深度有趣 | 09 Inception-v3图片分类
简介
Inception-v3是由Google提出,用于实现ImageNet大规模视觉识别任务(ImageNet Large Visual Recognition Challenge)的一种神经网络
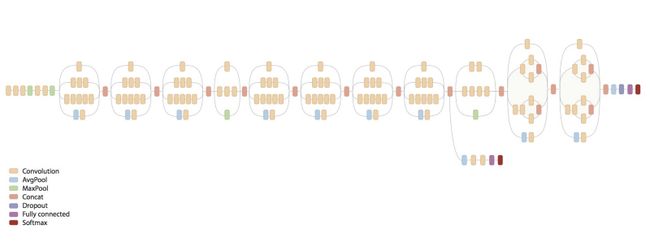
Inception-v3反复使用了Inception Block,涉及大量的卷积和池化,而ImageNet包括1400多万张图片,类别数超过1000
因此手动在ImageNet上训练Inception-v3,需要耗费大量的资源和时间
这里我们选择加载pre-trained的Inception-v3模型,来完成一些图片分类任务
准备
预训练好的模型共包括三个部分
classify_image_graph_def.pb:Inception-v3模型结构和参数imagenet_2012_challenge_label_map_proto.pbtxt:从类别编号到类别字符串的对应关系imagenet_synset_to_human_label_map.txt:从类别字符串到类别名的对应关系
例如,169对应n02510455,对应giant panda, panda, panda bear, coon bear, Ailuropoda melanoleuca
图片分类
加载库
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
整理两个映射文件,得到从类别编号到类别名的对应关系
uid_to_human = {}
for line in tf.gfile.GFile('imagenet_synset_to_human_label_map.txt').readlines():
items = line.strip().split('\t')
uid_to_human[items[0]] = items[1]
node_id_to_uid = {}
for line in tf.gfile.GFile('imagenet_2012_challenge_label_map_proto.pbtxt').readlines():
if line.startswith(' target_class:'):
target_class = int(line.split(': ')[1])
if line.startswith(' target_class_string:'):
target_class_string = line.split(': ')[1].strip('\n').strip('\"')
node_id_to_uid[target_class] = target_class_string
node_id_to_name = {}
for key, value in node_id_to_uid.items():
node_id_to_name[key] = uid_to_human[value]
加载模型
def create_graph():
with tf.gfile.FastGFile('classify_image_graph_def.pb', 'rb') as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
_ = tf.import_graph_def(graph_def, name='')
定义一个分类图片的函数
def classify_image(image, top_k=1):
image_data = tf.gfile.FastGFile(image, 'rb').read()
create_graph()
with tf.Session() as sess:
# 'softmax:0': A tensor containing the normalized prediction across 1000 labels
# 'pool_3:0': A tensor containing the next-to-last layer containing 2048 float description of the image
# 'DecodeJpeg/contents:0': A tensor containing a string providing JPEG encoding of the image
softmax_tensor = sess.graph.get_tensor_by_name('softmax:0')
predictions = sess.run(softmax_tensor, feed_dict={'DecodeJpeg/contents:0': image_data})
predictions = np.squeeze(predictions)
top_k = predictions.argsort()[-top_k:]
for node_id in top_k:
human_string = node_id_to_name[node_id]
score = predictions[node_id]
print('%s (score = %.5f)' % (human_string, score))
调用函数进行图片分类,指定参数top_k可以返回最可能的多种分类结果
classify_image('test1.png')
分类结果如下
test1:giant panda, panda, panda bear, coon bear, Ailuropoda melanoleuca (score = 0.89107)test2:Pekinese, Pekingese, Peke (score = 0.90348)test3:Samoyed, Samoyede (score = 0.92054)
定制分类任务
Inception-v3是针对ImageNet图片分类任务设计的,因此最后一层全连接层的神经元个数和分类标签个数相同
如果需要定制分类任务,只需要使用自己的标注数据,然后替换掉最后一层全连接层即可
最后一层全连接层的神经元个数等于定制分类任务的标签个数,模型只训练最后一层的参数,其他参数保持不变
保留了Inception-v3对于图像的理解和抽象能力,同时满足定制的分类任务,属于迁移学习的一种典型应用场景
TensorFlow官方提供了如何在Inception-v3上进行迁移学习的教程
https://www.tensorflow.org/tutorials/image_retraining
所使用的数据包括五种花的拍摄图片
- daisy:雏菊
- dandelion:蒲公英
- roses:玫瑰
- sunflowers:向日葵
- tulips:郁金香
去掉最后一层全连接层后,对于一张图片输入,模型输出的表示称作Bottleneck
事先计算好全部图片的Bottleneck并缓存下来,可以节省很多训练时间,因为后续只需计算和学习Bottleneck到输出标签之间的隐层即可
TensorFlow官方提供了重训练的代码
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/examples/image_retraining/retrain.py
在命令行中使用,一些可选的命令行参数包括
--image_dir:训练图片目录--output_graph:模型保存目录--output_labels:模型标签保存目录--summaries_dir:模型日志保存目录--how_many_training_steps:训练迭代次数,默认为4000--learning_rate:学习率,默认为0.01--testing_percentage:测试集比例,默认为10%--validation_percentage:校验集比例,默认为10%--eval_step_interval:模型评估频率,默认10次迭代评估一次--train_batch_size:训练批大小,默认为100--print_misclassified_test_images:是否输出所有错误分类的测试集图片,默认为False--model_dir:Inception-v3模型路径--bottleneck_dir:Bottleneck缓存目录--final_tensor_name:新增的最后一层全连接层的名称,默认为final_result--flip_left_right:是否随机将一半的图片水平翻转,默认为False--random_crop:随机裁剪的比例,默认为0即不裁剪--random_scale:随机放大的比例,默认为0即不放大--random_brightness:随机增亮的比例,默认为0即不增亮--architecture:迁移的模型,默认为inception_v3,准确率最高但训练时间较长,还可以选'mobilenet_,例如_ [_quantized]' mobilenet_1.0_224和mobilenet_0.25_128_quantized
跑一下代码
python retrain.py --image_dir flower_photos --output_graph output_graph.pb --output_labels output_labels.txt --summaries_dir summaries_dir --model_dir .. --bottleneck_dir bottleneck_dir
此处对于视频中内容的勘误
- 将
--output_graph之后的output_graph改为output_graph.pb - 将
--output_labels之后的output_labels改为output_labels.txt
在校验集、测试集上的分类准确率分别为91%、91.2%
在我的笔记本上一共花了55分钟,其中44分钟花在了Bottleneck缓存上,但如果不缓存的话,训练过程中每次迭代都必须重复计算一遍
summaries_dir目录下的训练日志可用于TensorBorad可视化
tensorboard --logdir summaries_dir
然后在浏览器中访问http://localhost:6006,即可看到可视化的效果,包括SCALARS、GRAPHS、DISTRIBUTIONS、HISTOGRAMS四个页面
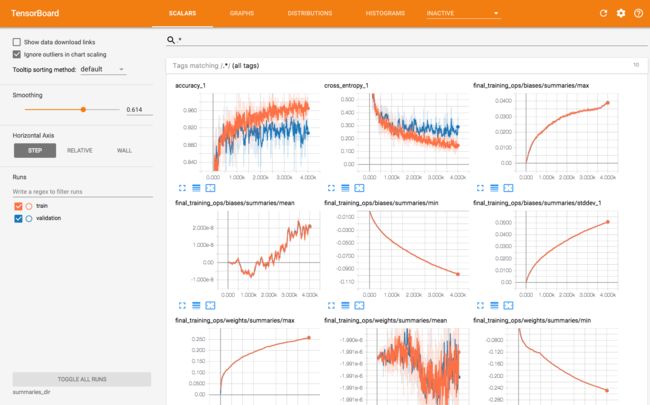
如果需要完成其他图片分类任务,整理相应的标注图片,并以标签名作为子文件夹名称即可
如果要使用训练好的模型,参照以下代码即可
output_labels.txt:分类类别文件路径output_graph.pb:训练好的模型路径read_image():读取图片的函数input_operation:图片输入对应的operationoutput_operation:分类输出对应的operationtest.jpg:待分类的图片路径
# -*- coding: utf-8 -*-
import tensorflow as tf
import numpy as np
labels = []
for line in tf.gfile.GFile('output_labels.txt').readlines():
labels.append(line.strip())
def create_graph():
graph = tf.Graph()
graph_def = tf.GraphDef()
with open('output_graph.pb', 'rb') as f:
graph_def.ParseFromString(f.read())
with graph.as_default():
tf.import_graph_def(graph_def)
return graph
def read_image(path, height=299, width=299, mean=128, std=128):
file_reader = tf.read_file(path, 'file_reader')
if path.endswith('.png'):
image_reader = tf.image.decode_png(file_reader, channels=3, name='png_reader')
elif path.endswith('.gif'):
image_reader = tf.squeeze(tf.image.decode_gif(file_reader, name='gif_reader'))
elif path.endswith('.bmp'):
image_reader = tf.image.decode_bmp(file_reader, name='bmp_reader')
else:
image_reader = tf.image.decode_jpeg(file_reader, channels=3, name='jpeg_reader')
image_np = tf.cast(image_reader, tf.float32)
image_np = tf.expand_dims(image_np, 0)
image_np = tf.image.resize_bilinear(image_np, [height, width])
image_np = tf.divide(tf.subtract(image_np, [mean]), [std])
sess = tf.Session()
image_data = sess.run(image_np)
return image_data
def classify_image(image, top_k=1):
image_data = read_image(image)
graph = create_graph()
with tf.Session(graph=graph) as sess:
input_operation = sess.graph.get_operation_by_name('import/Mul')
output_operation = sess.graph.get_operation_by_name('import/final_result')
predictions = sess.run(output_operation.outputs[0], feed_dict={input_operation.outputs[0]: image_data})
predictions = np.squeeze(predictions)
top_k = predictions.argsort()[-top_k:]
for i in top_k:
print('%s (score = %.5f)' % (labels[i], predictions[i]))
classify_image('test.jpg')
参考
- Deep Learning with Tensorflow Part 2 - Image classification:https://towardsdatascience.com/deep-learning-with-tensorflow-part-2-image-classification-58fcdffa7b84
- Going deeper with convolutions:https://arxiv.org/pdf/1409.4842.pdf
- ImageNet:http://image-net.org/
- Image Recognition:https://www.tensorflow.org/tutorials/image_recognition
- How to Retrain Inception’s Final Layer for New Categories:https://www.tensorflow.org/tutorials/image_retraining
- 卷积神经网络 - 吴恩达深度学习微专业 - 网易云课堂http://mooc.study.163.com/learn/2001281004?tid=2001392030#/learn/content?type=detail&id=2001729331
视频讲解课程
深度有趣(一)