卷积操作的不同类型
文章目录
- 1. 一维卷积
- 2. 二维卷积
- 3. 三维卷积
- 4. 扩张卷积
- 5. 空洞卷积
- 6. 分组卷积
一般而言,一维卷积用于文本数据;二维卷积用于图像数据,对宽度和高度都进行卷积;三维卷积用于视频及3D图像处理领域,对立方体的三个面进行卷积。
1. 一维卷积
对一个词向量做一维卷积
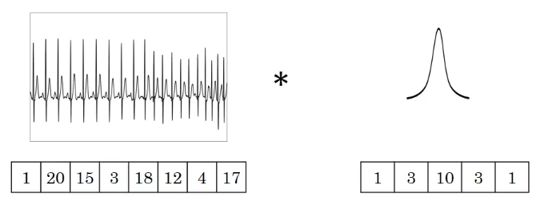
上图输入词向量的维度为 8,卷积核的维度为 5,输出长度为 8−5+1=4。PyTorc使用torch.nn.Conv1d(in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias=True)实现一维卷积操作。
import torch
import torch.nn as nn
a = torch.randn(1,16,8) # input:(样本数, 通道数, 词向量维度)
conv = nn.Conv1d(16, 1, 5) # Conv1d:(in_channels, out_channels, kernel_size)
c = conv(a)
print('a:', a.size()) # torch.Size([1, 16, 8])
print('c:', c.size()) # torch.Size([1, 1, 4])
2. 二维卷积
二维卷积是最常见、用途最广泛的卷积。下图展示了二维卷积操作示意图
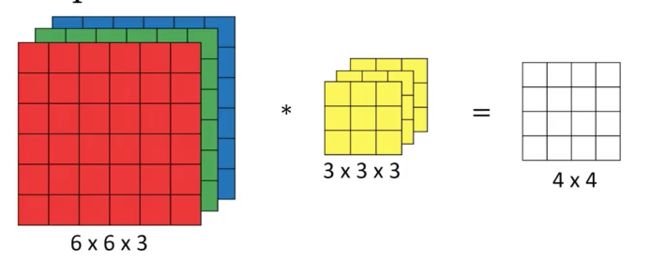
图中输入为 RGB 三通道的图片,图片大小为6*6。卷积核大小为3*3,卷积核数量为1。输出特征图大小为4*4,输出特征图数量为1。PyTorc使用torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias=True)。
import torch
import torch.nn as nn
a = torch.Tensor([[[[1,2,3,4],
[5,6,7,8],
[9,10,11,12],
[13,14,15,16]]],
[[[1,2,3,4],
[5,6,7,8],
[9,10,11,12],
[13,14,15,16]]]])
print('a:',a.size()) # torch.Size([2, 1, 4, 4])
conv = nn.Conv2d(1,6,2) # Conv2d:(in_channels, out_channels, kernel_size)
c = conv(a)
print('c:',c.size()) # torch.Size([2, 6, 3, 3])
3. 三维卷积
三维卷积示意图如下,一个3*3*3的卷积核在立方体上进行卷积,得到输出。

在二维卷积中,作用在不同通道上的卷积核参数是不同的。而在三维卷积中,则共用一个 3D 的卷积核,3D 卷积核的参数在整个图像上权重共享。三维卷积核比二维卷积核多了一个depth维度。这个深度可能是视频上的连续帧,也可能是立体图像中的不同切片。PyTorc使用torch.nn.Conv3d(in_channels, out_channels, kernel_size, stride, padding, dilation, groups, bias=True)。
import torch
import torch.nn as nn
input = torch.randn(32, 3, 10, 224, 224) # input:(N, C, D, H, W)
# 每一维度相同参数配置
conv1 = nn.Conv3d(3, 64, kernel_size=3, stride=2, padding=1)
output = conv1(net_input)
print(output.shape) # shape:[32, 64, 5, 112, 112]
# 每一维度不同参数配置
conv2 = nn.Conv3d(3, 64, (2, 3, 3), stride=(1, 2, 2), padding=(0, 1, 1))
net_output = conv2(net_input)
print(net_output.shape) # shape:[32, 64, 9, 112, 112]
4. 扩张卷积
5. 空洞卷积
6. 分组卷积
【参考】
- 神经网络之多维卷积的那些事 (一维、二维、三维);
- 3D 卷积神经网络详解;
- [pytorch][基础模块] torch.nn.Conv3D 使用样例与说明;
- 官方文档:TORCH.NN;