类型 184567 non-null object
7 工单标题 184567 non-null object
8 工单内容 184567 non-null object
9 工单状态 184567 non-null object
10 是否延期 184568 non-null object
11 序号 183977 non-null float64
12 处理时间 184567 non-null object
13 处理环节 184567 non-null object
14 处理单位 184179 non-null object
15 处理描述 184567 non-null object
16 extractAddress 131264 non-null object
17 lon84 126785 non-null float64
18 lat84 126785 non-null float64
19 cluster 184568 non-null int64
dtypes: float64(5), int64(2), object(13)
memory usage: 29.6+ MB
None
’‘’
3. pandas 读取 txt 文件
pandas 读取的数据类型为 DataFrame (或 Series),可通过 .values 操作提取 ndarray 形式.
import numpy as np
import pandas as pd
mat = pd.read_table('data/matrix_data.txt',header=None,sep=',')
print('读入数据为:\n',mat)
print('\n\n转化为 ndarray 类型: \n',mat.values)
'''
读入数据为:
0 1 2 3 4
0 0 1 2 3 4
1 5 6 7 8 9
2 10 11 12 13 14
转化为 ndarray 类型:
[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]]
'''
4. 利用 scipy 读取 mat 格式文件数据
Matlab 常用的数据格式为 .mat 格式, python 中可通过 scipy.io 函数库进行读取, 但是读取格式不是一个矩阵,而是一个字典类型, 需要通过字典中的键-值进行提取
import scipy.io as sio
gt_mat = sio.loadmat('data/data.mat') # 读取的数据格式为字典类型
gt_mat
‘’‘
{'__header__': b'MATLAB 5.0 MAT-file, Platform: MACI64, Created on: \xe4\xba\x8c 11 15 18:53:59 2022',
'__version__': '1.0',
'__globals__': [],
'A': array([[-1.3076883 , 3.57839694, 3.03492347, 0.7147429 , 1.48969761],
[-0.43359202, 2.76943703, 0.72540422, -0.20496606, 1.40903449],
[ 0.34262447, -1.34988694, -0.06305487, -0.12414435, 1.41719241]])}
’‘’
gt_mat.keys() # 查看字典的键
‘’‘
dict_keys(['__header__', '__version__', '__globals__', 'A'])
’‘’
gt_mat['A'] # 通过字典的键提取字典相应的值,即可显示为 adarray 格式的矩阵
‘’‘
array([[-1.3076883 , 3.57839694, 3.03492347, 0.7147429 , 1.48969761],
[-0.43359202, 2.76943703, 0.72540422, -0.20496606, 1.40903449],
[ 0.34262447, -1.34988694, -0.06305487, -0.12414435, 1.41719241]])
’‘’