基于正交投影的实时三维人体姿态估计
王亦洲课题组 ECCV 2022 入选论文解读:基于正交投影的实时三维人体姿态估计
本文是对发表于计算机视觉领域顶级会议 ECCV 2022的论文 Faster VoxelPose: Real-time 3D Human Pose Estimation by Orthographic Projection 的解读。该论文由北京大学王亦洲课题组与微软亚洲研究院主管研究员王春雨合作完成,研究了多人多相机三维姿态估计问题。通过将 3D 体素空间的复杂计算分解为 2D 和 1D 特征空间的计算,该方法对此前方法实现了约10倍的提速,达到实时应用的要求。
论文链接:https://arxiv.org/abs/2207.10955
代码链接:https://github.com/AlvinYH/Faster-VoxelPose
01 背景介绍
多相机视角下的三维人体姿态估计是计算机视觉领域的一个重要任务。相比二维的简单情形,我们还需有效整合不同视角下的信息,从而准确重建三维坐标。而多人的拥挤场景还会带来歧义、遮挡等问题。为应对该挑战,VoxelPose 通过重投影热力图获得体素特征表示,并直接使用 3D CNN 回归坐标,避免了显式的跨视角匹配。然而 3D 卷积网络计算开销巨大,当算法部署到实际大场景中,无法满足如体育教学等应用对实时性的要求。为了提升算法效率,本工作提出了以正交投影(orthogonal projection)为基础的 Faster VoxelPose,消除了耗时的 3D 卷积,使得在姿态估计误差小幅增加的情形下,运行速率提升为原先的十倍左右。
 02 方法概览
02 方法概览
建立相机视角两两间的点对应是处理三维视觉任务的常见思路,可以在此基础上利用三角几何(triangulation)等方法估计三维人体姿态。然而,这类方法对于每个视角的估计误差较为敏感。相比之下,将产生的热力图重投影到三维空间的做法具有更强的鲁棒性。我们希望保留这个优点,因此沿用了 VoxelPose 的体素特征表示。
下面我们通过一个简单的单人情形来阐释正交投影的想法。如图2(A) 所示,假设肩关节点 P=(X, Y, Z) 是我们的估计目标。通常来说,由重投影构造的体素特征在该点周围应具有显著的分布模式,能够被 3D 卷积网络所识别。则不难推知,若我们将体素表示投影至三个互相正交的平面(即 xy , xz 和 yz 平面),将得到的二维特征图进行 2D 卷积,对应位置点也应具有较大响应值。将三个平面的估计结果相融合,便可组合出最终的三维坐标。
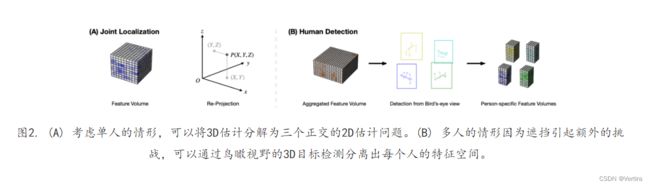
以上正交投影的方式非常朴素直接。但在拥挤的场景下,往三个平面作投影容易导致不同个体特征的重叠、混淆,从而严重影响估计的精度。受到自顶向下的方法启发,我们可以先框定所有个体的紧的三维检测框,从而过滤掉无关特征。为了快速在三维空间中框定范围,我们利用了一个先验知识:绝大多数情形下,两个人的中心点不会处于同一竖直线上,故无需担心沿 z 轴方向的特征相互干扰。因此我们在特征空间的鸟瞰图(BEV)中定位其水平方向的投影,并固定 bounding box 的竖直高度为2m,如图2(B) 所示。基于以上两个想法,我们分别设计了关节回归网络(Joint Localization Networks, JLN)和人体检测网络(Human Detection Networks, HDN)。
在第一阶段(HDN),我们的网络借鉴了 CenterNet 的设计,在对所有人的中心进行初步估计的同时,还输出偏移量和检测框的长和宽,如图3所示。

在第二阶段(JLN),我们依据每个人的 3D 检测框构造其体素特征表示,然后利用一个权重网络加权融合三个平面的结果,最终得到每个关节点的坐标估计,如图4所示。

03 实验结论
我们在 CMU panoptic, Shelf 和 Campus 三个数据集上进行实验。可视化结果如图5所示。这是来自 CMU Panoptic 的测试数据,共有5个相机视角。可以看到,在相机2、4和5均有一个人被遮挡,但最终的中心点识别、bounding box 检测和姿态估计都较为准确。

我们的实验证明了所提出的方法的优越性,定量结果如下表所示。为了比较的公平性,我们将测试时的 batch size 大小统一设置为1,在相同的 GPU 环境下测定 CMU Panoptic 的平均运行时间。和原版 VoxelPose 相比,我们提出的方法的平均关节误差由17.68mm 上升到18.26mm,0.6mm 的误差在实际应用中通常是可接受的。同时,处理帧率 FPS 提高到约10倍。除此之外,PlaneSweep 需要进行跨视角匹配,时间复杂度和相机数量平方线性相关,而我们的方法只需要进行统一的重投影。当相机数量更多、场景更大时,我们所提出方法的优势会更加明显。

04 总 结
综上所述,在这篇论文中,我们优化了 VoxelPose 的网络结构,将笨重的 3D 卷积替换为 2D 或 1D 卷积,使模型在保持较好性能的前提下实现了明显的加速。实验结果证明了我们方法的有效性,并且能扩展到多相机、大场景的设定。
参考文献
[1] Tu, H., Wang, C., Zeng, W.: Voxelpose: Towards multi-camera 3d human pose estimation in wild environment. In: ECCV (2020).
[2] Lin, J., Lee, G.H.: Multi-view multi-person 3d pose estimation with plane sweep stereo. In: CVPR (2021).
[3] Wang, T., Zhang, J., Cai, Y., Yan, S., Feng, J.: Direct multi-view multi-person 3d human pose estimation. Advances in Neural Information Processing Systems (2021).
[4] Joo, H., Liu, H., Tan, L., Gui, L., Nabbe, B., Matthews, I., Kanade, T., Nobuhara, S., Sheikh, Y.: Panoptic studio: A massively multiview system for social motion capture. In: ICCV (2015).
参考:
王亦洲课题组 ECCV 2022 入选论文解读:基于正交投影的实时三维人体姿态估计-新闻动态-北京大学前沿计算研究中心 (pku.edu.cn)