keras之网络冻结训练机制
1. 构建神经网络
这里以简单的 cnn 网络为例
注意:由于我在第 2步中冻结了输出层的参数,为了与其他层进行区分,我在定义网络的时候给输出层起了个名字,“output”,如果不使用网络中的 name属性对网络命名,那么系统会在 .summary 的时候自动给网络的层分配命名。
import keras,os
from keras.models import Sequential
from keras.layers import Dense, Conv2D, MaxPool2D , Flatten, Lambda,Dropout,Concatenate
from keras.preprocessing.image import ImageDataGenerator
import numpy as np
from keras_applications.imagenet_utils import _obtain_input_shape
from keras import backend as K
from keras.layers import Input, Convolution2D, GlobalAveragePooling2D, Dense, BatchNormalization, Activation
from keras.models import Model
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
def cnn():
model = Sequential()
model.add(Conv2D(input_shape=(28,28,1),filters=16,kernel_size=(3,3),padding='same',activation='relu'))
model.add(Conv2D(filters=32,kernel_size=(3,3),padding='same',activation='relu'))
model.add(Conv2D(filters=64,kernel_size=(3,3),padding='same',activation='relu'))
model.add(MaxPool2D())
model.add(Dropout(rate=0.3))
model.add(Conv2D(filters=128,kernel_size=(3,3),padding='same',activation='relu'))
model.add(Conv2D(filters=256,kernel_size=(3,3),padding='same',activation='relu'))
model.add(MaxPool2D())
model.add(Dropout(rate=0.3))
model.add(Flatten())
model.add(Dense(512,activation='relu',name='teacher_feature'))
model.add(Dense(10,activation='softmax',name='output'))
# model.add(Activation('softmax'))
return model
【查看网络结构】
cnn_net = cnn()
cnn_net.summary()
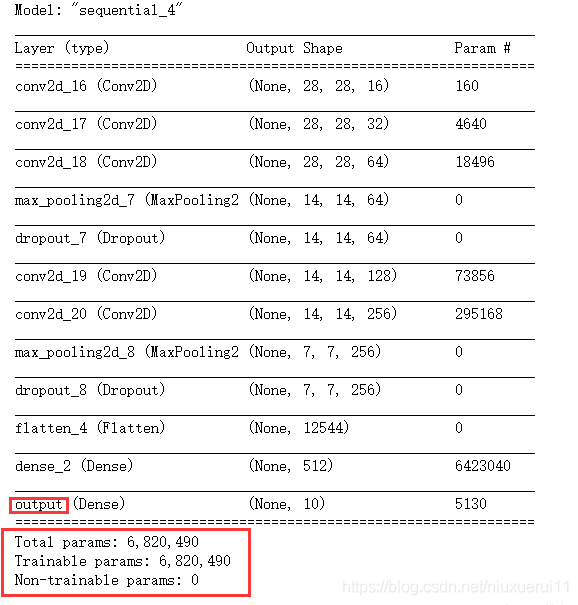
可以看出,所有的权重参数都是可以训练的,都是trainable的。
2. 冻结特定层的网络权重
这里以输出层的权重为例,冻结输出层的参数,让我们来看看输出的结果是什么:
for layer in cnn_net.layers:
if layer.name == 'output':
layer.trainable = False
cnn_net.compile(optimizer = opt, loss=loss, metrics=['accuracy'])
print(cnn_net.summary())
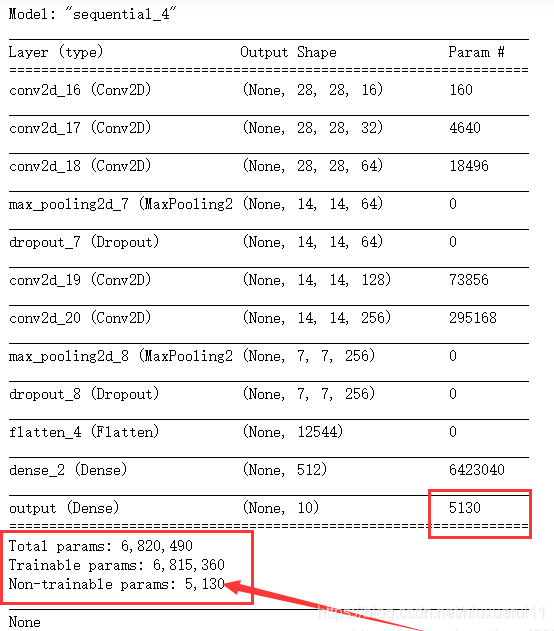
可以看到,最后一层的参数果然被冻结了。
接下来我们看一下,冻结了部分参数的神经网络在训练的时候会输出与平时怎样不同的结果
注意:冻结网络层之后,最好对网络重新 compile 一下,否则在一些场景下不会生效,compile 才会生效。
3. 冻结与非冻结的效果对比
3.1 冻结网络训练的结果
from keras.datasets import fashion_mnist,cifar10,cifar100
from keras.datasets import mnist
from keras.utils import to_categorical
import keras.optimizers
from keras.losses import categorical_crossentropy
from sklearn.model_selection import train_test_split
(x_train,y_train),(x_test,y_test)= fashion_mnist.load_data()
# x_train = x_train.astype('float32')
# print(x_train.shape)
# print(y_train.shape)
x_train = x_train.reshape(60000,28,28,1)
# x_test = x_test.astype('float32')
x_test = x_test.reshape(10000,28,28,1)
# y_cifar_train = to_categorical(y_cifar_train)
# y_cifar_test = to_categorical(y_cifar_test)
y_test = to_categorical(y_test)
y_train = to_categorical(y_train)
print(x_train.shape)
print(y_train.shape)
opt = keras.optimizers.Adam(learning_rate=0.001)
loss = keras.losses.categorical_crossentropy
cnn_net.compile(optimizer=opt,loss=loss,metrics=['accuracy'])
cnn_net_history = cnn_net.fit(x_train,y_train,batch_size=64,epochs=5,shuffle=True,validation_data=(x_test,y_test))

【将冻结的层解冻】
for layer in cnn_net.layers:
layer.trainable = True
print(cnn_net.summary())
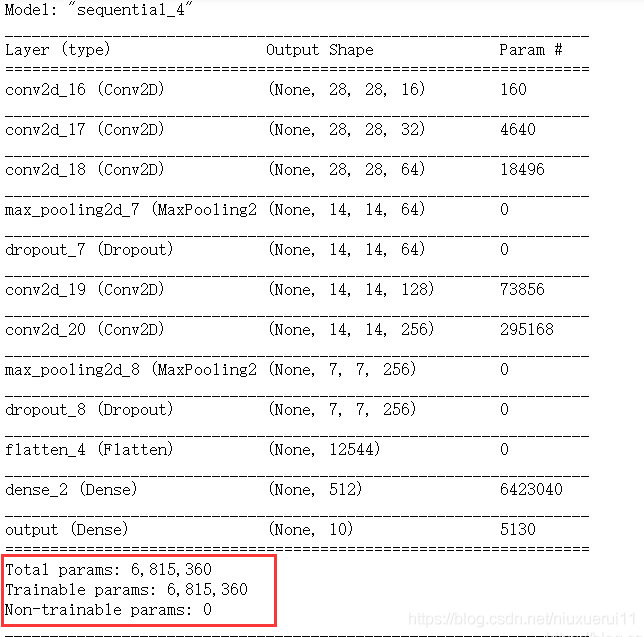
3.2 解冻网络训练的结果
opt = keras.optimizers.Adam(learning_rate=0.001)
loss = keras.losses.categorical_crossentropy
cnn_net.compile(optimizer=opt,loss=loss,metrics=['accuracy'])
cnn_net_history = cnn_net.fit(x_train,y_train,batch_size=64,epochs=5,shuffle=True,validation_data=(x_test,y_test))

3.3 结论
笔者原来天真的以为,当我冻结了最后一层的神经网络,这个神经网络最后输出的结果会是倒数第二层的维度(None,512) 后来我发现是我天真了。
当你的网络结构构建完成之后,无论你是否更新他的参数,他的维度都会按照你设计的网络的神经元的个数来进行变化。
可以看出来,冻结最后一层之后,他的 loss 和不冻结最后一层的训练过程相比,在这个实验中看不出什么差距(本来也只冻结了一层 5000多个参数,相比于整体几百万的参数量,不值一提)
————————————————
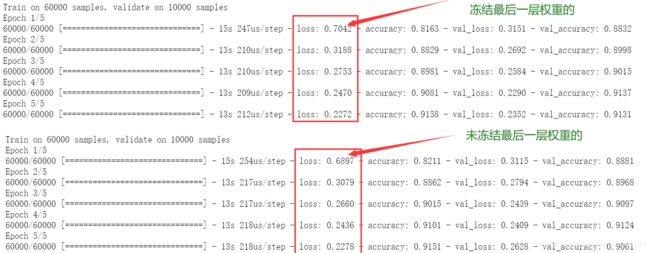
【那么冻结参数的作用是什么呢?】
我们可以通过冻结神经网络的某一层来研究他在训练中起到的作用 也可以在拼接网络的时候减少参数训练量。例如: 当你的网络很复杂,他的前端网络是一个 vgg-16 的分类网络,后面要拼接一个自己写的功能网络,这个时候,你把 vgg-16的网络架构定义好了之后,上网下载 vgg-16 的训练好的网络参数,然后加载到你写的网络中,然后把 vgg-16相关的层冻结掉,只训练你自己写的小网络的参数 这样的话,你就可以省掉很多的运算资源和时间,提高效率。
4. 冻结更多的参数,看是否会降低训练精度
还是使用刚才的网络,我们冻结从 第 6 层 到 倒数第二层的参数:
for layer in cnn_net.layers[5:-1]:
layer.trainable = False
print(cnn_net.summary())
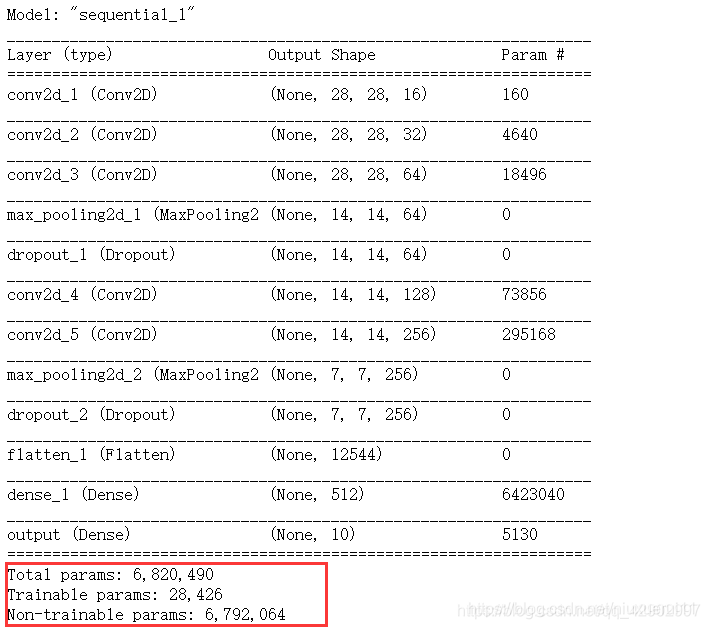
现在被冻结的是绝大多数了,只有 28426 个参数参与了训练。但是训练结果发现:

最后两个 epoch 的时候,网络已经收敛了,而且精度不再上升了,精度比我们之前未冻结的网络要低 5%,但是别忘了我们才仅仅使用了未冻结网络 1/300 的参数量
也就是说,对于 mnist 数据集,我们使用几万个参数已经足以把他训练的很好了。
5. 冻结整个网络的全部参数,看会出现什么情况
for layer in cnn_net.layers:
layer.trainable = False
print(cnn_net.summary())
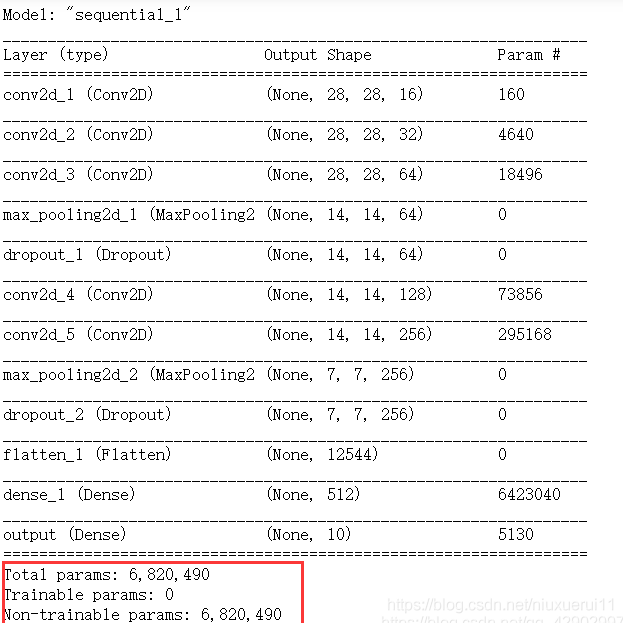
【训练结果】
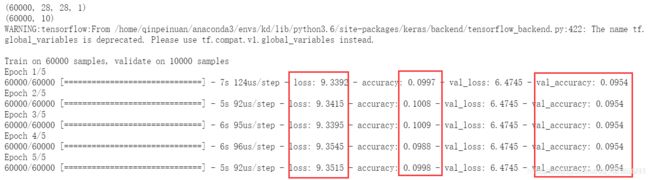
不意外,冻结训练可以使得精度降低。