2020.8.11-2020.8.16paddle学习心得①
8.11-8.16paddle机器学习笔记
人工智能、机器学习、深度学习的关系

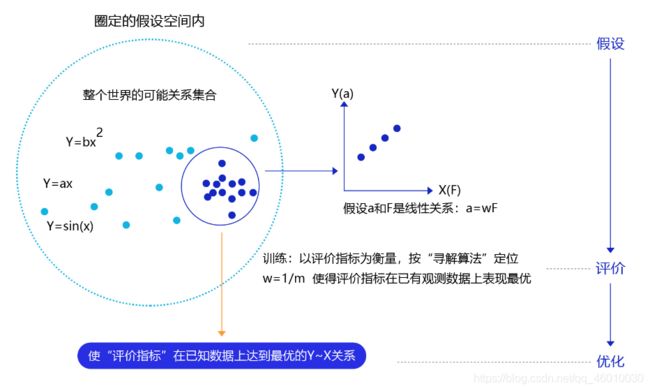
模型假设:世界上的可能关系千千万,漫无目标的试探YYYXXX之间的关系显然是十分低效的。因此假设空间先圈定了一个模型能够表达的关系可能,如蓝色圆圈所示。机器还会进一步在假设圈定的圆圈内寻找最优的YYYXXX关系,即确定参数WWW。
评价函数:寻找最优之前,我们需要先定义什么是最优,即评价一个YYY~XXX关系的好坏的指标。通常衡量该关系是否能很好的拟合现有观测样本,将拟合的误差最小作为优化目标。
优化算法:设置了评价指标后,就可以在假设圈定的范围内,将使得评价指标最优(损失函数最小/最拟合已有观测样本)的YYY~XXX关系找出来,这个寻找的方法即为优化算法。最笨的优化算法即按照参数的可能,穷举每一个可能取值来计算损失函数,保留使得损失函数最小的参数作为最终结果。
神经网络
神经元: 神经网络中每个节点称为神经元,由两部分组成:
加权和:将所有输入加权求和。
非线性变换(激活函数):加权和的结果经过一个非线性函数变换,让神经元计算具备非线性的能力。
多层连接: 大量这样的节点按照不同的层次排布,形成多层的结构连接起来,即称为神经网络。
前向计算: 从输入计算输出的过程,顺序从网络前至后。

波士顿房价预测任务
对于预测问题,可以根据预测输出的类型是连续的实数值,还是离散的标签,区分为回归任务和分类任务。因为房价是一个连续值,所以房价预测显然是一个回归任务。下面我们尝试用最简单的线性回归模型解决这个问题,并用神经网络来实现这个模型。
线性回归模型
假设房价和各影响因素之间能够用线性关系来描述: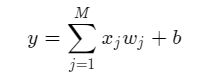
线性回归模型使用均方误差作为损失函数(Loss),用以衡量预测房价和真实房价的差异,公式如下:
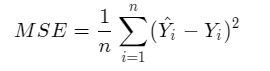
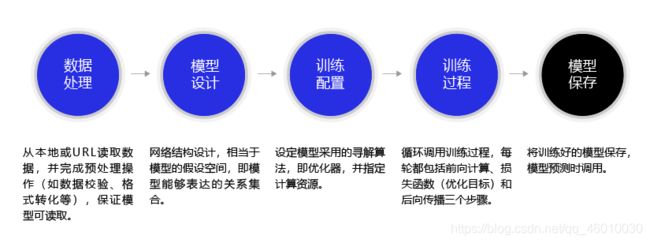
构建波士顿房价预测任务的神经网络模型
读入数据
导入需要用到的package
import numpy as np
import json
#读入训练数据
datafile = ‘./work/housing.data’
data = np.fromfile(datafile, sep=’ ')
数据形状变换
由于读入的原始数据是1维的,所有数据都连在一起。因此需要我们将数据的形状进行变换,形成一个2维的矩阵,每行为一个数据样本(14个值),每个数据样本包含13个X(影响房价的特征)和一个Y(该类型房屋的均价)。
读入之后的数据被转化成1维array,其中array的第0-13项是第一条数据,第14-27项是第二条数据,以此类推…
#这里对原始数据做reshape,变成N x 14的形式
feature_names = [ ‘CRIM’, ‘ZN’, ‘INDUS’, ‘CHAS’, ‘NOX’, ‘RM’, ‘AGE’,‘DIS’,
‘RAD’, ‘TAX’, ‘PTRATIO’, ‘B’, ‘LSTAT’, ‘MEDV’ ]
feature_num = len(feature_names)
data = data.reshape([data.shape[0] // feature_num, feature_num])
#查看数据
x = data[0]
print(x.shape)
print(x)
数据集划分
ratio = 0.8
offset = int(data.shape[0] * ratio)
training_data = data[:offset]
training_data.shape
数据归一化处理
对每个特征进行归一化处理,使得每个特征的取值缩放到0~1之间。这样做有两个好处:一是模型训练更高效;二是特征前的权重大小可以代表该变量对预测结果的贡献度(因为每个特征值本身的范围相同)。
In [ ]
#计算train数据集的最大值,最小值,平均值
maximums, minimums, avgs =
training_data.max(axis=0),
training_data.min(axis=0),
training_data.sum(axis=0) / training_data.shape[0]
#对数据进行归一化处理
for i in range(feature_num):
#print(maximums[i], minimums[i], avgs[i])
data[:, i] = (data[:, i] - minimums[i]) / (maximums[i] - minimums[i])
封装成load data函数
将上述几个数据处理操作封装成load data函数,以便下一步模型的调用,实现方法如下。
def load_data():
# 从文件导入数据
datafile = ‘./work/housing.data’
data = np.fromfile(datafile, sep=’ ')
# 每条数据包括14项,其中前面13项是影响因素,第14项是相应的房屋价格中位数
feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', \
'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]
feature_num = len(feature_names)
# 将原始数据进行Reshape,变成[N, 14]这样的形状
data = data.reshape([data.shape[0] // feature_num, feature_num])
# 将原数据集拆分成训练集和测试集
# 这里使用80%的数据做训练,20%的数据做测试
# 测试集和训练集必须是没有交集的
ratio = 0.8
offset = int(data.shape[0] * ratio)
training_data = data[:offset]
# 计算训练集的最大值,最小值,平均值
maximums, minimums, avgs = training_data.max(axis=0), training_data.min(axis=0), \
training_data.sum(axis=0) / training_data.shape[0]
# 对数据进行归一化处理
for i in range(feature_num):
#print(maximums[i], minimums[i], avgs[i])
data[:, i] = (data[:, i] - minimums[i]) / (maximums[i] - minimums[i])
# 训练集和测试集的划分比例
training_data = data[:offset]
test_data = data[offset:]
return training_data, test_data
#获取数据
training_data, test_data = load_data()
x = training_data[:, :-1]
y = training_data[:, -1:]
#查看数据
print(x[0])
print(y[0])
训练配置
在Network类下面添加损失函数的计算过程如下:
class Network(object):
def init(self, num_of_weights):
# 随机产生w的初始值
# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子
np.random.seed(0)
self.w = np.random.randn(num_of_weights, 1)
self.b = 0.
def forward(self, x):
z = np.dot(x, self.w) + self.b
return z
def loss(self, z, y):
error = z - y
cost = error * error
cost = np.mean(cost)
return cost
使用定义的Network类,可以方便的计算预测值和损失函数。需要注意的是,类中的变量xxx, www,bbb, zzz, errorerrorerror等均是向量。以变量xxx为例,共有两个维度,一个代表特征数量(值为13),一个代表样本数量,代码如下所示。
net = Network(13)
#此处可以一次性计算多个样本的预测值和损失函数
x1 = x[0:3]
y1 = y[0:3]
z = net.forward(x1)
print('predict: ', z)
loss = net.loss(z, y1)
print(‘loss:’, loss)
训练过程

训练过程是深度学习模型的关键要素之一,其目标是让定义的损失函数LossLossLoss尽可能的小,也就是说找到一个参数解w和b,使得损失函数取得极小值。
计算梯度
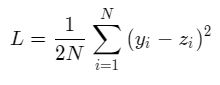
梯度的定义:

代码
x1 = x[0]
y1 = y[0]
z1 = net.forward(x1)
print(‘x1 {}, shape {}’.format(x1, x1.shape))
print(‘y1 {}, shape {}’.format(y1, y1.shape))
print(‘z1 {}, shape {}’.format(z1, z1.shape))
gradient_w0 = (z1 - y1) * x1[0]
print(‘gradient_w0 {}’.format(gradient_w0))
gradient_w1 = (z1 - y1) * x11
print(‘gradient_w1 {}’.format(gradient_w1))
gradient_w1 [-0.45417275]
#依次计算w2 的梯度。
gradient_w2= (z1 - y1) * x12
print(‘gradient_w1 {}’.format(gradient_w2))
使用Numpy进行梯度计算
基于Numpy广播机制(对向量和矩阵计算如同对1个单一变量计算一样),可以更快速的实现梯度计算。计算梯度的代码中直接用(z1-y1)*x1得到的是一个13维的向量,每个分量分别代表该维度的梯度。
代码实现:
gradient_w = (z1 - y1) * x1
print(‘gradient_w_by_sample1 {}, gradient.shape {}’.format(gradient_w, gradient_w.shape))
x2 = x1
y2 = y1
z2 = net.forward(x2)
gradient_w = (z2 - y2) * x2
print(‘gradient_w_by_sample2 {}, gradient.shape {}’.format(gradient_w, gradient_w.shape))
x3 = x2
y3 = y2
z3 = net.forward(x3)
gradient_w = (z3 - y3) * x3
print(‘gradient_w_by_sample3 {}, gradient.shape {}’.format(gradient_w, gradient_w.shape))
#注意这里是一次取出3个样本的数据,不是取出第3个样本
x3samples = x[0:3]
y3samples = y[0:3]
z3samples = net.forward(x3samples)
print(‘x {}, shape {}’.format(x3samples, x3samples.shape))
print(‘y {}, shape {}’.format(y3samples, y3samples.shape))
print(‘z {}, shape {}’.format(z3samples, z3samples.shape))
上面的x3samples, y3samples, z3samples的第一维大小均为3,表示有3个样本。下面计算这3个样本对梯度的贡献。
gradient_w = (z3samples - y3samples) * x3samples
print(‘gradient_w {}, gradient.shape {}’.format(gradient_w, gradient_w.shape))
z = net.forward(x)
gradient_w = (z - y) * x
print(‘gradient_w shape {}’.format(gradient_w.shape))
print(gradient_w)
我们对Markdown编辑器进行了一些功能拓展与语法支持,除了标准的Markdown编辑器功能,我们增加了如下几点新功能,帮助你用它写博客:
- 全新的界面设计 ,将会带来全新的写作体验;
- 在创作中心设置你喜爱的代码高亮样式,Markdown 将代码片显示选择的高亮样式 进行展示;
- 增加了 图片拖拽 功能,你可以将本地的图片直接拖拽到编辑区域直接展示;
- 全新的 KaTeX数学公式 语法;
- 增加了支持甘特图的mermaid语法1 功能;
- 增加了 多屏幕编辑 Markdown文章功能;
- 增加了 焦点写作模式、预览模式、简洁写作模式、左右区域同步滚轮设置 等功能,功能按钮位于编辑区域与预览区域中间;
- 增加了 检查列表 功能。
功能快捷键
撤销:Ctrl/Command + Z
重做:Ctrl/Command + Y
加粗:Ctrl/Command + B
斜体:Ctrl/Command + I
标题:Ctrl/Command + Shift + H
无序列表:Ctrl/Command + Shift + U
有序列表:Ctrl/Command + Shift + O
检查列表:Ctrl/Command + Shift + C
插入代码:Ctrl/Command + Shift + K
插入链接:Ctrl/Command + Shift + L
插入图片:Ctrl/Command + Shift + G
查找:Ctrl/Command + F
替换:Ctrl/Command + G
合理的创建标题,有助于目录的生成
直接输入1次#,并按下space后,将生成1级标题。
输入2次#,并按下space后,将生成2级标题。
以此类推,我们支持6级标题。有助于使用TOC语法后生成一个完美的目录。
如何改变文本的样式
## 通俗易懂的解释什么是机器学习
** 强调文本
大家好
加粗文本 加粗文本
标记文本
删除文本
引用文本
H2O is是液体。
210 运算结果是 1024.
插入链接与图片
链接: link.
标题
图片: 
带尺寸的图片:
居中的图片: 
居中并且带尺寸的图片:
当然,我们为了让用户更加便捷,我们增加了图片拖拽功能。
如何插入一段漂亮的代码片
去博客设置页面,选择一款你喜欢的代码片高亮样式,下面展示同样高亮的 代码片.
// An highlighted block
var foo = 'bar';
生成一个适合你的列表
- 项目
- 项目
- 项目
- 项目
- 项目1
- 项目2
- 项目3
- 计划任务
- 完成任务
创建一个表格
一个简单的表格是这么创建的:
| 项目 | Value |
|---|---|
| 电脑 | $1600 |
| 手机 | $12 |
| 导管 | $1 |
设定内容居中、居左、居右
使用:---------:居中
使用:----------居左
使用----------:居右
| 第一列 | 第二列 | 第三列 |
|---|---|---|
| 第一列文本居中 | 第二列文本居右 | 第三列文本居左 |
SmartyPants
SmartyPants将ASCII标点字符转换为“智能”印刷标点HTML实体。例如:
| TYPE | ASCII | HTML |
|---|---|---|
| Single backticks | 'Isn't this fun?' |
‘Isn’t this fun?’ |
| Quotes | "Isn't this fun?" |
“Isn’t this fun?” |
| Dashes | -- is en-dash, --- is em-dash |
– is en-dash, — is em-dash |
创建一个自定义列表
-
Markdown
- Text-to- HTML conversion tool Authors
- John
- Luke
如何创建一个注脚
一个具有注脚的文本。2
注释也是必不可少的
Markdown将文本转换为 HTML。
KaTeX数学公式
您可以使用渲染LaTeX数学表达式 KaTeX:
Gamma公式展示 Γ ( n ) = ( n − 1 ) ! ∀ n ∈ N \Gamma(n) = (n-1)!\quad\forall n\in\mathbb N Γ(n)=(n−1)!∀n∈N 是通过欧拉积分
Γ ( z ) = ∫ 0 ∞ t z − 1 e − t d t . \Gamma(z) = \int_0^\infty t^{z-1}e^{-t}dt\,. Γ(z)=∫0∞tz−1e−tdt.
你可以找到更多关于的信息 LaTeX 数学表达式here.
新的甘特图功能,丰富你的文章
- 关于 甘特图 语法,参考 这儿,
UML 图表
可以使用UML图表进行渲染。 Mermaid. 例如下面产生的一个序列图:
这将产生一个流程图。:
- 关于 Mermaid 语法,参考 这儿,
FLowchart流程图
我们依旧会支持flowchart的流程图:
- 关于 Flowchart流程图 语法,参考 这儿.
导出与导入
导出
如果你想尝试使用此编辑器, 你可以在此篇文章任意编辑。当你完成了一篇文章的写作, 在上方工具栏找到 文章导出 ,生成一个.md文件或者.html文件进行本地保存。
导入
如果你想加载一篇你写过的.md文件,在上方工具栏可以选择导入功能进行对应扩展名的文件导入,
继续你的创作。
mermaid语法说明 ↩︎
注脚的解释 ↩︎