动漫风格化—AnimeGANv2
animegan2_face2paint_v2
bryandlee/naver-webtoon-faces
AnimeGANv2
项目
[Project]AnimeGANv2
摘要
在计算机视觉和艺术风格转移方面,将现实世界场景的照片转换为动漫风格的图像是一项有意义且具有挑战性的任务。我们之前提出的AnimeGAN结合了神经风格迁移合生成对抗网络(GAN)来完成这项任务。但是,AnimeGAN仍然存在一些明显的问题,例如模型生成的图像中存在高频伪影。因此,在本研究汇总,我们提出了AnimeGAN的改进版本,即AnimeGANv2。它通过简单的改变网络中特征的归一化来防止高频伪影的产生。此外,我们进一步缩小了生成器网络的规模,以实现更高效的动画风格转换。在新建立的高质量数据集上训练的AnimeGANv2可以生成视觉质量比AnimeGAN更好的动画图像。
方法
AnimeGANv2使用特征成归一化来防止网络在生成的图像汇总产生高频伪影。但是,Anime GAN由于使用了实例归一化,很容易产生高频伪影,这与styleGAN产生高频伪影的原因是一样的。事实上,总变化损失并不能完全抑制高频噪声的产生。实例归一化通常被认为是风格迁移中最好的归一化方法。它可以使特征图中的不同通道具有不同的特征属性,从而促进模型生成的图像中风格的多样性。层归一化可以使特征图中的不同通道具有相同的特征属性分布,可以有效防止局部噪声的产生。
AnimeGANv2中生成器的网络结构如图2所示。K表示卷积核的大小,S表示步长,C表示卷积核的个数,IRB表示反向残差块,resize表示插值上采样方法,SUM表示逐元素相加。AnimeGANv2的生成器参数大小为8.6MB,AnimeGAN的生成器参数大小为15.8MB。AnimeGANv2使用与AnimeGAN相同的判别器,不同之处在于判别器使用层归一化而不是实例归一化。
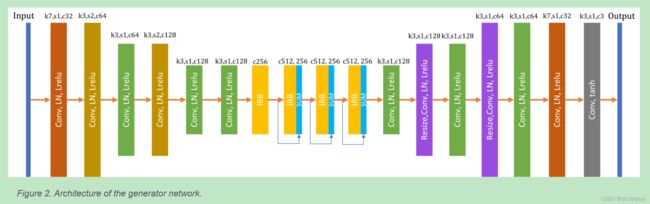
AnimeGANv2使用的三个动画风格数据集如表1所示。训练中使用的图像尺寸为256*256,这些风格图像均来自对应的高清风格电影中的视频帧。图3显示了AnimeGANv2在三种风格的测试数据集上的定性结果。

Download Style Dataset Link
源码(TensorFlow版本)
TachibanaYoshino/AnimeGANv2
AnimeGANv2的改进
AnimeGANv2的改进方向主要包括以下4点:
- 解决生成图像中高频伪影的问题。
- 训练简单,直接实现论文中的效果。
- 进一步减少生成器网络的参数数量。 (生成器大小:8.17 Mb),精简版具有较小的生成器模型。
- 使用新的高质量风格数据,尽可能来自BD电影。

要求

使用
- inference
python test.py --checkpoint_dir checkpoint/generator_Hayao_weight --test_dir dataset/test/HR_photo --save_dir Hayao/HR_photo
- train

结果
- Photo to Paprika Style
源码(PyTorch版本)
bryandlee/animegan2-pytorch
AnimeGANv2 的 PyTorch 实现。
基本用法
python test.py --input_dir /opt/xxx/data/image --checkpoint_dir ./weights/face_paint_512_v2.pt --device cpu
Torch Hub用法

TORCH.HUB
Pytorch Hub 是一个预训练模型存储库,旨在促进研究的可重复性。
- 发布模型
Pytorch Hub 支持通过添加一个简单的 hubconf.py 文件将预训练模型(模型定义和预训练权重)发布到 github 存储库;
hubconf.py 可以有多个入口点。 每个入口点都定义为一个 python 函数(例如:您要发布的预训练模型)。
如果我们在 pytorch/vision/hubconf.py 中扩展实现,这里有一个代码片段指定 resnet18 模型的入口点。 在大多数情况下,在 hubconf.py 中导入正确的函数就足够了。 这里我们只是想以扩展版本为例来说明它是如何工作的。 你可以在 pytorch/vision repo 中看到完整的脚本。
- 依赖项变量是加载模型所需的包名称列表。 请注意,这可能与训练模型所需的依赖项略有不同。
- args 和 kwargs 被传递给真正的可调用函数。
- 该函数的文档字符串用作帮助消息。 它解释了模型做什么以及允许的位置/关键字参数是什么。 强烈建议在此处添加一些示例。
- 入口点函数可以返回模型(nn.module)或辅助工具以使用户工作流程更顺畅,例如 标记器。
- 以下划线为前缀的可调用对象被视为辅助函数,不会出现在 torch.hub.list() 中。预训练的权重可以本地存储在 github 存储库中,也可以通过 torch.hub.load_state_dict_from_url() 加载。 如果小于 2GB,建议将其附加到项目版本并使用版本中的 url。 在上面的示例中,torchvision.models.resnet.resnet18 处理预训练,或者您可以将以下逻辑放入入口点定义中。
注意:发布的模型应该至少在一个分支/标签中。 它不能是随机提交。
2.从 Hub 加载模型
Pytorch Hub 提供了方便的 API,可以通过 torch.hub.list() 探索 hub 中的所有可用模型,通过 torch.hub.help() 显示文档字符串和示例,并使用 torch.hub.load() 加载预训练模型。
请注意,torch.hub.load() 中的 *args 和 **kwargs 用于实例化模型。 加载模型后,如何找出可以对模型执行的操作? 建议的工作流程是- dir(model) 以查看模型的所有可用方法。
- help(model.foo) 检查 model.foo 需要哪些参数来运行
为了帮助用户在不来回参考文档的情况下进行探索,我们强烈建议 repo 所有者使函数帮助消息清晰简洁。 包含一个最小的工作示例也很有帮助。
默认情况下,我们不会在加载后清理文件。 如果 get_dir() 返回的目录中已经存在缓存,则 Hub 默认使用缓存。
用户可以通过调用 hub.load(…, force_reload=True) 来强制重新加载。 这将删除现有的 github 文件夹和下载的权重,重新初始化一个新的下载。 当更新发布到同一个分支时,这很有用,用户可以跟上最新版本。
Torch hub 通过导入包来工作,就像它已安装一样。 在 Python 中导入会引入一些副作用。 例如,您可以在 Python 缓存 sys.modules 和 sys.path_importer_cache 中看到新项目,这是 Python 的正常行为。
这里值得一提的一个已知限制是用户不能在同一个 python 进程中加载同一个 repo 的两个不同分支。 就像在 Python 中安装两个同名的包一样,不好。 如果您真的尝试,Cache 可能会加入聚会并给您带来惊喜。 当然,将它们加载到单独的进程中是完全可以的。










权重转换(TensorFlow->PyTorch)
- 安装原始仓库的依赖项:python 3.6, tensorflow 1.15.0-gpu
- 安装 torch >= 1.7.1
- 克隆原始仓库并运行
git clone https://github.com/TachibanaYoshino/AnimeGANv2
python convert_weights.py
- 示例
转换后的Paprika样式模型的结果(从左到右为:输入图像,原始 tensorflow 结果,pytorch 结果)。注意:由于双线性上采样问题,转换权重的结果略有不同。
附加模型权重
-
Webtoon Face
在 256x256 人脸图像上训练。 从带有 L2 + VGG + GAN 损失和 CelebA-HQ 图像的 webtoon 人脸模型中提取。
-
Face Portrait v1
在 512x512 人脸图像上训练。

-
Face Portrait v2
在 512x512 人脸图像上训练。 相比v1,美化了健壮性。
AnimeGAN
论文
TachibanaYoshino/AnimeGAN/doc/Chen2020_Chapter_AnimeGAN.pdf
AnimeGAN:一种用于照片动画的新型轻量级 GAN
摘要
在本文中,提出了一种将现实世界场景的照片转换为动漫风格图像的新方法,这是计算机视觉和艺术风格迁移中一项艰巨而富有挑战性的任务。我们提出的方法结合了神经风格迁移和生成对抗网络 (GAN) 来完成这项任务。 对于这个任务,一些现有的方法并没有取得令人满意的动画效果。现有方法通常存在一些问题,其中比较显着的问题主要包括:1)生成的图像没有明显的动画风格纹理; 2)生成的图像丢失了原始图像的内容; 3)网络的参数需要大的存储容量。 在本文中,我们提出了一种新颖的轻量级生成对抗网络,称为 AnimeGAN,以实现快速动画风格迁移。 此外,我们进一步提出了三种新颖的损失函数,使生成的图像具有更好的动画视觉效果。 这些损失函数是灰度样式损失、灰度对抗损失和颜色重建损失。 提出的 AnimeGAN 可以很容易地使用未配对的训练数据进行端到端训练。 AnimeGAN 的参数需要较低的内存容量。 实验结果表明,我们的方法可以将真实世界的照片快速转换为高质量的动漫图像,并且优于最先进的方法。
介绍
动漫是我们日常生活中常见的一种艺术形式。 这种艺术形式广泛应用于广告、电影和儿童教育等多个领域。 目前,动画制作主要依靠人工实现。然而,手工制作动漫非常费力,并且需要大量的艺术技巧。 对于动画艺术家来说,创作高质量的动漫作品需要仔细考虑线条、纹理、颜色和阴影,这意味着创作作品既困难又耗时。 因此,能够将现实世界的照片自动转换为高质量动画风格图像的自动化技术是非常有价值和必要的。 不仅让美术师可以专注于更多的创意工作,节省时间,也让普通人更容易实现自己的动画。
目前,基于深度学习的图像到图像翻译[25]取得了很好的成果。 最近,基于学习的风格迁移方法 [5-8] 已成为常见的图像到图像转换方法。 这些方法可以学习参考图像(风格图像)的风格,并将学习到的风格应用于输入图像(内容图像),以生成融合内容图像的内容和风格图像的风格的新图像。 这些方法主要使用深度特征之间的相关性和基于优化的方法来编码图像的视觉风格。
生成对抗网络(GAN)[9,28] 已应用于风格迁移并取得了很好的效果。 许多研究人员提出了许多基于 GAN 的风格迁移方法 [3,30]。 这些方法虽然在动漫风格迁移上取得了一定的成功,但仍然存在很多明显的问题。 这些重要问题主要包括:1)生成的图像没有明显的动画风格纹理; 2)生成的图片丢失了原始照片的内容; 3)网络的大量参数需要更多的内存容量。
为了解决上述问题,我们提出了一种新颖的轻量级GAN,称为AnimeGAN,它可以将现实世界的照片快速转换为高质量的动漫图像。 所提出的 AnimeGAN 是一种轻量级的生成对抗模型,具有较少的网络参数,并引入了 Gram 矩阵 [16] 以获得更生动的风格图像。 我们的方法需要一组照片和一组动漫图像进行训练。 为了在使训练数据易于获取的同时产生高质量的结果,我们使用未配对的数据进行训练,这意味着训练集中的照片和动漫图像在内容上是不相关的。
为了进一步改善生成图像的动画视觉效果,我们提出了三个新的简单而有效的损失函数。 提出的损失函数是灰度样式损失、颜色重建损失和灰度对抗损失。 在生成网络中,灰度样式损失和颜色重建损失使生成的图像具有更明显的动漫风格,并保留了照片的颜色。 判别器网络中的灰度对抗性损失使生成的图像具有鲜艳的色彩。 在鉴别器网络中,我们还使用了文献 [3] 提出的边缘促进对抗性损失来保持清晰的边缘。
此外,为了使生成的图像具有原始照片的内容,我们引入了预训练的 VGG19 [26] 作为感知网络,以获得生成图像的深层感知特征和原始图像的 L1 损失。 在 AnimeGAN 开始训练之前,我们对生成器进行了初始化训练,以使 AnimeGAN 的训练更容易、更稳定。 大量实验结果表明,我们的 AnimeGAN 可以快速生成更高质量的动漫风格图像,并且优于最先进的方法。
相关工作
神经风格迁移。 已经开发了多种神经风格转移 (NST) 算法 [5-8,13],通过基于匹配 Gram 将一张图像的内容与另一张图像(通常是绘画)的风格相结合来合成新的图像 从预训练的卷积网络中提取的深度特征的矩阵统计。 盖蒂斯等人[5-8]在一系列风格迁移任务中取得了许多令人印象深刻的结果,但他们的网络模型往往有大量的参数,这使得训练过程相当耗时。 此外,他们的方法侧重于绘画的风格转移。 对于其他风格迁移任务,如动画风格迁移、摄影风格迁移等,仍需改进。 黄等人[11] 提出了一种简单但有效的方法,称为 AdaIN,它将内容图像特征的均值和方差与风格图像特征的均值和方差对齐。 该方法不使用复杂的 Gram 矩阵。 李等人[17] 提出了一种称为通用样式转移 (UST) 的新方法,该方法使用白化和着色变换 (WCT) 将内容图像中的特征协方差与给定风格图像中的特征协方差直接匹配。 为了实现逼真的图像风格化,Li 等人[18] 提出了一种新颖的快速摄影风格转移方法,该方法由风格化步骤和逼真的平滑步骤组成。 风格化步骤将参考照片的风格转移到内容照片,平滑步骤确保空间上一致的风格化。 每个步骤都有一个封闭形式的解决方案,并且可以有效地计算。 但是他们的方法需要额外的语义标签图作为监督,以帮助相应语义区域之间的风格转移。 总之,这些现有的神经风格迁移方法通常只适用于特定的风格迁移任务。 当它们用于动画风格迁移时,往往会得到不理想的结果。
使用 GAN 进行图像到图像的翻译。 图像到图像(I2I)翻译是计算机视觉领域的研究热点,是指将图像从源域映射到目标域的任务,例如 语义映射到真实图像,灰度图像到彩色图像,低分辨率图像到高分辨率图像等等。 生成对抗网络(GANs)已成为人工智能的研究热点,其灵感来自两人零和博弈。 GAN 通常包含同时学习的生成器和鉴别器,这两个网络使用最小最大游戏进行优化。 最近,基于 GAN 的图像到图像的翻译方法取得了许多成果。 伊索拉等人[12] 提出了 pix2pix 使用条件 GAN(cGAN)和 U-Net 神经网络来实现一般的图像到图像传输。 他们证明了这种方法在从标签图合成照片、从边缘图重建对象以及为图像着色等任务方面是有效的。 王等人[29] 在 pix2pix 方法的基础上提出了 pix2pixHD 方法,用于使用条件生成对抗网络从语义标签图合成高分辨率照片级逼真图像。 CycleGAN [30] 是一种在没有配对示例的情况下学习将图像从源域 X 转换到目标域 Y 的方法。 阿尔马海里等人[2] 提出了 Augmented CycleGAN,它以无监督的方式学习域之间的多对多映射。 他们的模型可以学习为每个输入产生一组不同输出的映射,并且可以学习跨实质不同领域的映射。
可以看出,基于 GAN 或卷积神经网络(CNN)[15] 的风格迁移方法已经得到了广泛的研究,并取得了许多优秀的成果。 近年来,动画风格迁移成为一个新的研究方向。 陈等人在文献 [3] 中提出了基于生成对抗网络的风格迁移方法,该方法似乎在照片卡通化问题方面效果很好。 Maciej 等人在文献[23]中提出了一种将视频转换为漫画的解决方案。 他们构建了两个阶段来将输入视频转换为漫画。 他们的主要贡献是提出了一种关键帧提取算法,该算法从视频中选择帧的子集以提供最全面的视频上下文。 他们的网络结构与文献[3]相同,并且在他们的方法中使用了一些其他的训练策略。
作为比较,我们提出了一种更轻量级的 AnimeGAN,以使用未配对的训练数据来学习照片和动漫流形之间的映射。 我们还提出了三个专用的损失函数来合成高质量的动漫图像。
我们的方法
AnimeGAN 架构
在本文中,我们提出了一个更简单、更高效的生成对抗网络,称为 AnimeGAN。 AnimeGAN 由两个卷积神经网络组成:一个是生成器 G,用于将现实世界场景的照片转换为动漫图像; 另一个是判别器 D,它区分图像是来自真实目标域还是来自生成器产生的输出。 AnimeGAN 的架构如图 1 所示。

在图 1 中,AnimeGAN 的生成器可以被认为是一个对称的编码器-解码器网络,它主要由标准卷积、深度可分离卷积 [4]、反向残差块(IRB)[24 ],上采样和下采样模块。 在生成器中,最后一个具有 1×1 卷积核的卷积层不使用归一化层,后面是 tanh 非线性激活函数。
Conv-Block、DSConv 和反转残差块的结构如图 2 所示。Conv-Block 由具有 3×3 卷积核的标准卷积、实例归一化层 [27] 和 LRelu 激活函数组成 [19]。 DSConv 由具有 3 × 3 卷积核的深度可分离卷积、实例归一化层和 LRelu 激活函数组成。 反转残差块包含 Conv-Block、深度卷积、逐点卷积和实例归一化层。

为了避免max-pooling造成的特征信息丢失,提出的Down-Conv作为下采样模块来降低特征图的分辨率。 Down-Conv 的架构如图 2 所示。它包含步幅为 2 的 DSConv 模块和步幅为 1 的 DSConv 模块。在 Down-Conv 中,特征图的大小调整为输入特征图大小的一半。 Down-Conv 模块的输出是步长为 2 的 DSConv 模块和步长为 1 的 DSConv 模块的输出之和。
提出的 Up-Conv 用作上采样模块以提高特征图的分辨率。 Up-Conv 的架构也如图 2 所示。在 Up-Conv 中,特征图的大小被调整为输入特征图大小的 2 倍。 使用 Up-Conv 模块代替文献 [3] 中使用的步幅为 12 的部分步幅卷积层。 原因是文献[3]中使用的上采样方法会导致合成图像中出现棋盘伪影[22],影响图像质量。
为了有效减少生成器的参数数量,我们在网络中间使用了 8 个连续且相同的 IRB。 与标准残差块 [10] 相比,IRB 可以显着减少网络的参数数量和计算工作量。 生成器中使用的 IRB 包括具有 512 个内核的逐点卷积、具有 512 个内核的深度卷积和具有 256 个内核的逐点卷积。 值得注意的是,最后一个卷积层没有使用激活函数。
作为生成器网络的补充,我们使用与文献 [3] 中相同的鉴别器网络。 鉴别器的架构如图1所示。鉴别器中的所有卷积层都是标准卷积。 对于每个卷积层的权重,使用谱归一化[21]使网络训练更加稳定。
损失函数
我们将现实世界的照片转换为动画图像的方法制定为图像到图像的映射模型,该模型将照片域 P P P 映射到动画域 A A A。AnimeGAN 使用未配对的训练数据进行训练。 S d a t a ( p ) = { p i ∣ i = 1 , ⋅ ⋅ ⋅ , N } ⊂ P S_{data}(p) = \{p_i | i = 1, ··· , N\} ⊂ P Sdata(p)={pi∣i=1,⋅⋅⋅,N}⊂P 和 S d a t a ( a ) = { a i ∣ i = 1 , ⋅ ⋅ ⋅ , M } ⊂ A S_{data}(a) = \{a_i | i = 1, ··· , M\} ⊂ A Sdata(a)={ai∣i=1,⋅⋅⋅,M}⊂A,其中 N N N 和 M M M 分别是训练集中照片和动画图像的数量。
在我们的任务中,动画图像的纹理而不是颜色被转移到照片图像中。 我们使用灰度 Gram 矩阵使生成的图像具有动漫图像的纹理而不是动漫图像的颜色。 因此,有必要将动画图像转换为灰度图像,以消除颜色干扰。 S d a t a ( a ) S_{data}(a) Sdata(a)中的彩色动画图像 a i a_i ai被转换为灰度图像 x i x_i xi。 灰度动画训练数据 S d a t a ( x ) = { x i ∣ i = 1 , ⋅ ⋅ ⋅ , M } ⊂ X S_{data}(x) = \{x_i | i = 1, ··· , M\} ⊂ X Sdata(x)={xi∣i=1,⋅⋅⋅,M}⊂X 对应彩色动画域 S d a t a ( a ) S_{data}(a) Sdata(a)。 另外,参考文献[3]中提到,训练数据 S d a t a ( e ) = { e i ∣ i = 1 , ⋅ ⋅ ⋅ , M } ⊂ E S_{data}(e) = \{e_i | i = 1, ··· , M\} ⊂ E Sdata(e)={ei∣i=1,⋅⋅⋅,M}⊂E 是通过去除训练数据 S d a t a ( a ) S_{data}(a) Sdata(a) 中动画图像的边缘来构造的。 在我们的方法中,我们将 S d a t a ( e ) S_{data}(e) Sdata(e) 中的图像进一步处理成灰度图像以获得 S d a t a ( y ) S_{data}(y) Sdata(y)。 原因是为了避免 S d a t a ( e ) S_{data}(e) Sdata(e)中图像颜色对生成图像颜色的影响。
为了使AnimeGAN能够生成更高质量的图像并使整个网络的训练更加稳定,LSGAN [20]中的最小二乘损失函数被用作对抗性损失 L a d v ( G , D ) L_{adv}(G, D) Ladv(G,D)。 AnimeGAN中使用的损失函数 L ( G , D ) L(G, D) L(G,D)可以简单表示如下:

其中 L a d v ( G , D ) L_{adv}(G, D) Ladv(G,D) 是在生成器 G G G 中影响动画转换过程的对抗性损失, L c o n ( G , D ) L_{con}(G, D) Lcon(G,D) 是有助于使生成的图像保留输入照片内容的内容损失, L g r a ( G , D ) L_{gra} (G, D) Lgra(G,D) 表示灰度样式损失,使生成的图像在纹理和线条上具有清晰的动漫风格。 由于使用灰度样式损失很容易导致生成的图像显示为灰度图像,因此使用 L c o l ( G , D ) L_{col}(G, D) Lcol(G,D)作为颜色重建损失,使生成的图像具有原始照片的颜色。 ω a d v ω_{adv} ωadv、 ω c o n ω_{con} ωcon、 ω g r a ω_{gra} ωgra 和 ω c o l ω_{col} ωcol 是平衡四个给定损失函数的权重。 在我们所有的实验中,我们设置了 ω a d v = 300 ω_{adv} = 300 ωadv=300、 ω c o n = 1.5 ω_{con} = 1.5 ωcon=1.5、 ω g r a = 3 ω_{gra} = 3 ωgra=3 和 ω c o l = 10 ω_{col} = 10 ωcol=10,从而实现了风格和内容保存的良好平衡。
生成器中使用的损失函数包括最小二乘损失函数、内容损失函数、灰度损失函数和颜色重建损失函数。 对于内容损失 L c o n ( G , D ) L_{con}(G, D) Lcon(G,D) 和灰度风格损失 L g r a ( G , D ) L_{gra}(G, D) Lgra(G,D),使用预训练的 VGG19 作为感知网络,提取图像的高级语义特征。 L c o n ( G , D ) L_{con}(G, D) Lcon(G,D) 和 L g r a ( G , D ) L_{gra}(G, D) Lgra(G,D) 可以表示为:

其中 V G G l ( • ) VGG_l(•) VGGl(•) 指的是 VGG 中第 l l l 层的特征图,“•”表示输入。 在我们的方法中,第 l l l 层是 VGG 中的“conv4-4”。 Gram 表示特征的 Gram 矩阵。 G ( p i ) G(p_i) G(pi)表示生成的图像, p i p_i pi 表示输入的照片。 l 1 l1 l1稀疏正则化用于计算 L c o n ( G , D ) L_{con}(G, D) Lcon(G,D)和 L g r a ( G , D ) L_{gra}(G, D) Lgra(G,D)。
为了使图像颜色重建更好,我们将RGB格式的图像颜色转换为YUV格式来构建颜色重建损失 L c o l ( G , D ) L_{col}(G, D) Lcol(G,D)。 在 L c o l ( G , D ) L_{col}(G, D) Lcol(G,D) 中, L 1 L1 L1 损失用于 Y Y Y 通道,Huber 损失用于 U U U 和 V V V 通道。 形式上, L c o l ( G , D ) L_{col}(G, D) Lcol(G,D) 可以定义为:
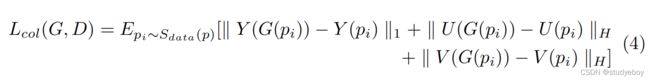
其中 Y ( p i ) Y(p_i) Y(pi)、 U ( p i ) U(p_i) U(pi)、 V ( p i ) V(p_i) V(pi)分别代表YUV格式的图像 p i p_i pi的三个通道, H 代 H代 H代表Huber Loss。 最后,生成器的损失函数可以表示为:

对于判别器使用的损失函数,除了引入边缘促进对抗性损失[3]使AnimeGAN生成的图像具有清晰再现的边缘外,还使用了一种新颖的灰度对抗性损失来防止生成的图像显示为 灰度图像。 最后判别器的损失函数表示为:

其中 E y i ∼ S d a t a ( y ) [ ( D ( y i ) ) 2 ] E_{y_i}∼S_{data}(y)[(D(y_i))^2] Eyi∼Sdata(y)[(D(yi))2] 表示边缘促进对抗性损失, E x i ∼ S d a t a ( x ) [ ( D ( x i ) ) 2 ] E_{x_i}∼S_{data}(x)[(D(x_i))^2] Exi∼Sdata(x)[(D(xi))2] 表示灰度对抗性损失。 0.1 是比例因子。 将边缘促进对抗性损失的比例因子设置为 0.1 的目的是避免生成图像的边缘过于锐利。
训练
所提出的 AnimeGAN 可以很容易地使用未配对的训练数据进行端到端训练。 由于 GAN 模型是高度非线性的,通过随机初始化,优化很容易陷入次优的局部最小值。 文献 [3] 表明生成器的预训练有助于加速 GAN 收敛。 因此,生成器网络 G G G 仅使用内容损失 L c o n ( G , D ) L_{con}(G, D) Lcon(G,D) 进行了预训练。 初始化训练进行了一个 epoch,学习率设置为 0.0001。
对于 AnimeGAN 的训练阶段,生成器和判别器的学习率分别为 0.00008 和 0.00016。 AnimeGAN 的训练周期为 100,批量大小设置为 4。Adam 优化器 [14] 用于最小化总损失。 AnimeGAN 使用 Tensorflow [1] 在 Nvidia 1080ti GPU 上进行训练。
实验
数据
所提出的 AnimeGAN 可以很容易地进行端到端训练,以使用未配对的数据生成高质量的动漫风格图像。 以真实世界照片作为内容图像和动漫图像作为风格图像作为训练数据,测试数据只包括真实世界的照片。 所有训练图像的分辨率设置为 256 × 256。对于内容图像,使用 6, 656 张真实照片进行训练,这些照片已用作 CycleGAN [30] 的训练数据。 对于风格图像,由于不同的动画艺术家有自己独特的动画创作风格,为了获得一系列风格相同的动画图像,我们使用同一艺术家绘制和导演的动画电影的关键帧作为 风格的图像。 在我们的实验中,使用宫崎骏导演的电影《起风了》中的1792张动画图像来训练宫崎骏风格的模型,使用新海诚导演的电影《你的名字》中的1650张动画图像来训练新海诚 Kon Satoshi 导演的电影《Paprika》中的风格模型和 1553 幅动画图像用于训练 Kon Satoshi 风格模型。
结果
我们首先将 AnimeGAN 与两种最先进的动漫风格转移方法,即 CartoonGAN [3] 和 ComixGAN [23] 进行比较。 值得注意的是,CartoonGAN 和 ComixGAN 具有相同的网络结构和损失函数。 它们之间的区别在于,ComixGAN 使用了不同的训练策略,并将动画风格迁移应用于视频。 此外,AnimeGAN 使用的鉴别器架构与 CartoonGAN 使用的相同。 AnimeGAN 使用的判别器是模型大小为 4.30M 的轻量级卷积神经网络。 对于不同的生成器,它们在模型大小、参数数量和计算成本方面的比较如表 1 所示。在表 1 中,每张输入照片的大小为 256 × 256 用于推理。
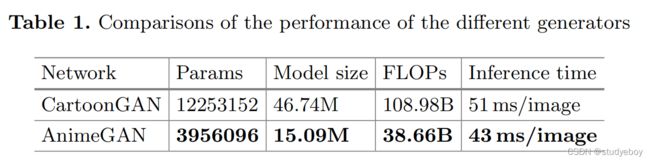
从表1可以看出,与CartoonGAN相比,AnimeGAN显着减少了参数数量和计算成本,并且具有更快的推理速度。
CartoonGAN、ComixGAN 和 AnimeGAN 的定性结果如图 3 所示。可以清楚地看到这三种方法都可以有效地捕捉动漫风格。 然而,CartoonGAN 生成的图像在局部区域产生了明显的彩色伪影,失去了原始内容图像的颜色。 ComixGAN 生成的图像在局部区域很容易过度风格化,从而导致生成的图像丢失了原始照片的内容。 AnimeGAN 生成的图像可以有效地保留照片的内容和照片中相应区域的颜色。 与 CartoonGAN 和 ComixGAN 相比,AnimeGAN 可以产生更高质量的动画视觉效果。
值得注意的是,AnimeGAN 的对抗性损失远小于内容损失和灰度样式损失。 为了平衡不同损失对网络性能的影响,我们需要对不同损失进行合理的加权。 如果内容损失的权重过大,生成的图像会非常接近真实照片。 如果灰度样式损失的权重过大,生成的图片会丢失原始照片的内容。在实验中,内容损失和灰度样式损失的权重分别设置为 1.5 和 3.0。 这两个损失比其他损失大,必须赋予较小的权重。
为了进一步研究权重对生成图像质量的影响,我们比较了对抗性损失权重和颜色重建损失权重对生成图像的影响。 对比结果如图4所示。与 ω c o l = 10 ω_{col} = 10 ωcol=10和 ω a d v = 300 ω_{adv} = 300 ωadv=300的AnimeGAN相比, ω c o l = 10 ω_{col} = 10 ωcol=10和 ω a d v = 250 ω_{adv} = 250 ωadv=250的AnimeGAN生成的图像更接近输入照片,生成的图像没有明显的动画 风格。 AnimeGAN 生成的 ω c o l = 10 ω_{col} = 10 ωcol=10 和 ω a d v = 350 ω_{adv} = 350 ωadv=350 的图像虽然具有明显的动画风格,但生成图像的色调会受到训练数据风格的影响。 如图 4 的第三列所示,AnimeGAN 生成的 ω c o l = 10 ω_{col} = 10 ωcol=10 和 ω a d v = 350 ω_{adv} = 350 ωadv=350 的图像有明显的深绿色。
从图4的最后两列可以看出,与 ω c o l = 10 ω_{col} = 10 ωcol=10的AnimeGAN相比, ω c o l = 50 ω_{col} = 50 ωcol=50的AnimeGAN生成的图像内容更逼真,但图像的动画风格并不明显。 因此,当 ω c o l = 10 ω_{col} = 10 ωcol=10 和 ω a d v = 300 ω_{adv} = 300 ωadv=300 时,AnimeGAN 生成的图像具有令人满意的动画视觉效果。
颜色重建损失本质上是生成图像的像素与输入照片的像素之间的比较。 如果其权重设置过大,则生成的图像更接近输入照片。
为了进一步研究灰度图像对结果的影响,我们进行了消融实验,以分析灰度对抗性损失和用于边缘促进对抗性损失的模糊灰度边缘图像 S d a t a ( y ) S_{data}(y) Sdata(y) 的有效性。 在图5中,“A”表示AnimeGAN在不使用灰度对抗性损失的情况下生成的推理结果,“B”表示AnimeGAN使用 S d a t a ( e ) S_{data}(e) Sdata(e)中的模糊颜色边缘图像进行边缘提升生成的推理结果 对抗性损失,“C”表示AnimeGAN生成的推理结果。 A 和 B 的结果相似。 C和B的区别在于 S d a t a ( e ) S_{data}(e) Sdata(e)中的边缘模糊彩色图像被处理成 S d a t a ( y ) S_{data}(y) Sdata(y)中的灰度图像,以避免边缘模糊图像对生成结果的颜色影响。 与C相比,A中的颜色不够丰富和饱和。 因此,灰度对抗性损失可以促进生成的图像具有更饱和的颜色。
与 B 相比,使用来自 S d a t a ( y ) S_{data}(y) Sdata(y) 的灰度数据进行边缘促进对抗性损失,不仅可以使生成的图像具有清晰的边缘,而且可以使生成的图像具有更饱和的色彩。
为了充分验证AnimeGAN对照片动画的能力,在三个动画风格数据集上进行了大量的实验。
实验结果如图 6 所示。可以看出,AnimeGAN 成功地学习了三位不同艺术家的动画风格,并生成了高质量的动画视觉图像。
结论
在本文中,我们提出了 AnimeGAN,它是一种轻量级的生成对抗网络,可以将真实世界的照片快速转换为高质量的动漫风格图像。 本文的主要贡献如下:1)新颖的灰度风格损失,用于变换动漫风格的纹理和线条; 2) 新颖的颜色重建损失来保留内容图像的颜色; 3)新颖的灰度对抗性损失,用于防止生成的图像显示为灰度图像; 4)轻量级生成器,使用深度可分离卷积和反向残差块来实现更快的传输。 实验表明,AnimeGAN 可以将现实世界场景的照片转换为具有高质量动画视觉效果的动漫风格图像,并且明显优于最先进的风格化方法。 在实验中,我们还分析了灰度对抗性损失和权重对生成图像质量的影响。 我们发现适当的权重和灰度对抗性损失可以有效地提高生成图像的质量。 在未来的工作中,为了实现更快的动画风格迁移,我们将进一步研究更轻量级的 GAN,以实现在小型移动设备上的实时应用。 此外,还考虑将 AnimeGAN 的推理阶段集成到视频处理管道中,以实现视频的动画风格转换。
论文解读
论文阅读 | AnimeGAN



源码(TensorFlow版本)
TchibanaYoshino/AnimeGAN
建议
- 由于训练集中的真实照片都是风景照片,如果要对以人物为主体的照片进行风格化,不妨在训练集中加入至少3000张人物照片,重新训练得到一个新模型。
- 为了获得更好的人脸动画效果,在使用2张图片作为数据对进行训练时,建议照片中的人脸与动漫风格数据中的人脸在性别上尽量保持一致。
- 生成的风格化图像会受到风格数据的整体亮度和色调的影响,所以尽量不要选择夜晚的动漫图像作为风格数据,需要对整体风格数据进行曝光补偿以促进 整个风格数据的明暗一致性。
需求

使用
- inference
python test.py --checkpoint_dir checkpoint/generator_Hayao_weight --test_dir dataset/test/real --style_name H
- train

源码(PyTorch版本)
ptran1203/pytorch-animeGAN
AnimeGANv3
源码
TachibanaYoshino/AnimeGANv3
训练管道
使用
无需安装任何其他依赖项,下载此存储库并使用 AnimeGANv3 的图形用户界面程序 (AnimeGANv3.exe) 和预训练模型 (onnx.zip) 将您的照片或视频转换为动画。
结果
参考资料
动漫风格迁移 AnimeGANv2,发布线上运行 Demo
论文阅读 | AnimeGAN
GGFly/人脸动漫风格最强模型AnimeGAN PyTorch版本