【论文笔记7】CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classificatio阅读笔记
系列文章目录
论文阅读笔记 (1):DeepLabv3
论文阅读笔记 (2) :STA手势识别
论文阅读笔记 (3): ST-GCN
论文阅读笔记(5):图上的光谱网路和深度局部链接网络
论文阅读笔记(6): GNN-快速局部光谱滤波
论文阅读笔记(8): 图卷积半监督分类
文章目录
- 系列文章目录
- Abstract
-
- 目标
- 方法
- 一、Introduction
-
- 1. 相关论文:
- 2. 本文特点
- 二、Related Works
-
- 三种类别的相关工作
- 三、Method
-
- 1.Vision Transformer
-
- Multi-Head Attention:
- 流程:
- 2.Proposed Multi-Scale Vision Transformer
- 3.Multi-Scale Feature Fusion
-
- 提出了备选的四种融合策略:
- 四种融合策略的数学表达
- 四、Experiments
-
-
- 模型结构参数:
- 与DeiT 进行比较:
- 与其他类型transformer比较:
-
- 与其他CNN 架构比较
-
-
- 消融实验:
- 附录:训练过程中其他设置
-
Abstract
目标
Inspired by this, in this paper, we study how to learn multi-scale feature rep- resentations in transformer models for image classification. To this end, we propose a dual-branch transformer to combine image patches (i.e., tokens in a transformer) of different sizes to produce stronger image features.
在transformer 中引入多尺度特征的问题。
方法
Our approach processes small-patch and large-patch tokens with two separate branches of different computational complexity and these tokens are then fused purely by attention multiple times to complement each other. 我们的方法处理具有不同计算复杂度的两个独立分支的小块标记和大块标记,然后通过多次纯粹的注意力融合这些标记,使之相互补充。Furthermore, to reduce computation, we develop a simple yet effective token fusion module based on cross attention.Our proposed cross-attention only requires linear time for both computational and memory complexity instead ofquadratic time otherwise.
- github: 链接
一、Introduction
1. 相关论文:
- Octave convolutions
- BigLittle Net
- 其他一些transformer 结构。
前两篇主要设计多尺度信息融合问题,也是本文的motivation。
2. 本文特点
- Our approach processes small and large patch tokens with two separate branches of different computational complexities and these tokens are fused together multiple times to complement each other.
- 用两个分支来交换不同大小的patch tokens,两个分支大小的计算量不同,并且交换信息次数是多次的。
- We do so by an efficient cross-attention module, in which each transformer branch creates a non-patch token as an agent to exchange information with the other branch by attention.
- 用一个cross-attention 的模块来实现。
- 减少了计算量,提高了性能,具体实现后边看。
二、Related Works
三种类别的相关工作
- convolutional neural networks with attention.
- SENet [18] uses channel-attention, CBAM [41] adds the spatial attention and ECANet [37] proposes an effi- cient channel attention to further improve SENet. There has also been a lot of interest in combining CNNs with different forms of self-attention
- SASA [31] and SAN [48] deploy a local-attention layer to replace convolutional layer.
- LambdaNetwork introduces an efficient global attention to model both con- tent and position-based interactions that considerably im- proves the speed-accuracy tradeoff of image classification models.BoTNet [32] replaced the spatial convolutions with global self-attention in the final three bottleneck blocks of a ResNet resulting in models that achieve a strong perfor- mance for image classificatio.
- 与上边这些方法不同,本文的方法不是hybird of cnn and attention. 纯的transformer.
- Vision Transformers
- Multi-Scale Cnns
三、Method
1.Vision Transformer

Multi-Head Attention:
其中的Multi-Head Attention 结构为:

Attention ( Q , K , V ) = softmax ( Q K T d k ) V \operatorname{Attention}(Q, K, V)=\operatorname{softmax}\left(\frac{Q K^{T}}{\sqrt{d_{k}}}\right) V Attention(Q,K,V)=softmax(dkQKT)V
其中的QKV 论文attention is all u need 中有解释。
MultiHead ( Q , K , V ) = Concat ( head 1 , … , head h ) where head = Attention ( Q W i Q , K W i K , V W i V ) \begin{aligned} \operatorname{MultiHead}(Q, K, V) &=\operatorname{Concat}\left(\operatorname{head}_{1}, \ldots, \text { head }_{\mathrm{h}}\right) \\ \text { where head } &=\operatorname{Attention}\left(Q W_{i}^{Q}, K W_{i}^{K}, V W_{i}^{V}\right) \end{aligned} MultiHead(Q,K,V) where head =Concat(head1,…, head h)=Attention(QWiQ,KWiK,VWiV)
其中 W i Q ∈ R d model × d k , W i K ∈ R d model × d k W_{i}^{Q} \in \mathbb{R}^{d_{\text {model }} \times d_{k}}, W_{i}^{K} \in \mathbb{R}^{d_{\text {model }} \times d_{k}} WiQ∈Rdmodel ×dk,WiK∈Rdmodel ×dk,而 W i V ∈ d model × d v W_{i}^{V}\in d_{\text {model }} \times d_{v} WiV∈dmodel ×dv
流程:
z 0 = [ x class ; x p 1 E ; x p 2 E ; ⋯ ; x p N E ] + E pos , E ∈ R ( P 2 ⋅ C ) × D , E p o s ∈ R ( N + 1 ) × D z ℓ ′ = MSA ( LN ( z ℓ − 1 ) ) + z ℓ − 1 , ℓ = 1 … L z ℓ = MLP ( LN ( z ℓ ′ ) ) + z ℓ ′ , ℓ = 1 … L y = LN ( z L 0 ) \begin{aligned} \mathbf{z}_{0} &=\left[\mathbf{x}_{\text {class }} ; \mathbf{x}_{p}^{1} \mathbf{E} ; \mathbf{x}_{p}^{2} \mathbf{E} ; \cdots ; \mathbf{x}_{p}^{N} \mathbf{E}\right]+\mathbf{E}_{\text {pos }}, & & \mathbf{E} \in \mathbb{R}^{\left(P^{2} \cdot C\right) \times D}, \mathbf{E}_{p o s} \in \mathbb{R}^{(N+1) \times D} \\ \mathbf{z}_{\ell}^{\prime} &=\operatorname{MSA}\left(\operatorname{LN}\left(\mathbf{z}_{\ell-1}\right)\right)+\mathbf{z}_{\ell-1}, & & \ell=1 \ldots L \\ \mathbf{z}_{\ell} &=\operatorname{MLP}\left(\operatorname{LN}\left(\mathbf{z}_{\ell}^{\prime}\right)\right)+\mathbf{z}_{\ell}^{\prime}, & & \ell=1 \ldots L \\ \mathbf{y} &=\operatorname{LN}\left(\mathbf{z}_{L}^{0}\right) & & \end{aligned} z0zℓ′zℓy=[xclass ;xp1E;xp2E;⋯;xpNE]+Epos ,=MSA(LN(zℓ−1))+zℓ−1,=MLP(LN(zℓ′))+zℓ′,=LN(zL0)E∈R(P2⋅C)×D,Epos∈R(N+1)×Dℓ=1…Lℓ=1…L
2.Proposed Multi-Scale Vision Transformer
Cross VIT:
重点是Cross-Attention 这个模块。
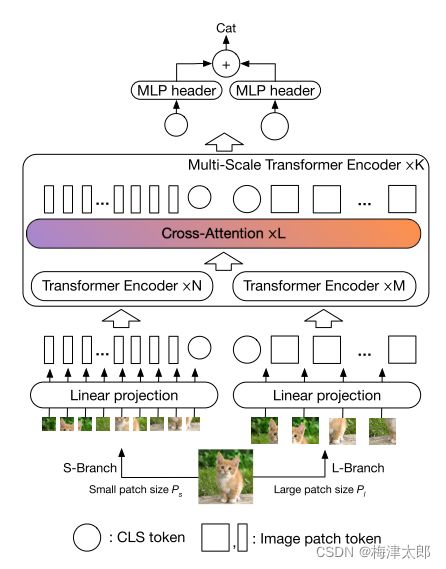
- L-Branch: a large (primary) branch that utilizes coarse-grained patch size (Pl) with more trans- former encoders and wider embedding dimensions
- 大块,多头,更宽的通道的编码器。
- S- Branch: a small (complementary) branch that operates at fine-grained patch size (Ps) with fewer encoders and smaller embedding dimensions.
3.Multi-Scale Feature Fusion
提出了备选的四种融合策略:

四种融合策略的数学表达
- All-Attention Fusion:
其实就是将全部的token 并列起来,送入编码器进行融合,计算量会是分支方式平方倍。

- Class Token Fusion
只对分类token 进行融合,计算量会少很多,并且之后两个分支的信息会通过cls Token 进行交叉

- Pairvise Fusion
两个分支相对应的token 进行配对,因为分块方式不同,所以token数量不同,可能需要插值补充。
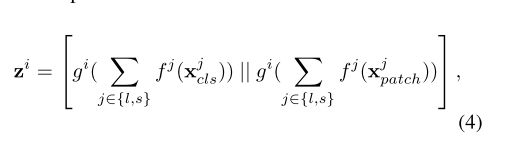
- Cross Attention Fusion

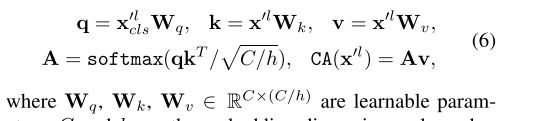
其中三个权重参数境地维度的目的,而且因为只计算CLS的q,所以这部分计算量只是分支倍数,而不是分支的平方倍数。相较于完整的 MHA 少不少。
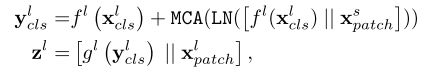
实验中表名,最后一种方式结果最好。
四、Experiments
Therefore, in our experiments, we build our models based on DeiT<\font>
文中的意思是实现是基于DeiT, 而不是VIT,因为DeiT 可以从image net 借助一些数据增强的方式来得到较好的结果,而vit 需要数据量大的时候才可以达到与cnn 相当的结果。
- augmentation
- mixup
- cutmix
- random erasing [Random Erasing Data Augmentation.]
- instance repetition [Augment your batch: Improving generalization through instance repetition.]
模型结构参数:

与DeiT 进行比较:

与其他类型transformer比较:

与其他CNN 架构比较

消融实验:

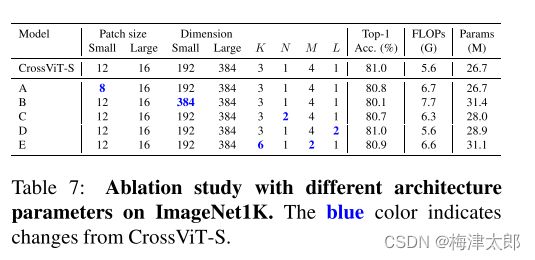
附录:训练过程中其他设置
