卷积神经网络
卷积神经网络
一、全连接网络回顾
全连接神经网络:每个神经元与前后相邻层的每一个神经元都
有连接关系,输入是特征,输出为预测的结果。
参数个数 = ∑ 各层 ( 前层 ∗ 后层 + 后层 ) 参数个数=\sum _{各层}(前层*后层+后层) 参数个数=各层∑(前层∗后层+后层)

在实际应用中,图像的分辨率远高于此,且大多数是彩色图像,如下图所示。虽然全连接网络一般被认为是分类预测的最佳网络,但待优化的参数过多,容易导致模型过拟合。

为了解决参数量过大而导致模型过拟合的问题,一般不会将原始图像直接输入,而是先对图像进行特征提取,再将提取到的特征输入全连接网络。

二、卷积神经网络
2.1 卷积计算过程
卷积(Convolution):
- 卷积计算可以认为是一种有效提取图像特征的方法。
- 一般会用一个正方形的卷积核,按指定步长,在输入特征图上滑动,遍历输入特征图中的每个像素点。每一个步长,卷积核会与输入特征图出现重合区域,重合区域对应元素相乘、求和再加上偏置项得到输出特征的一个像素点。
如下图所示,利用大小为3×3×1的卷积核对5×5×1的单通道图像做卷积计算得到相应结果。

对于彩色图像(多通道)来说,卷积核通道数与输入特征一致,套接后在对应位置上进行乘加和操作,如下图所示,利用三通道卷积核对三通道的彩色特征图做卷积计算。

用多个卷积核可实现对同一层输入特征的多次特征提取,卷积核的个数决定输出层的通道(channels)数,即输出特征图的深度。
2.2 感受野
感受野(Receptive Field):卷积神经网络各输出层每个像素点在原始图像上的映射区域大小。
下图为感受野示意图
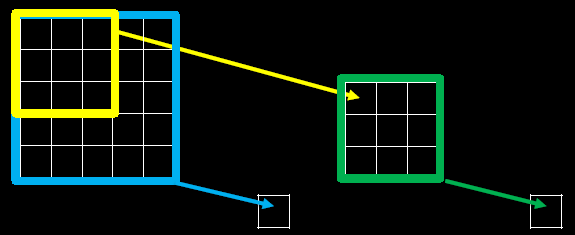
当我们采用尺寸不同的卷积核时,最大的区别就是感受野的大小不同,所以经常会采用多层小卷积核来替换一层大卷积核,在保持感受野相同的情况下减少参数量和计算量。
例如十分常见的用2层3 * 3卷积核来替换1层5 * 5卷积核的方法,如下图所示。

这里给出详细推导:不妨设输入特征图的宽、高均为x,卷积计算的步长为1,显然,两个 3 ∗ 3 3 * 3 3∗3卷积核的参数量为 9 + 9 = 18 9 + 9 = 18 9+9=18,小于 5 ∗ 5 5 * 5 5∗5卷积核的25,前者的参数量更少。
在计算量上,对于 5 ∗ 5 5 * 5 5∗5卷积核来说,输出特征图共有 ( x – 5 + 1 ) 2 (x – 5 + 1)^2 (x–5+1)2个像素点,每个像素点需要进行 5 ∗ 5 = 25 5 * 5 = 25 5∗5=25次乘加运算,则总计算量为 25 ∗ ( x – 5 + 1 ) 2 = 25 x 2 – 200 x + 400 25 * (x – 5 + 1)^2 = 25x^2 – 200x + 400 25∗(x–5+1)2=25x2–200x+400;
对于两个 3 ∗ 3 3 * 3 3∗3卷积核来说,第一个3 * 3卷积核输出特征图共有 ( x – 3 + 1 ) 2 (x – 3 + 1)^2 (x–3+1)2个像素点,每个像素点需要进行 3 ∗ 3 = 9 3 * 3 = 9 3∗3=9次乘加运算,第二个3 * 3卷积核输出特征图共有 ( x – 3 + 1 – 3 + 1 ) 2 (x – 3 + 1 – 3 + 1)^2 (x–3+1–3+1)2个像素点,每个像素点同样需要进行9次乘加运算,则总计算量为 9 ∗ ( x – 3 + 1 ) 2 + 9 ∗ ( x – 3 + 1 – 3 + 1 ) 2 = 18 x 2 – 108 x + 180 9 * (x – 3 + 1)^2 + 9 * (x – 3 + 1 – 3 + 1)^2 = 18 x^2 – 108x + 180 9∗(x–3+1)2+9∗(x–3+1–3+1)2=18x2–108x+180;
2.3 输出特征尺寸计算
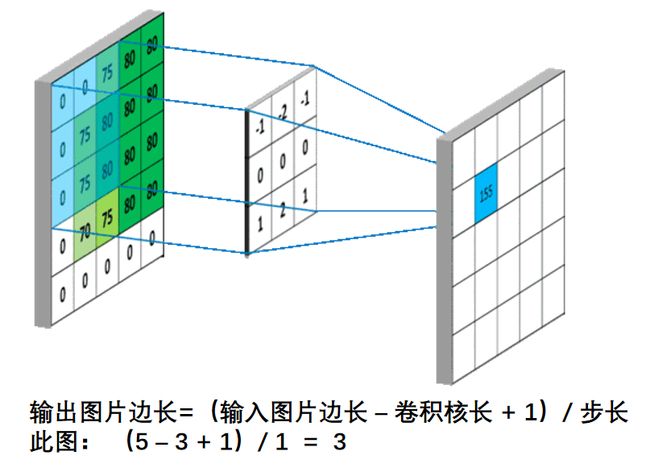
输出特征尺寸计算:在了解神经网络中卷积计算的整个过程后,就可以对输出特征图的尺寸进行计算。
如下图所示,5×5的图像经过3×3大小的卷积核做卷积计算后输出特征尺寸为3×3
2.4 全零填充
全零填充(padding):为了保持输出图像尺寸与输入图像一致,经常会在输入图像周围进行全零填充,如下所示,在5×5的输入图像周围填0,则输出特征尺寸同为5×5。

在Tensorflow框架中,用参数padding = ‘SAME’或padding = ‘VALID’表示是否进行全零填充,其对输出特征尺寸大小的影响如下:

Tensorflow描述卷积层:
tf.keras.layers.Conv2D (
filters= 卷积核个数,
kernel_size= 卷积核尺寸, #正方形写核长整数,或(核高h,核宽w)strides= 滑动步长, #横纵向相同写步长整数,或(纵向步长h,横向步长w),默认1
padding= “same” or “valid”, #使用全零填充是“same”,不使用是“valid”(默认)
activation= “ relu” or “ sigmoid ” or “ tanh ” or “ softmax”等, #如有BN此处不写
input_shape= (高, 宽, 通道数) #输入特征图维度,可省略
)
model = tf.keras.models.Sequential([Conv2D(6, 5, padding='valid', activation='sigmoid'),MaxPool2D(2, 2),
Conv2D(6, (5, 5), padding='valid', activation='sigmoid'),MaxPool2D(2, (2, 2)),
Conv2D(filters=6, kernel_size=(5, 5),padding='valid', activation='sigmoid'),MaxPool2D(pool_size=(2, 2), strides=2),
Flatten(),
Dense(10, activation='softmax')
])
2.5 批标准化
标准化:使数据符合0均值,1为标准差的分布。
批标准化(Batch Normalization):对一小批数据(batch),做标准化处理。
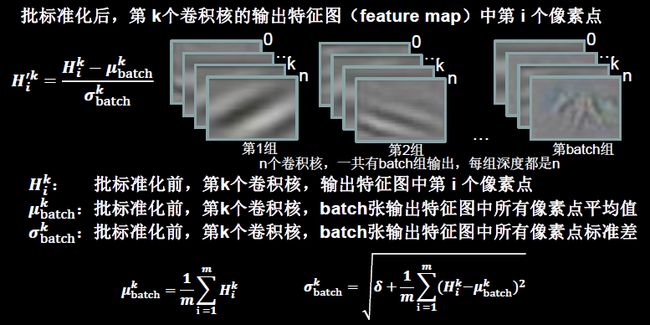
Batch Normalization将神经网络每层的输入都调整到均值为0,方差为1的标准正态分布,其目的是解决神经网络中梯度消失的问题

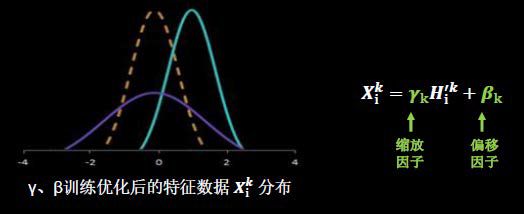
BN操作的另一个重要步骤是缩放和偏移,值得注意的是,缩放因子γ以及偏移因子β都是可训练参数
BN层位于卷积层之后,激活层之前。
Tensorflow 描述批标准化
tf.keras.layers.BatchNormalization()
model = tf.keras.models.Sequential([Conv2D(filters=6, kernel_size=(5, 5), padding='same'), # 卷积层
BatchNormalization(), # BN层
Activation('relu'), # 激活层
MaxPool2D(pool_size=(2, 2), strides=2, padding='same'), # 池化层
Dropout(0.2), # dropout层
])
2.6 池化
池化(Pooling)用于减少特征数据量。
最大值池化可提取图片纹理,均值池化可保留背景特征。
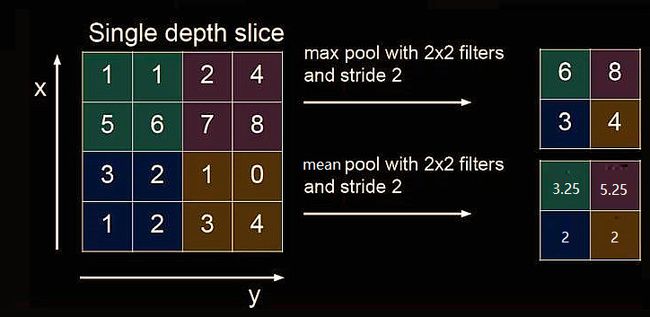
Tensorflow描述池化:
tf.keras.layers.MaxPool2D(
pool_size=池化核尺寸,#正方形写核长整数,或(核高h,核宽w)strides=池化步长,#步长整数,或(纵向步长h,横向步长w),默认为pool_sizepadding=‘valid’or‘same’#使用全零填充是“same”,不使用是“valid”(默认)
)
tf.keras.layers.AveragePooling2D(
pool_size=池化核尺寸,#正方形写核长整数,或(核高h,核宽w)strides=池化步长,#步长整数,或(纵向步长h,横向步长w),默认为pool_sizepadding=‘valid’or‘same’#使用全零填充是“same”,不使用是“valid”(默认)
)
model = tf.keras.models.Sequential([Conv2D(filters=6, kernel_size=(5, 5), padding='same'), # 卷积层
BatchNormalization(), # BN层
Activation('relu'), # 激活层
MaxPool2D(pool_size=(2, 2), strides=2, padding='same'), # 池化层
Dropout(0.2), # dropout层
])
2.7 舍弃
舍弃(Dropout):在神经网络训练时,将一部分神经元按照一定概率从神经网络中暂时舍弃。神经网络使用时,被舍弃的神经元恢复链接。
tf.keras.layers.Dropout(舍弃的概率)
model = tf.keras.models.Sequential([Conv2D(filters=6, kernel_size=(5, 5), padding='same'), # 卷积层
BatchNormalization(), # BN层
Activation('relu'), # 激活层
MaxPool2D(pool_size=(2, 2), strides=2, padding='same'), # 池化层
Dropout(0.2), # dropout层
])
2.8 卷积神经网络主要模块
卷积神经网络:借助卷积核提取特征后,送入全连接网络。
卷积神经网络主要模块:

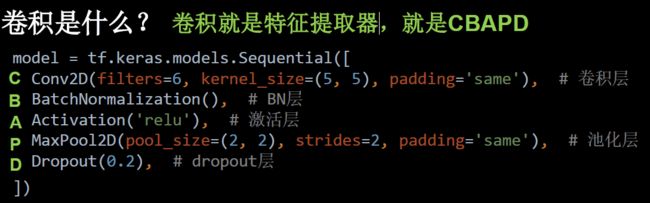
三、卷积神经网络搭建示例
import tensorflow as tf
import os
import numpy as np
from matplotlib import pyplot as plt
from tensorflow.keras.layers import Conv2D, BatchNormalization, Activation, MaxPool2D, Dropout, Flatten, Dense
from tensorflow.keras import Model
np.set_printoptions(threshold=np.inf)
cifar10 = tf.keras.datasets.cifar10
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
class Baseline(Model):
def __init__(self):
super(Baseline, self).__init__()
self.c1 = Conv2D(filters=6, kernel_size=(5, 5), padding='same') # 卷积层
self.b1 = BatchNormalization() # BN层
self.a1 = Activation('relu') # 激活层
self.p1 = MaxPool2D(pool_size=(2, 2), strides=2, padding='same') # 池化层
self.d1 = Dropout(0.2) # dropout层
self.flatten = Flatten()
self.f1 = Dense(128, activation='relu')
self.d2 = Dropout(0.2)
self.f2 = Dense(10, activation='softmax')
def call(self, x):
x = self.c1(x)
x = self.b1(x)
x = self.a1(x)
x = self.p1(x)
x = self.d1(x)
x = self.flatten(x)
x = self.f1(x)
x = self.d2(x)
y = self.f2(x)
return y
model = Baseline()
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=False),
metrics=['sparse_categorical_accuracy'])
checkpoint_save_path = "./checkpoint/Baseline.ckpt"
if os.path.exists(checkpoint_save_path + '.index'):
print('-------------load the model-----------------')
model.load_weights(checkpoint_save_path)
cp_callback = tf.keras.callbacks.ModelCheckpoint(filepath=checkpoint_save_path,
save_weights_only=True,
save_best_only=True)
history = model.fit(x_train, y_train, batch_size=32, epochs=5, validation_data=(x_test, y_test), validation_freq=1,
callbacks=[cp_callback])
model.summary()
file = open('./weights.txt', 'w')
for v in model.trainable_variables:
file.write(str(v.name) + '\n')
file.write(str(v.shape) + '\n')
file.write(str(v.numpy()) + '\n')
file.close()
acc = history.history['sparse_categorical_accuracy']
val_acc = history.history['val_sparse_categorical_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
plt.subplot(1, 2, 1)
plt.plot(acc, label='Training Accuracy')
plt.plot(val_acc, label='Validation Accuracy')
plt.title('Training and Validation Accuracy')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(loss, label='Training Loss')
plt.plot(val_loss, label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.show()
运行结果如下:
50000/50000 [==============================] - 7s 142us/sample - loss: 1.1004 - sparse_categorical_accuracy: 0.6083 - val_loss: 1.1223 - val_sparse_categorical_accuracy: 0.6027
Model: "baseline"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) multiple 456
_________________________________________________________________
batch_normalization (BatchNo multiple 24
_________________________________________________________________
activation (Activation) multiple 0
_________________________________________________________________
max_pooling2d (MaxPooling2D) multiple 0
_________________________________________________________________
dropout (Dropout) multiple 0
_________________________________________________________________
flatten (Flatten) multiple 0
_________________________________________________________________
dense (Dense) multiple 196736
_________________________________________________________________
dropout_1 (Dropout) multiple 0
_________________________________________________________________
dense_1 (Dense) multiple 1290
=================================================================
Total params: 198,506
Trainable params: 198,494
Non-trainable params: 12
