Pytorch学习笔记(11)———迁移学习Transfer Learning
在训练深度学习模型时,有时候我们没有海量的训练样本,只有少数的训练样本(比如几百个图片),几百个训练样本显然对于深度学习远远不够。这时候,我们可以使用别人预训练好的网络模型权重,在此基础上进行训练,这就引入了一个概念——迁移学习(Transfer Learning)。
什么是迁移学习
迁移学习(Transfer Learning,TL)对于人类来说,就是掌握举一反三的学习能力。比如我们学会骑自行车后,学骑摩托车就很简单了;在学会打羽毛球之后,再学打网球也就没那么难了。对于计算机而言,所谓迁移学习,就是能让现有的模型算法稍加调整即可应用于一个新的领域和功能的一项技术
如何进行迁移学习
- 首先需要选择一个预训练好的模型,需要注意的是该模型的训练过程最好与我们要进行训练的任务相似。比如我们要训练一个Cat,dog图像分类的模型,最好应该选择一个图像分类的预训练模型。
- 针对实际任务,对网络结构进行调整。比如找到了一个预训练好的AlexNet(1000类别), 但是我们实际的任务的2分类,因此需要把最后一层的全连接输出改为2.
In practice, very few people train an entire Convolutional Network from scratch (with random initialization), because it is relatively rare to have a dataset of sufficient size. Instead, it is common to pretrain a ConvNet on a very large dataset (e.g. ImageNet, which contains 1.2 million images with 1000 categories), and then use the ConvNet either as an initialization or a fixed feature extractor for the task of interest.
作者:侠之大者_7d3f
链接:https://www.jianshu.com/p/d04c17368922
来源:简书
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
ResNet-18

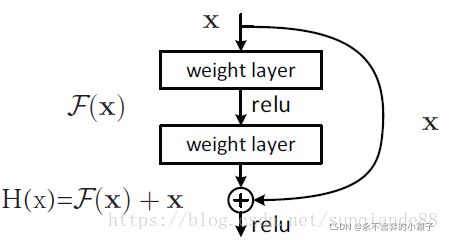
ResNet全名Residual Network残差网络。Kaiming He 的《Deep Residual Learning for Image Recognition》获得了CVPR最佳论文。它在保证网络精度的前提下,将网络的深度达到了152层,后来又进一步加到1000的深度。论文的开篇先是说明了深度网络的好处:特征等级随着网络的加深而变高,网络的表达能力也会大大提高。因此论文中提出了一个问题:是否可以通过叠加网络层数来获得一个更好的网络呢?作者经过实验发现,单纯的把网络叠起来的深层网络的效果反而不如合适层数的较浅的网络效果。因此何恺明等人在普通平原网络的基础上增加了一个shortcut, 构成一个residual block。此时拟合目标就变为F(x),F(x)就是残差:
数据集准备
- 训练集
- 验证集
训练集,验证集 分别包含2个子文件夹,这是一个2分类问题。分类对象:蚂蚁,蜜蜂



- 代码
因为训练一个2分类的模型,数据集加载直接使用pytorch提供的API——ImageFolder最方便。原始图像为jpg格式,在制作数据集时候进行了变换transforms。 加入对GPU的支持,首先判断torch.cuda.is_available(),然后决定使用GPU or CPU
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
from torch.utils.data import DataLoader
import torchvision
from torchvision.transforms import transforms
from torchvision import models
from torchvision.models import ResNet
import numpy as np
import matplotlib.pyplot as plt
import os
import utils
data_dir = './data/hymenoptera_data'
train_dataset = torchvision.datasets.ImageFolder(root=os.path.join(data_dir, 'train'),
transform=transforms.Compose(
[
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(
mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225))
]))
val_dataset = torchvision.datasets.ImageFolder(root=os.path.join(data_dir, 'val'),
transform=transforms.Compose(
[
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(
mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225))
]))
train_dataloader = DataLoader(dataset=train_dataset, batch_size=4, shuffle=4)
val_dataloader = DataLoader(dataset=val_dataset, batch_size=4, shuffle=4)
# 类别名称
class_names = train_dataset.classes
print('class_names:{}'.format(class_names))
# 训练设备 CPU/GPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('trian_device:{}'.format(device.type))
# 随机显示一个batch
plt.figure()
utils.imshow(next(iter(train_dataloader)))
plt.show()
获取预训练模型
torchvision.models
torchvision中包含了一些常见的预训练模型

AlexNet, VGG, SqueezeNet, Resnet,Inception, DenseNet
此次实验采用ResNet18网络模型。
在torchvision.models中包含resnet18,首先会实例化一个ResNet网络, 然后model.load_dict()加载预训练好的模型。
def resnet18(pretrained=False, **kwargs):
"""Constructs a ResNet-18 model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = ResNet(BasicBlock, [2, 2, 2, 2], **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['resnet18']))
return model
torchvision 默认将模型保存在/home/.torch/models路径。

预训练模型文件:
- 代码
加载预训练模型。需要注意的地方:修改ResNet最后一个全连接层的输出个数,二分类问题需要将输出个数改为2。
# -------------------------模型选择,优化方法, 学习率策略----------------------
model = models.resnet18(pretrained=True)
# 全连接层的输入通道in_channels个数
num_fc_in = model.fc.in_features
# 改变全连接层,2分类问题,out_features = 2
model.fc = nn.Linear(num_fc_in, 2)
# 模型迁移到CPU/GPU
model = model.to(device)
# 定义损失函数
loss_fc = nn.CrossEntropyLoss()
# 选择优化方法
optimizer = optim.SGD(model.parameters(), lr=0.0001, momentum=0.9)
# 学习率调整策略
# 每7个epoch调整一次
exp_lr_scheduler = lr_scheduler.StepLR(optimizer=optimizer, step_size=10, gamma=0.5) # step_size
训练,测试网络
Epoch: 训练50个epoch
注意地方: 训练时候,需要调用model.train()将模型设置为训练模式。测试时候,调用model.eval() 将模型设置为测试模型,否则训练和测试结果不正确。
# ----------------训练过程-----------------
num_epochs = 50
for epoch in range(num_epochs):
running_loss = 0.0
exp_lr_scheduler.step()
for i, sample_batch in enumerate(train_dataloader):
inputs = sample_batch[0]
labels = sample_batch[1]
model.train()
# GPU/CPU
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
# foward
outputs = model(inputs)
# loss
loss = loss_fc(outputs, labels)
# loss求导,反向
loss.backward()
# 优化
optimizer.step()
#
running_loss += loss.item()
# 測試
if i % 20 == 19:
correct = 0
total = 0
model.eval()
for images_test, labels_test in val_dataloader:
images_test = images_test.to(device)
labels_test = labels_test.to(device)
outputs_test = model(images_test)
_, prediction = torch.max(outputs_test, 1)
correct += (torch.sum((prediction == labels_test))).item()
# print(prediction, labels_test, correct)
total += labels_test.size(0)
print('[{}, {}] running_loss = {:.5f} accurcay = {:.5f}'.format(epoch + 1, i + 1, running_loss / 20,
correct / total))
running_loss = 0.0
# if i % 10 == 9:
# print('[{}, {}] loss={:.5f}'.format(epoch+1, i+1, running_loss / 10))
# running_loss = 0.0
print('training finish !')
torch.save(model.state_dict(), './model/model_2.pth')
完整代码
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim import lr_scheduler
from torch.utils.data import DataLoader
import torchvision
from torchvision.transforms import transforms
from torchvision import models
from torchvision.models import ResNet
import numpy as np
import matplotlib.pyplot as plt
import os
import utils
data_dir = './data/hymenoptera_data'
train_dataset = torchvision.datasets.ImageFolder(root=os.path.join(data_dir, 'train'),
transform=transforms.Compose(
[
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(
mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225))
]))
val_dataset = torchvision.datasets.ImageFolder(root=os.path.join(data_dir, 'val'),
transform=transforms.Compose(
[
transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(
mean=(0.485, 0.456, 0.406),
std=(0.229, 0.224, 0.225))
]))
train_dataloader = DataLoader(dataset=train_dataset, batch_size=4, shuffle=4)
val_dataloader = DataLoader(dataset=val_dataset, batch_size=4, shuffle=4)
# 类别名称
class_names = train_dataset.classes
print('class_names:{}'.format(class_names))
# 训练设备 CPU/GPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('trian_device:{}'.format(device.type))
# 随机显示一个batch
#plt.figure()
#utils.imshow(next(iter(train_dataloader)))
#plt.show()
# -------------------------模型选择,优化方法, 学习率策略----------------------
model = models.resnet18(pretrained=True)
# 全连接层的输入通道in_channels个数
num_fc_in = model.fc.in_features
# 改变全连接层,2分类问题,out_features = 2
model.fc = nn.Linear(num_fc_in, 2)
# 模型迁移到CPU/GPU
model = model.to(device)
# 定义损失函数
loss_fc = nn.CrossEntropyLoss()
# 选择优化方法
optimizer = optim.SGD(model.parameters(), lr=0.0001, momentum=0.9)
# 学习率调整策略
# 每7个epoch调整一次
exp_lr_scheduler = lr_scheduler.StepLR(optimizer=optimizer, step_size=10, gamma=0.5) # step_size
# ----------------训练过程-----------------
num_epochs = 50
for epoch in range(num_epochs):
running_loss = 0.0
exp_lr_scheduler.step()
for i, sample_batch in enumerate(train_dataloader):
inputs = sample_batch[0]
labels = sample_batch[1]
model.train()
# GPU/CPU
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
# foward
outputs = model(inputs)
# loss
loss = loss_fc(outputs, labels)
# loss求导,反向
loss.backward()
# 优化
optimizer.step()
#
running_loss += loss.item()
# 測試
if i % 20 == 19:
correct = 0
total = 0
model.eval()
for images_test, labels_test in val_dataloader:
images_test = images_test.to(device)
labels_test = labels_test.to(device)
outputs_test = model(images_test)
_, prediction = torch.max(outputs_test, 1)
correct += (torch.sum((prediction == labels_test))).item()
# print(prediction, labels_test, correct)
total += labels_test.size(0)
print('[{}, {}] running_loss = {:.5f} accurcay = {:.5f}'.format(epoch + 1, i + 1, running_loss / 20,
correct / total))
running_loss = 0.0
# if i % 10 == 9:
# print('[{}, {}] loss={:.5f}'.format(epoch+1, i+1, running_loss / 10))
# running_loss = 0.0
print('training finish !')
torch.save(model.state_dict(), './model/model_2.pth')
链接:https://www.jianshu.com/p/d04c17368922
链接:https://blog.csdn.net/sunqiande88/article/details/80100891