每周论文精读04——A Survey on 3D Hand Pose Estimation: Cameras, Methods, and Datasets
论文精读——A Survey on 3D Hand Pose Estimation: Cameras, Methods, and Datasets
本周所进行精读的一篇文章是手势估计领域的一篇综述文章,由浙江大学撰写与2019年发表在PR期刊上,篇幅较长,内容丰富,比较详细的综述了自2010年Kitnet 问世以来对于手势估计的应用与研究。
废话不多说,进入正文部分了:
#############################################################################
文章来源
题目:A Survey on 3D Hand Pose Estimation: Cameras, Methods, and Datasets
三维手位估计综述:摄像机、方法和数据集
引用:[1] Li R , Liu Z , Tan J . A Survey on 3D Hand Pose Estimation: Cameras, Methods, and Datasets[J]. Pattern Recognition, 2019.
链接&下载地址:
百度学术:https://xueshu.baidu.com/usercenter/paper/show?paperid=1w240j20b5230420kw580er0pf775254&site=xueshu_se
下载地址:https://www.sciencedirect.com/science/article/pii/S0031320319301724
论文我也已经下载好上传到了CSDN中,可以点下方直接下载:
》》》论文连接《《《
一些相关连接
开源代码:
性能比较(paper with code):
文章简介
内容简介:
A Survey on 3D Hand Pose Estimation: Cameras, Methods, and Datasets
三维手位估计综述:摄像机、方法和数据集
3D Hand pose estimation has received an increasing amount of attention, especially since consumer depth cameras came onto the market in 2010. Although substantial progress has occurred recently, no overview has kept up with the latest developments. To bridge the gap, we provide a comprehensive survey, including depth cameras, hand pose estimation methods, and public benchmark datasets. First, a markerless approach is proposed to evaluate the tracking accuracy of depth cameras with the aid of a numerical control linear motion guide. Traditional approaches focus only on static characteristics. The evaluation of dynamic tracking capability has been long neglected. Second, we summarize the state-of-the-art methods and analyze the lines of research. Third, existing benchmark datasets and evaluation criteria are identified to provide further insight into the field of hand pose estimation. In addition, realistic challenges, recent trends, dataset creation and annotation, and open problems for future research directions are also discussed.
三维手姿势估计已经受到越来越多的关注,特别是自从消费者深度相机在2010年上市以来。虽然最近取得了实质性进展,但没有任何概览跟上最新的发展。为了弥补这一差距,我们提供了一个全面的调查,包括深度相机,手姿势估计方法,和公共基准数据集。首先,提出了一种基于数控直线运动导轨的无标记深度相机跟踪精度评估方法。传统的方法只关注静态特性。长期以来,动态跟踪能力的评估一直被忽视。其次,总结了国内外的研究方法,分析了本文的研究思路。第三,现有的基准数据集和评估标准,以提供进一步的洞察领域的手姿势估计。此外,还讨论了数据集的创建和注释的现实挑战、最新发展趋势以及有待进一步研究的问题。
(上面的仅是摘要与摘要翻译)
主要贡献&创新点
- 综述了基于RGB-D图像的手部姿态估计问题,系统的论述了数据集、相机、方法(算法)。
- 提出了一种深度相机动态跟踪精度评估方法,并进行了实验与评估
阅读印象&感想
- 事实上手部姿态检测问题不纯是由深度学习方法进行估计的,甚至还有一些基于模型的启发式优化算法,而针对二者优点相结合的算法也存在,如上上周精读的文献 DETnet+IKnet 就是一个比较典型的例子。
- 和PSO等启发式算法不同的是,这些算法是非数据依赖的,而深度学习方法是非常依赖于数据的,这个以来不仅体现在数据的需求量上,也体现在数据的真实性方面。
- 事实上基于计算机视觉的手势估计方面的研究分类较细,需要做到什么要求以及需要达到何种特征需要视情况而定。结合具体的项目要求去选取以及使用,不应该盲目的去选择。
关键点记录
正文部分.
########################################
1. 引言部分
从无标记的视觉观测中估计手的姿势是一个有趣的研究课题,因为人类可以毫不费力地解决这个问题。从面向应用的角度来看,手势估计有望实现基于非接触手势的人机交互,因此对于沉浸式虚拟现实(VR)和增强现实(AR)具有非常重要的实际意义。手姿势估计已应用于手势识别[3]、交互式游戏[4–7]、用户界面控制[8–11]、计算机辅助设计(CAD)[12]、手形个性化[13–16]、手语[17–19]、空中交互[20–22]、动作识别[23,24118159],它在其他领域也有巨大的应用潜力,如机器人抓取[25–28185]。近年来,商业深度相机(如Kinect)极大地推动了基于深度图的手部姿态估计的研究。虽然进行了大量的工作,但最近没有进行全面的调查。据我们所知,当前出版物中最具参考价值的基于视觉的调查是由Erol等人[29]在2007年提出的,但自那时以来,手姿势估计领域发展迅速。
我们工作的另一个动机是,研究人员不太重视对于深度相机的研究。现有的基准数据集是使用各种摄像机发布的,但摄像机的动态跟踪精度一直没有得到仔细的研究。
与人体姿态估计不同,手部姿态估计的精度要求相对较高。相机制造商提供的技术规范无法充分支持手姿势估计研究。传统的方法只能测量摄像机的静态精度。明确动态跟踪精度不仅有助于重新评估现有的手位估计方法,而且为发布新的基准数据集提供有价值的指导。为此,我们设计了一种动态跟踪精度的实验装置。鉴于上述事实,我们认为现在是对手姿势估计再次进行深入综述的时候了。
1.1 相关工作 Related work
2007年,Erol等人[29]提出了一个基于视觉的手姿势估计综述,涵盖了所涉及的挑战、手建模、各种方法的优缺点以及未来研究的潜在问题。这篇综述是对以往研究进行比较全面、深入总结的一篇罕见的著作。在回顾中提到的33种方法中,只有4种方法使用了深度相机。因为当时深度相机和基于深度的手姿势估计研究并不流行,所以深度相机、基准数据集或评估标准没有在综述中提及。
我们的研究范围和方法与Erol等人的研究方法有很大的不同。我们专注于2010年之后提出的基于深度或RGB-d的手姿势估计方法;我们排除了早期的方法,因为随着Kinect v1的出现,深度相机在2010年真正吸引了研究人员的注意力,这是一个里程碑。在我们的调查中,以表格的形式总结了101个最先进的方法和22个数据集。在方法上,分析了研究思路和建模方案。对于数据集,我们分析了创建方法、注释技术和定量评估指标。不像一般的综述只关注理论总结,我们还进行了一系列的实验设计仪器。
Barsoum[32]在近几年回顾总结了三个基准数据集和不到二十种方法。只有两种方法是在深度学习的框架下构建的。Barsoum因此得出结论,由于注释数据集的数量较少,深度学习并没有像其他计算机视觉任务那样广泛地应用于手姿势估计。我们持有相反的观点,即当前的建模解决方案已经被深度学习所主导,尽管距离Barsoum的重新审视只有大约三年的时间。从数据集和方法的完整性来看,我们的综述远比Barsoum提出的观点更具包容性和全面性,因此我们认为我们的结论更有分量。
除了Erol等人[29]和Bar-soum[32]给出的两个综述外,我们还没有发现其他的手姿势估计综述。一些研究人员[30–31,151]对手姿势估计方法或/和数据集的总结非常有限。严格地说,这样的作品不能算是一种总结与综述。Supancic等人[30]在统一评分标准下对13种手姿势估计方法进行了评价,并总结了9个基准数据集。他们引入了一个新的基准数据集,并提出了一种最近邻基线方法。他们的工作目标之一是强调训练数据的重要性。
袁等[31]在3个任务中研究了11种手姿势估计方法:单帧手姿势估计、手跟踪和目标交互过程中的手姿势估计。他们努力回答两个问题:三维手姿势估计的现状如何?接下来需要应对的挑战是什么?袁等[151]介绍了一个大规模的基准数据集,并总结了现有的十个基准数据集。他们使用多个数据集训练了一个CNN(卷积神经网络),以研究交叉基准性能,并用八种最先进的方法训练了CNN。
一些研究调查了手姿势估计的准备工作与相关工作。如S:ridhar等人[22]系统地研究了使用多个手指进行空中文本输入的灵活性。他们报告了每个手指的速度、准确性、个性化、运动范围和个体差异。Gustus等人[169]概述了在运动学、mus-culotendon结构以及两者结合的层面上的数学手建模。Wheatland等人[170]回顾了手和手指建模和动画领域的研究。详细讨论了手的生物结构及其对手运动的影响。这些研究为研究手部姿势的交互能力提供了有价值的参考,在许多方面与我们的研究是相辅相成的。
1.2. 问题表述 Problem formulation
在大多数情况下,从深度或RGB-D估计三维手姿势的任务是提取一组预定义的手关节位置。具体来说,输入是包含人手的深度或RGB-D数据,输出是k3d手关节位置。设K个手关节的位置为={φK}kk=1∈,其中φK=(xk,yk,zk),是3×K维手位空间。图1a示出了合成手骨架。忽略关节角度约束,手有25–50个自由度(DoF)[29]。图1b显示了一个具有26个自由度的典型手运动学模型[33–35],其中手指骨骼在力学中被视为连杆,手关节被视为运动副。图1c中示出了21个手关节和连接结构的示例。对于不同的方法,手关节的位置和数量可能不同。
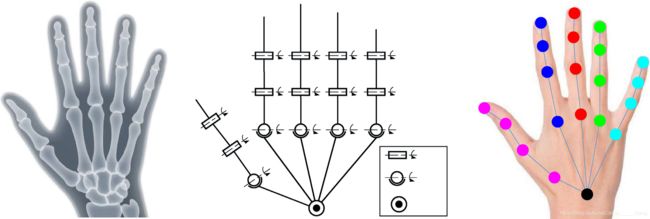
图1.手部模型:(a) 合成手骨架 (b) 26自由度运动学模型 (c) 手关节及连接结构
一些方法,例如Sinha等人[34]、Choi等人[120]和Zhou等人[46]提出的方法,通过关节角度(包括横摇、俯仰和偏航角)来描述手的姿势。关节角度表示法的优点是更容易考虑手指运动的严格约束。缺点是关节角度表示不能直接与源深度贴图连接。
一些方法以网格[5]或几何元素[84–85,96]的形式估计手的姿势。这些方法完成的任务与通过关节角度或关节位置描述手姿势的方法相同,因此可以与基于关节角度或关节位置的方法进行比较[5151];例如, Yuan等人[151]在同一基准数据集上评估了Oikonomidis等人[84]提出的基于几何元素的方法和Ye等人[139]提出的基于联合位置的方法。
基于深度的手姿估计方法有两种。第一种方法只对深度序列进行操作,因为它依赖于帧顺序或时间一致性[5,96,99]。**第二种方法可以处理单个深度图[135163165]。如果计算效率足够高,第二类方法自然也可以应用于深度序列。然而,由于完全忽略了帧的阶数,估计的邻域姿态的平滑性可能无法得到保证。**此外,当前大多数方法适用于深度相机固定的情况,但也存在基于自我中心视点的手姿势估计[9102113]。
有六个跟手姿势估计相近相关的研究领域,图2提供了直观的图像比较。手势识别的目的是对一组离散的手势进行分类,这有时与手势估计有关,例如[3]中提出的手势估计方法就是针对手势识别的。但手势识别不一定依赖于手的姿势估计;例如,Chen等人[36]提出的手势识别方法就是一个例子。学者们目前已经对手势识别进行了深入的研究。因此纯手势识别方法被排除在我们的综述之外。
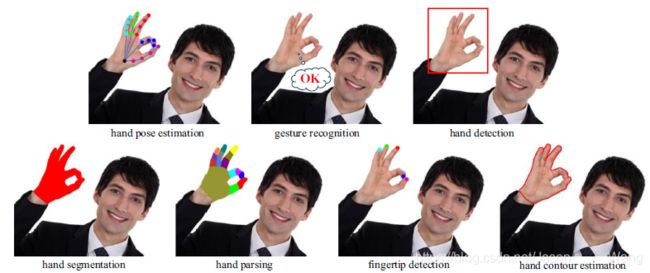
图2 :手位估计及其相似领域的比较
分别对应上述图中七类问题:
hand pose estimation 手姿势估计
gesture recognition 手势识别
hand detection 手部检测
hand segmentation 手部分割
hand parsing 手部解析
fingertip detection 指尖检测
hand contour estimation 手轮廓估计
手姿态估计 手势识别 手部检测 手部分割 手部解析 指尖检测 手轮廓估计
手部检测(或手部跟踪)的目标是检测手部的位置。手通常由一个点或边界框来定位[37]。特别是,一些人体姿势估计方法以单手关节的形式实现手的检测[38–40]。手部分割通过一个二进制掩模[24]更精确地定位手部,该掩模可被视为手部检测的图像增强。目前,纯三维手部检测方法和三维手部分割方法的数量很少。
对于从深度图估计手的姿势,可以看出手的背景几乎总是干净的。在这种情况下,手部检测本质上等同于手部分割,因为检测到的手部可以通过深度距离阈值进行细化。**手分割通常用作深度图中手姿势估计的初始化。**这就是为什么手分割的研究可以在一些手姿势估计方法中找到。我们的综述不包括纯手检测方法或手分割方法。
手部解析的目的是把一只手分成不同的语义部分[1,4,41–43]。虽然每一个语义部分都可以通过某种方式转换为一个手关节,但我们不应该认为手解析隐含地实现了手的姿势估计。这是因为手的解析方法可能只处理可见的手部,而对于手的姿态估计,需要同时预测可见和不可见的手关节。纯手部解析方法不包括在我们的调查中。
指尖检测[10]本质上是手姿势估计的部分或退化版本,其目标是估计五个指尖位置。指尖检测方法包括在我们的综述中。
手轮廓估计的目标是检测手的外部闭合轮廓[171]。与手部分割不同的是,没有考虑手指关节形成的内部轮廓。手轮廓估计不反映手关节信息,因此不包括在我们的综述中。
由于上述领域的相似性,很多研究并没有对它们进行区分,例如[44,58,84–86,96113]中所谓的手跟踪实际上是手姿势估计,而[11140]中所谓的手分割实际上是手解析。**在少数情况下,手姿势估计称为手姿势检测[102]或手姿势恢复[119,128,140]。**因此,读者应该注意到,我们在调查中所称的手姿势估计可能与引用的论文中的其他名称相对应。对于一般的论文来说,上述领域之间的严格区分确实是没有必要的,因为读者可以从上下文中理解真正的意义。
我们之所以对这些领域进行明确的区分是为了说明我们的讨论范围:我们主要考虑2010年之后提出的方法,这些方法最能够从深度或RGB-D完成三维手姿势估计的任务;例如,2017年Madadi等人[140]提出了一种同时实现手解析和手姿势估计的方法,我们的综述包含了该方法。
1.3. 二维和三维手部姿态估计 2D and 3D hand pose estimation
现在我们来说明2D和3D手姿势估计之间的区别。目前流行的深度相机提供了几乎同步的RGB视频和深度图,由此产生了一类以RGB-D序列作为运动数据的三维手姿态估计方法。对于基于RGB-D的方法[6,84–86,92–96],RGB视频仅仅是通过皮肤检测实现手部分割的辅助数据,深度图是真正用于提取手部姿势的主要运动数据。
**三维手姿势估计不一定需要深度图。研究人员试图由纯RGB数据估计3D手姿势[156172–180187]。与纯RGB数据相比,深度图具有形状信息好、对阴影和光照不敏感、抗杂波能力强等优点,同时也存在能耗大、形状因子差、近距离覆盖不准确、户外使用差等缺点[174]。**深度图由一组嵌入在三维空间中的2.5D表面结构的点云组成,而RGB图像由二维平面结构的栅格像素组成。点和像素之间的差异使得基于深度的方法的建模解决方案与基于RGB的方法的建模解决方案非常不同;例如,基于RGB的方法使用颜色[173]、纹理[172]、边缘[181]、轮廓[182]或光流[176]作为描述符,但是基于深度的方法通常不使用。
与三维手位估计相比,二维手位估计的研究数量非常少[181–182]。**第一个原因是从RGB图像中估计手的姿势比从深度图中估计手的姿势更具挑战性。**毕竟,在单RGB相机设置的情况下,深度信息完全丢失。通常引入多个RGB相机设[176,178,179]和立体RGB相机设置[157,173,174]来实现三维手姿势估计。第二个原因是由于实际应用有限,对驱动二维手位估计的研究需求不大。一些研究人员[156,172,178,182,187]甚至试图用一台RGB相机来估计3D手的姿势。,Carley等人[3]、Spurr等人[162]和Tzionas等人[94]提出的方法可适用于RGB相机和深度相机。总之,基于深度的手部姿态估计是三维手部姿态估计的发展趋势。
1.4. 实际挑战 Realistic challenges
近几年来,手位估计技术取得了很大的进展,但仍然是一个有待解决的问题。现实挑战来自以下七个因素:
•低分辨率。由于深度传感原理的限制,深度图具有噪声和不精确性。此外,如果手离相机有点远,手将占据深度图的一小部分。因此,即使对人类来说,不同的手指部位也只能依稀辨认。
•自相似性。对于人体姿态估计,不同身体部位的形状提供了判别线索。相比之下,五个手指有相似的外观,这就造成了区分它们的困难。
•遮挡。由于高自由度,五个手指可以很好地铰接。严重的遮挡会导致不同的手指部位被同一块点云所代表。在手与操纵对象或另一只手交互的情况下,手的某些部分通常是看不见的。准确的手姿势估计几乎是不可能的。
•数据不完整。大多数的手姿势估计方法都是使用一个深度相机。然而,单视点手的姿态估计实际上是一个不适定问题,因为在某些情况下,即使是人类也不能很好地估计。对于这些方法,假设从全手姿势空间到捕获的深度图的投影近似为一对一。多摄像机设置可以缓解这一挑战,但需要解决由不同摄像机引起的数据集成问题。此外,多摄像机设置限制了公众的部署。
•注释困难。在无标记运动捕捉中,深度图的注释是一个繁琐且昂贵的过程。目前的方法一般遵循综合分析的范式,即在计算机图形学的框架下,用可变形手模型绘制综合深度图。解决方案总是受到现实的综合差异的影响。
•手部分割。精确的手定位是手姿态估计的前提。在杂乱的场景中,手的分割是一个具有挑战性的问题。大多数方法只在干净的场景中处理单手姿势估计。有些方法利用真实的手关节位置来绕过手的分割,这在实际应用中显然是不可行的。如果手与操纵对象或另一只手交互,则手分割会变得更加困难。
•实时性能。人手具有快速运动能力,平移速度可达5米/秒,手腕旋转速度可达300米/秒[29]。当前的深度相机如Leap Motion已经达到了200hz的帧速率,但是对于深度相机通常支持的30fps估计速度的方法来说并不是一件容易的任务。
所有这些因素使得用手工估算模型来拟合观测的深度图非常具有挑战性。为了使研究人员能够专注于手姿势估计的特定方面,最近的方法在一些限制性假设下工作;例如,事先对手进行了分割,只涉及一只手[45,46]。我们明确了这些假设,以便读者更好地理解手姿势估计的现状。
其余内容组织如下:深度相机、手姿势估计方法和基准数据集将分别在第2节、第3节和第4节中详细讨论。第5节概述了结论和未来的发展方向。
2. 深度相机
尽管手姿势估计也可以通过带有标记的专用设备来解决,例如数据手套[47,48]、彩色手套[49,50]、电磁传感器[183]和光学运动捕捉系统[184],理想的解决方案是使用非侵入式设备。商用深度相机的出现极大地激发了研究人员对无标记手姿势估计的研究。因此,深度相机为深度估计手持式姿态估计奠定了硬件基础。
2.1. 常见的深度相机
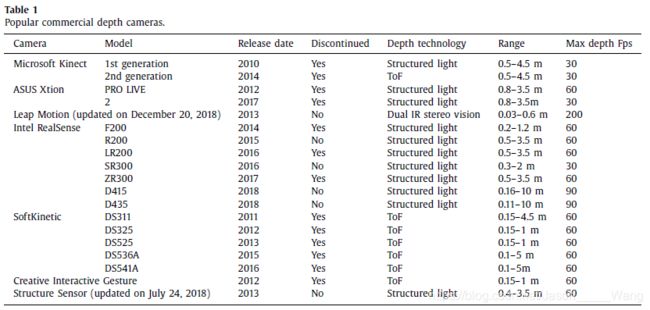
市场上大多数深度相机的传感原理是基于飞行时间(ToF)、结构光或其他立体视觉技术。表1列出了19种流行的深度相机
飞行时间相机通过发射脉冲或调制光信号,然后测量返回波前的时间差来探测深度。Foix等人[51]提供了ToF相机的概况,包括优势、局限性、校准方法、用途以及与其他传感器的组合。Hansard等人[52]介绍了ToF相机的原理、方法和应用。Davis等人[53]提出了一个由学术界和工业界背景不同的研究人员讨论的ToF成像总结。
在结构光技术中,一个已知的红外点图案被投影到一个场景上,同时被一个红外摄像机捕获。该图案由衍射光学元件和近红外激光二极管产生。立体三角剖分用于从投影中获取点的位置。Zanuttigh等人[54]详尽地介绍了结构光相机的工作原理。Salvi等人[55]介绍了结构光技术的最新进展。
与以主动方式计算距离的ToF相机和结构光相机不同,单个相机使用被动双目立体视觉从数字图像中提取3D信息,例如,STEROLABS ZED 2 K Stereo Camera and Point Grey BumbleBee。被动双目立体视觉相机的工作方式类似于人类的双目视觉。两个水平移动的校准摄像机用于获取场景中的两个不同视图。通过比较获得的两幅图像,可以以视差图的形式推断出相对深度信息,该视差图对相应图像点的水平坐标差进行编码。视差图中的值与相应像素位置处的场景深度成反比。由于对光照和纹理的敏感性,这种深度相机在手部姿态估计中并不流行。
很难说哪种类型的摄像机最适合于手的姿态估计,因为其性能还受环境因素和应用场景的影响。Sridhar等人[56]通过创造性的交互手势、Intel RealSense和Primesense Carmine验证了他们方法的有效性。在[57]中,Sridhar等人发布了一个带有创造性交互手势和Kinect v1的基准数据集。Melax等人[58]和Su-pancic等人[30]使用了华硕的Xtion和创造性互动手势。
**选择最合适的相机没有严格的通用规则。选择主要取决于问题的性质。**从表1可以看出,Intel RealSense系列适用于中远程应用,Leap Motion适用于短程应用,Structure Sensor适用于移动应用。微软Kinect、华硕Xtion、SoftKinetic和创意互动手势等相机已经停产。从长期维护和更新的角度来看,这些相机的吸引力不如其他深度相机。
2.2. 现有评价方法 Existing evaluation approaches
在医学领域,对深度相机性能的评估已经做了大量的工作。 Harkel等人[59]在一组单侧面瘫患者中测试了RealSense的准确性。House等人[60]评估了RealSense在椎体水平定位中的图像引导干预和应用。Yeung等人[61]评估了Kinect v1作为全身质量重心摆动测量的临床评估工具的性能。Noonan等人[62]用头部CT评估了Kinect v1对头部模型的运动跟踪。Ferche等人[63]利用Leap Motion和RealSense,通过在专用虚拟环境中提供增强反馈,帮助上肢残疾患者康复。
在其他领域可以找到许多评价方法。Cree等人[64]分析了用于距离成像的SoftKinetic的精度。Jakus等人[65]评估了跳跃运动的一致性和准确性。Fankhauser等人[66]分析了Kinect v2在阳光直射的阴天条件下用于移动机器人导航的深度数据质量。Carfagni等人[67]研究了RealSense用作3D扫描仪时的计量和关键特性。Yang等人[68]通过圆锥体模型获得了Kinect v2的精度分布。Lachat等人[69]提供了Kinect v2的评估和校准方法,以实现近距离3D建模的潜在用途。Corti等人[70]通过考虑测量条件和环境参数,提出了Kinect v2的计量特性。Breuer等人[71]对Kinect v2的测量噪声、精度和误差源进行了分析。
一些研究人员专注于不同深度相机的比较。Zennaro等人[72]比较了Kinect v1和Kinect v2的性能,以解释通过切换深度传感技术获得的结果。Gonzalez-Jorge等人[73]提出了使用基于五个球体和七个立方体的标准工件对Kinect v1和Kinect v2进行精度和精密度测试。Wasenmuller等人[74]研究了Kinect v1和Kinect v2在3D重建、猛击和视觉里程测量中的准确性和精确度。Boehm等人[75]研究了结构光相机的重复性和精确度。Langmann[76]提出了一个深度相机评估,包括Kinect v1、ZESS MultiCam、PMDTec 3k-S、SoftKinetic和PMDTec CamCube 41k。
深度相机和其他设备之间的比较也可以找到。Lima等人[77]使用RealSense作为眼睛注视跟踪器来估计用户的注视位置,并将其与一种特殊设备Tobii EyeX进行了比较。 Seixas等人[78]设计了一个实验来研究二维定点任务中跳跃运动的表现,并将跳跃运动与鼠标和触摸板进行了比较。实验结果表明,跳跃运动效果不佳。
要获得深度相机的精度,必须知道作为参考的ground-truth结果。现有方法中引入了各种高精度测量设备,如Vicon运动捕捉系统[61]、AGPtek手持数字激光点测距仪[68]、卷尺[66]、Polaris光学跟踪器[62]、FARO Focus地面激光扫描仪[69]、坐标测量机[67,73],临床3dMD系统[59],NextEngine扫描仪[72],Qualifys运动捕获系统[65,79]。
现有方法的重点是评估摄像机测量固定空间位置的性能。这种评估本质上是静态特性的特征。相比之下,动态跟踪精度的研究很少。 Guna等人[79]分析了跳跃运动的精度和可靠性,以及它对动态跟踪的适用性。在其评估过程中,创建了一个由两个跟踪对象组成的移动V形工具,该工具保持了两个目标之间的恒定距离,以模拟两个伸出的手指。实验设计不灵活,既不能改变两个跟踪对象之间的距离,也不能控制运动速度。
2.2. 现有评价方法 Existing evaluation approaches
考虑到深度相机的静态特性已经得到了广泛的研究,我们只关注动态跟踪精度。如果按照传统评估方法的思路,首先要引入高精度的测量装置,以获得ground-truth 结果。这个装置基本上测量一个绝对位置。在传统的测量方法中,由于使用不同的坐标系,在计算测量误差之前需要进行标定。因为我们不打算使用解剖地标,ground-truth位置变得不可测量。因此,我们求助于相对可测量的运动轨迹。图3直观地说明了我们的整体解决方案。我们的解决方案最大的优点是,繁琐的解剖地标和坐标校准是不必要的。
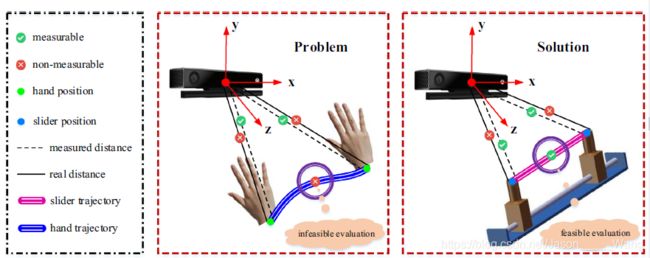
图3:直观说明了评估深度相机动态跟踪精度的整体解决方案。
我们设计了一个无标记装置来实现我们的解决方案,如图4所示。整机由计算机、AMD4030控制器、FMDD50D40NOM驱动器、LRS-350-24直流电源、ROKO SN04-N限位开关、FLS40L数控直线运动导轨组成。除计算机和限位开关外,所有机械零件的制造商均为福宇科技有限公司[80]。直线运动导轨的精度为0.05mm,工作范围为300mm,最大允许速度150mm/s。该装置的工作原理非常简单:滑块的直线运动由螺杆旋转驱动,滑块的速度和位移由计算机编程控制。
评估用的照相机是用螺丝固定在一个照相的三叉戟上的。为了方便地调整位置和方向,控制器、驱动器、直流电源、限位开关和直线运动导轨牢固地固定在安装在钢支架上的木板上。滑块加速时,展开会导致轻微振动(1–2 mm)。然而,仪器引起的测量误差在可接受的范围内,因为即使是人类也几乎不可能区分具有如此微小差异的双手姿势。与静态测量评估不同,该仪器的精度已经足够可靠,可以评估手姿态估计的动态跟踪精度。
从理论上讲,最现实的评估手姿态估计跟踪精度的方法必须满足这样一个要求:被测者应尽可能多地执行不同的手姿态,同时尽可能地改变运动速度和轨迹。根据变量控制原理,应排除不相关的软件因素。为此,我们需要一种理想的手姿态估计算法来跟踪手运动过程中手关节的位置。为了研究影响跟踪精度的因素,研究者必须严格控制手部的运动速度和运动轨迹。事实上,这些要求都不能满足。首先,理想的手姿态估计算法受到深度相机跟踪精度的影响,但是为了只评估深度相机的跟踪精度,我们反过来依赖于理想的手姿态估计算法,导致了鸡和蛋的两难选择。第二,严格控制手部动作显然超出了人的能力。
我们知道,手关节摄像机跟踪的实质是跟踪一组具有固定约束的运动点,而实际的跟踪精度与点的个数、源和拓扑结构无关。换句话说,手关节状态是手姿势估计算法(软件因素)的关注点,而这与相机评估(硬件因素)无关。因此,用手进行现实的评价是不可行的,也是不必要的。为了使评估独立于软件因素的影响,白瓷棒的顶端被用来模拟单个手关节,如图4所示。白瓷棒牢固地安装在滑块上。其直径和长度分别为1.0cm和8.5cm。通过深度距离阈值法检测感兴趣点,即白瓷棒的顶端。详细的实验安排、评估标准和评估结果将在第4.4节中讨论。
3.方法 Methods
**根据Erol等人[29]的分类法,手姿势估计方法根据生成方法和根据观察结果进行测试的方式 可分为模型驱动方法(或生成方法)和数据驱动方法(或基于外观的方法和判别方法)。**尽管分类法已被广泛接受[1,34,44,45],但它不包括结合了模型驱动方法和数据驱动方法特点的方法类。因此,一些研究人员[5,42,81–83]在原有的分类系统中添加了一类混合方法。为了完整性,我们还采用了这个更合理的分类系统。
存在一些并未广为流传的分类法。Oikonomidis et al.[84,85]和Poudel et al.[86]将手姿势估计方法分类为不相交证据方法和联合证据方法,根据关节手的独立刚性部分的部分证据如何有助于最终解决方案。不相交的证据方法考虑的是具有隔离优先权的单个零件,而联合证据方法考虑的是在一个完整的关节手假设的背景下的所有零件。Liang等人[87]认为,手部姿态估计的解决方案包括模板匹配或基于模型的全局描述符拟合,以及弱姿态估计器获得的多个估计的集成。Otberdout等人[2]将手姿势估计方法分为基于模型的方法、基于浅层学习的方法和基于深度学习的方法。
请注意,我们调查采用的分类法并不是一个非常严格的标准;例如,Supancic等人[30]将[33]中提出的方法归类为混合方法,但Taylor等人[5]将其归类为数据驱动方法。在我们的调查中,我们优先考虑现有的分类结果。在本节之后,模型驱动方法、数据驱动方法和混合方法将分别在第3.1-3.3节中讨论。第3.4节概述了商用手姿势估计系统。第3.5节比较了三类手位估计方法的特点。第3.6节具体分析了所有方法。
3.1. 模型驱动方法 Model-driven methods
模型驱动的方法生成假想的手姿势,并将其与从深度相机检索到的观察结果进行比较。比较是通过制定一个优化问题来实现的,该问题的目标函数度量实际观测值与生成手模型期望观测值之间的差异。从理论上讲,所采用的求解技术应该能够使目标函数在任意点处最小化。参数空间的高维性意味着要彻底搜索所有可能的手姿势是不可行的。
模型驱动方法采用局部搜索和初始化相结合的次优解,因此手位估计结果对初始化非常敏感。通常,前一帧的解被用作下一帧的初始化,这可能由于累积的估计误差而导致姿态漂移。特别是在手部快速运动的情况下,模型驱动的方法很难从跟踪失败中恢复。通过重新初始化[5,84,88,90,91,98,99]可以缓解跟踪丢失问题。
从模型驱动方法的实现机制可以看出它们的两个显著特点。他们的第一个特点是,他们依赖于一个明确的手模型,考虑解剖和运动学约束。引入手模型来生成假想的手姿势。它们的第二个特征是需要一个手姿势来初始化目标函数。在模型驱动方法中,标注的数据用于学习手模型的几何和动力学先验知识或构造目标函数,而不是训练判别分类器或回归模型。这两个显著特征也是判断手位估计方法是否为模型驱动方法的主要依据。
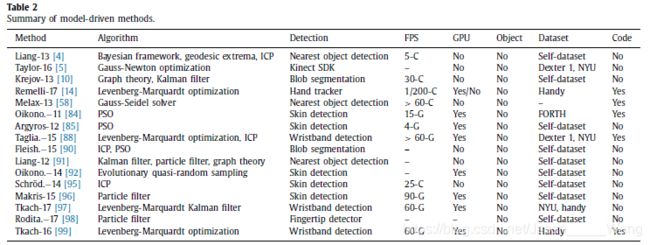
表2简要总结了16种最先进的模型驱动方法,这些方法由作者姓名和出版年份组成的缩写命名。“算法”列包含用于建模或优化的关键算法。对于紧致性,粒子群优化、随机森林和迭代最近点三个技术术语分别缩写为PSO、RF和ICP。检测列指定如何实现手部检测。FPS列给出了基于GPU(G)或CPU(C)的方法每秒可以处理的帧数。GPU列指定该方法是否依赖于GPU。object列表示在手与操纵对象交互的情况下该方法是否可以工作。“数据集”列将为评估选择的基准数据集命名。这些数据集的细节将在下一节中给出。代码列表示源代码是否公开可用。如果表格列中的数据项没有在纸上给出,则相应的单元格将填充连字符。
我们用这七个指标来描述每种方法的第一个原因是从统计信息中得出一些有意义的结论。第二个原因是为研究者提供参考,使他们能够选择合适的比较方法和评价数据集。第三个原因是我们的目的是以直观的形式总结手部姿态估计的研究现状。
3.2. 数据驱动方法 Data-driven methods
数据驱动方法学习从观察到的一组离散的带注释的手姿势的直接映射。与模型驱动方法不同的是,数据驱动方法使用带注释的手姿势来训练判别分类器或回归模型,其描述能力取决于所使用特征的不变性、待估计姿势的数量和多样性以及导出映射的方式。典型的数据驱动方法试图从单个深度图估计手的姿势[18,87110114129135163165],因此对姿势漂移具有鲁棒性。这样的方法不需要初始化,并且对先前不准确的估计结果和手从相机视图消失的情况具有鲁棒性。
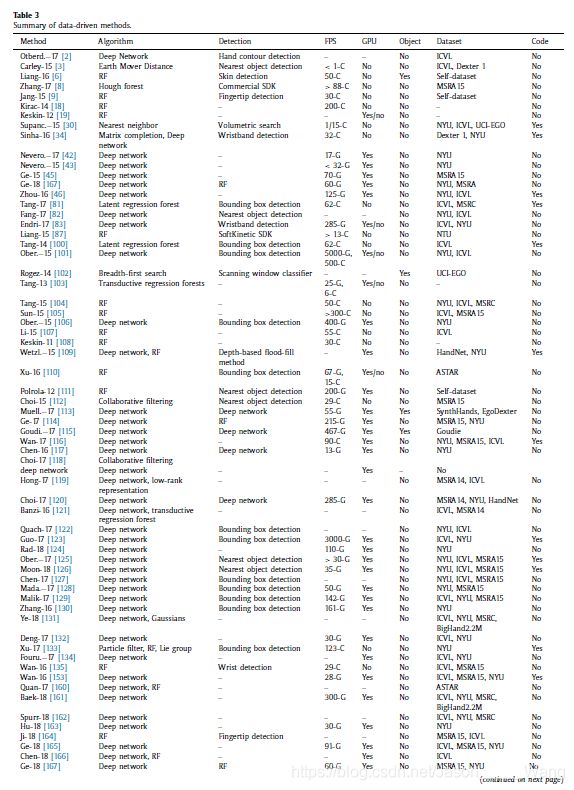
**数据驱动方法的第一个显著特点是没有引入显式的手模型。**相反,测试姿势通过分类或回归与带注释的手姿势相关联。对于数据驱动的方法,训练是一个必要的步骤,通常不需要初始化手的姿势。它们的第二个显著特征是数据驱动方法试图使用足够多的带注释的手姿势来密集地覆盖整个手姿势空间。因此,数据驱动方法的准确性受到带注释的手姿势的强烈影响,而不是受到运行时用于该问题的计算成本的影响。这两个特征也是判断手位估计方法是否属于数据驱动方法范畴的主要依据。表3列出了67种最先进的数据驱动方法。

3.3. 混合方法 Hybrid methods
模型驱动方法和数据驱动方法在许多方面是互补的,这将在第3.5节中具体讨论。混合方法试图通过结合这两种方法来解决手姿势估计问题,以期继承它们的优点。 Poier等人[89]指出有两种杂交方法。第一类方法试图用模型驱动的方法来求解,而数据驱动的方法只在失败的情况下才被考虑。第二种方法通过数据驱动的方法获得初始姿态,然后通过模型驱动的方法验证和/或局部优化结果。最新的混合方法属于第二种类型[33,35,44,57,89136–139142143]。实际上,积分方法并不局限于这两种类型,例如[140141]中提出的混合方法只是例外。混合特征是判断手位估计方法是否属于混合方法的主要依据。
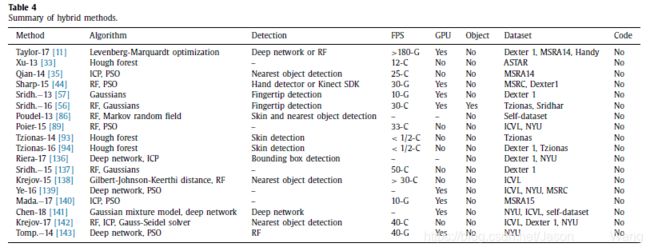
开发一个混合方法不是一个简单而直接的任务。首先,一些固有的困难仍然存在,例如,手的检测,解剖限制,和五个手指之间的相似性。第二,结合模型驱动方法和数据驱动方法可能会引入新的耦合问题,例如计算成本。这就是为什么混合方法不一定比模型驱动方法和数据驱动方法更有效。表4列出了18种最先进的混合方法。
3.4. 商业系统 Commercial systems
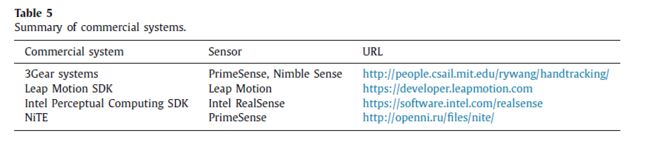
除了学术方法外,一些研究者还将商用手位估计系统作为比较基线。Xu等人[33]和Sharp等人[44]将他们的方法与3Gear系统进行了比较[50]。Liang等人[6]、Mueller等人[113]、Xu等人[110]和Sridhar等人[137]将他们的方法与Leap Motion SDK进行了比较。Tagliasacchi等人[88]将他们的方法与Intel Perceptive Computing SDK进行了比较。Ro-gez等人[102]将他们的方法与NiTE进行了比较。与用开放算法发布的aca-demic方法不同,商业系统的内部工作机制是未知的,因此我们只提供url和传感器,如表5所示。
3.5. 总体比较 Overall comparison
通过对各种手位估计方法的总结,可以看出数据驱动方法在数量上占主导地位。最可能的原因是,数据驱动方法避免构造复杂的目标函数,该目标函数需要考虑手的各种约束,例如外观、拓扑、变形和运动学。与模型驱动方法和混合方法相比,数据驱动方法更容易保证运行时性能。数据驱动方法缺乏模型驱动方法和混合方法的准确性,但不存在姿态漂移问题。接下来,我们从不同的角度进一步比较这三类方法。
3.5.1. 时间相干性
对于基于序列的手姿态估计,时间相干性是一把双刃剑。从积极的一面来看,考虑手姿势随时间的连续性可以防止相邻帧之间的突然变化。毕竟,在理论上,无论五指移动多快,只要帧速率足够高,位置变化都是连续的。时间相干性通过充分利用相邻帧来丰富建模数据,而不是使用单个当前帧。另一方面,引入时间相干性使得方法容易产生姿态漂移,需要处理手从相机视角消失的情况。
一些模型驱动方法[4,5,10,88,96,97,99]利用时间先验来传播姿态信息。Taylor等人[5]通过在定义的能量函数中添加时间先验项,鼓励了帧间手姿势的时间一致性,这不仅平滑了跟踪器的输出,而且整合了前一帧的观察结果。Makris等人[96]将时间维度编码为动态贝叶斯网络。Tkach等人[97]在Levenberg–Marquardt卡尔曼滤波公式中,在估计渐变形状参数之前应用了一个强大的时间序列。Tkach等人[99]提出的方法要求深度相机的帧速率应大于60Hz。
典型的数据驱动方法试图从单深度图中估计手的姿势[18,45,87108–110114120129135163165],这意味着它们完全放弃了时间一致性,但考虑时间一致性的数据驱动方法也不例外[34122133]。Sinha等人[34]训练CNN输出低维激活特征。利用矩阵完备估计未知姿态参数。该矩阵由从预先计算的数据库中检索到的时空激活特征构成。Xu等人[133]提出的方法遵循粒子滤波范式,将时间信息纳入三时间步概率推理过程。Quach等人[122]使用递归神经网络对深度序列的帧顺序进行建模。
模拟时间一致性的混合方法也存在。Sharp等人[44]通过一个黄金目标函数描述的模型拟合器和一个随机优化算法来考虑时间一致性。Poudel等人[86]考虑了树结构马尔可夫模型的时间信息。文献[138142]中提出的方法利用刚体动力学模拟来模拟时间相干性。文献[140]中提出的方法首先从单个帧估计手的姿势,然后利用时间数据对结果进行细化。一些混合方法允许从单个深度图估计手的姿势,例如,Xu等人[33]和Poier等人[89]提出的方法。
3.5.2. 应用程序和运行时表现
模型驱动的方法可以很容易地适应不同的场景,因为主要需求是改变手模型的外观和运动学。它们非常适合于需要自由操作的手准确估计姿势的问题。估计手姿势的准确性可能受益于运行时较大的计算预算。人们可以在精确度和速度之间进行权衡。
对于数据驱动的方法,由于可能的手姿势的数量随着手关节数量的增加呈指数增长,因此泛化能力取决于注释的手姿势。这使得数据驱动方法适用于需要估计少量已知姿态的问题。判别分类器或回归模型离线训练,从而使数据驱动方法以较低的计算成本执行。
与模型驱动方法类似,混合方法还需要求解为比较手模型生成的实际手姿势和假想手姿势而定义的能量函数,因此通常它们的计算效率低于数据驱动方法。从表4给出的结果可以看出,除了[11]之外,虽然有些方法引入了GPU加速,但混合方法的运行时FPS小于50。相比之下,表3中列出的大多数数据驱动方法的运行时FPS大于30。文[101]中提出的数据驱动方法的运行时FPS甚至达到了50。
3.5.3. 解剖和运动学约束
如何考虑解剖和运动学约束是一个关键问题。如果解剖和运动学约束没有得到很好的建模,估计的手姿势可能无效,例如,不可信的关节或手指长度。模型驱动方法和混合方法引入了一个显式的手模型,因此从保持手姿势结构的有效性的角度来看,它们比数据驱动方法具有优势。
在模型驱动方法和混合方法中,有多种方法可以用来构造一个显式的手模型。Oikonomidis等人[84]使用了两种几何原语,包括球体和圆柱体,来构建手模型。Tagliasacchi等人[88]使用更简单的球形圆柱作为几何原语。Tkach等人[99]扩展了[88]的工作,使用了精确的球体网格表示。夏普等人[44]用三角形和顶点的详细网格表示手模型。钱等人[35]用许多球体来表示手模型。鉴于[35,88]中的手表示法使得能量函数不连续,Sridhar等人[137]和Chen等人[141]使用高斯函数的混合来表示手的形状。Taylor等人[5]通过平滑曲面定义手模型,允许Gauss-Newton优化在手姿势空间上联合搜索。树结构马尔可夫模型[86]和刚体模拟[142]已被用于研究解剖和运动学约束。
对于数据驱动的方法,估计的手姿势的质量在很大程度上依赖于标注的手姿势。如果测试手的姿势与注释的非常不同,那么产生解剖学上无效的手姿势的可能性将相当高。数据驱动方法以一种软的方式执行结构约束。Zhou等人[46]提出了一种深度网络,其中采用了基于正运动学的层来增强几何测量的有效性。Malik等人[129]提出的方法直接估计手尺度参数。Oberweger等人[101,125]和Otberdout等人[2]通过在深层网络中插入PCA层,捕捉到了不同手关节的相关性。在[123,127,128,186]中提出的方法通过区域划分和集成来模拟手部结构。Roditakis等人[98]通过在可到达的距离空间中采样来实施动力学约束。与基于RF的整体回归相比,基于RF的层次回归和基于RF的级联回归[18105135164]更好地遵循了手的树结构拓扑。
3.6. 具体分析 Specific analysis
为了更全面地介绍现有的手姿势估计方法,我们对表2-4中前面提到的七项进行了补充说明。这样的具体分析不仅体现了手位估计研究的独特视角,而且可以更好地揭示手位估计研究中的一些不足和有待解决的问题。
3.6.1. 流行算法
从表中的算法列,我们可以得出两个结论。首先,在数据驱动方法和混合方法中,应用最广泛的分类和回归算法是深度网络和RFs。其次,在模型驱动方法和混合方法中,最广泛使用的能量函数算法和优化算法分别是ICP算法和PSO算法。
深度神经网络
鉴于计算机视觉的发展趋势,将深度学习应用于手部姿态估计是很自然的。大量的实验表明,深网在手部姿态估计领域有很好的应用前景。众所周知,深度网络是数据饥渴的,但手动标注具有密集三维手关节的大型数据集并不是一个实际的选择。因此,大多数基于深度网络的方法都使用具有固有ground-truth的合成数据。
过去五年中提出的最先进的深度学习技术已成功应用于手姿势估计,如残差网络[123125127186]、变分自动编码网络[116162168]和生成性对抗网络[116161168]。常用的优化策略,例如数据增强[123125]、多视图融合[114,45165167]和多尺度融合[101143163],已经与深度网络相结合。大多数基于深度网络的方法使用2D卷积核来提取深度特征,但由于2.5D的特性,深度贴图可以转换为体积表示,并输入3D CNN以直接生成手姿势[114126132165]。
RF算法
Shotton等人[40]提出了一种基于RF的经典人体姿态估计方法,产生了一组后续的手部姿态估计方法。Tang等人[81]给出的理由可以解释为什么射频被广泛使用。首先,RF固有地支持多个类,这是手姿势估计的固有特性。第二,射频在许多视觉任务中被证明是非常有效的。第三,RF方法已经成功地应用于人体姿态估计中,类似于手的姿态估计。
RF从两个方面解决了手的姿态估计问题:回归林和分类林。回归林与分类林在两个方面不同。首先,设计训练质量函数,使子节点空间方差最小。其次,叶模型预测连续输出值,如手部位置。Kirac等人[18]和Poudel等人[86]比较了用于手姿势估计的回归林和分类林的性能。
PSO算法
粒子群优化算法是一种随机进化算法,它通过在若干代(迭代)中进化若干粒子(解)来进行优化。它非常适合于求解非凸或/或非光滑目标函数;例如,Poier等人[89]提出的方法正是基于这种考虑。PSO的另一个吸引人的特性是它的并行实现机制,使得PSO能够被GPU加速[84,85]。Levenberg-Marquardt和Gauss-Newton等优化算法只能处理光滑的能量函数。
ICP算法
ICP是找到将点云与网格模型对齐的刚性变换的最常用方法。Tagliasacchi等人[88]提出了一种正则化的关节式ICP优化方法,该方法将数据拟合与运动学和时间先验以及数据驱动先验进行了仔细的平衡。Fleishman等人[90]在逆运动学框架下提出了一种铰接ICP算法。Qian等人[35]发现,以前基于ICP的方法和基于PSO的方法在本质上是互补的:ICP很快达到局部最优,而PSO更有效地探索参数空间,但存在过早收敛的问题。因此,他们提出了一种混合优化方法来综合优点和克服缺点。
3.6.2. 手部检测
大多数方法都假设手位于干净的场景中,并且是面向摄影机的最前面的对象。在这种情况下,可以通过手轮廓检测、最近目标检测、体积搜索、包围盒检测等方法来定位手。这种手检测方法的基本工作原理是深度距离阈值法。
皮肤检测方法通过检测RGB视频中的肤色对象来定位手部,然后将定位结果应用于深度图;例如,Oikonomidis等人[85]采用了[144]中提出的皮肤检测器。即使场景中没有其他肤色对象,检测到的皮肤遮罩也不总是可靠的;即,背景像素仍然可能被误分类为手部区域。Liang等人[6]尝试使用RANSAC算法改进肤色检测结果。皮肤检测的可行性取决于RGB视频和深度相机的深度序列几乎是同步的。腕带检测方法的实现思想与皮肤检测方法相同。有些方法使用商业人体姿势跟踪器(如Kinect-SDK)估计手的粗略位置。有些方法忽略了手的检测,并假设手已经被分割。
一些研究人员专门研究手部检测。他们解决方案的关键算法是射频或深度网络。Choi等人[118]和Taylor等人[11]比较了射频和深度网络用于手部检测的性能。并不是所有的方法都遵循级联检测到估计模式;例如,Chen等人[117]在CNN框架下集成了手检测和手姿势估计。
3.6.3. FPS和GPU
最新的方法可以满足实时性要求(通常FPS>10)。一些作者声称他们的方法是实时工作的,但是他们没有提供具体的FPS。有一些方法只关注精度,而运行时性能没有得到太多重视:既没有给出FPS,也没有给出对GPU的依赖。一般来说,使用深度网络或PSO优化的方法往往依赖于GPU加速。对于以射频为主要建模解决方案的方法,GPU加速通常是不必要的。
3.6.4. 手-物交互
**手-物交互作用下的手姿态估计研究很少。最大的挑战来自于非常严重的遮挡。**从表2,我们可以看到16种模型驱动方法中没有一种能够处理手-对象交互。最可能的原因是对象信息在生成手模型中很难编码。在表4列出的18种混合方法中,只有1种方法可以处理手-物交互。即使对于表3中列出的67种数据驱动方法,也只有5种方法可以处理手-对象交互。
**对于具有手-物交互的手姿态估计,通常首先将手从手-物交互中分离出来,这样就可以将问题转化为普通的手姿态估计。**Goudie等人[115]和Sridhar等人[56]沿着这些路线开发了他们的方法,手分别由深网络和RF进行分割。Choi等人[118]试图从物体抓取分类的角度估计手的姿势。Rogez等人[102]和Mueller等人[113]从一个移动的、自我中心的角度研究了手-物体交互的手姿势估计。
当操纵对象是另一只手时,将具有手-物交互的手姿态估计退化为双手姿态估计。直到最近,大多数方法都只限于一只孤立的手。只有少数方法可以应对双手互动过程中出现的挑战,例如[10,11,58,85,92,93]。如果两手在摄像机的视场中是明显分开的,就足以解决单手姿态估计的两个实例。然而,现有的实验结果表明,在存在强双手交互的情况下,单手姿态估计的直接扩展导致了更低的精度[44,85]。
在追求现实场景的过程中,研究工作应该转向一般的双手和手-物交互,并且这种研究确实存在,例如Tzionas等人[94]和Liang等人[6]提出的方法能够处理双手和手-物交互。Tzionas等人[94]提出的方法甚至可以适用于一个单目RGB-D相机或多个同步RGB相机。
3.6.5. 基准数据集和代码
大多数方法至少在一个基准数据集上进行评估。有些方法是在作者自己的数据集上评估的,这些数据集并不公开,但它们大多是2014年之前提出的方法**。2015年后提出的大多数方法采用标准数据集和评估标准。最常用的五个数据集是NYU、ICVL、MSRA15、Dexter 1和MSRC。**一些搜索者将源代码用于实现他们的方法。他们的论文中提供了URL,或者可以从作者的主页或GitHub下载源代码。
4.数据集
基准数据集对于手姿势估计领域中不同方法的比较评估至关重要。它们可以由计算机图形学合成,也可以由深度相机获取。与人体姿态估计一样,数据集标注是手部姿态估计首先要解决的问题。在本节中,我们首先介绍现有数据集的创建和注释,然后介绍评估度量,最后总结现有的基准数据集。
4.1. 创建和注释
真实的训练数据长期以来一直是监督学习的黄金标准,但对于手姿势估计,手动注释大型数据集超出了人类的能力。因此,研究人员开发了各种方法来解决这个问题。根据硬件和软件的要求,我们将这些方法大致分为以下六类。
4.1.1. 合成模型
由可变形三维手模型渲染的合成深度贴图绕过了手动注释过程。自动获得精确的ground-truth注释。最重要的是从不同的方向和广泛的手姿势定义采样分布,因为引入手运动约束的先验知识不是一件容易的事。在[86,113]中创建的合成数据集有一个缺点,即它们不能准确地解释手的自然运动、遮挡和噪声特性。流行的三维手部建模工具,如开源Libhand[145]、商业Poser[146]和Unity[147]已应用于合成方法分析[33,42,43,46102,113,136]。
4.1.2. 数据采集手套
Xu等人[33110]借助ShapeHand数据手套对深度图进行了注释[148]。Liang等人[87]使用CyberGlove II数据手套[149]捕捉各种手部运动的手关节参数。为了避免手动注释,Carley等人[3]同步了一个深度相机和一个CyberGlove III数据手套[149],并对采集的手姿势进行了校准并映射到运动学模型。尽管数据手套可以直接获得准确的注释,但这种方法需要用户特定的校准,并且会扭曲深度图中观察到的自然手关节。
4.1.3. 磁性传感器
**Wetzler等人开发了一种新的管道,使用Ascension-TrakStar磁传感器快速绘制深度图。但是,该方法仅注释了五个指尖位置。**采用与[109]类似的方法,Yuan等人[151]通过六个Ascension-TrakStar磁传感器引入了一个大型数据集,并使用逆运动学自动获得注释。像阿森松星这样的现代磁传感器对金属干扰和有色金属的阻碍都有很强的抵抗力。他们提供亚毫米和亚度精度与高速定位和定位相对固定基地站。这种标注方法需要对不同的坐标系进行标定,存在同步误差和原始手姿态失真的缺点。
4.1.4. 多摄像机
Tompson等人[143]通过拟合线性混合蒙皮(LBS)手模型自动注释深度图。为了减轻自遮挡的影响,他们使用了三个摄像头,从前面将用户周围的视点分开大约45°。初始注释结果有时需要手动调整以更好地拟合深度图。手动调整的深度图之间的深度图拟合可能较差。Srid-har等人[57]使用两个深度相机手动注释深度图。文献[57,143]中提出的注释方法既费时又费力。
**夏普等人[44]同时从深度相机和标准RGB相机中捕捉到了绘制的手的序列。在校准摄像机后,使用自动颜色分割算法在序列中给出像素级的ground-truth注释。当颜色分割不正确时,手动校正注释结果。**除了校准和同步外,多摄像机标记方法的另一个缺点是部署不方便。
4.1.5. 单摄像机
Oberweger等人[152]提出了一种半自动注释方法。用户被要求只提供参考帧中可见关节的2D重投影估计值。通过优化损失函数,自动选择这些参考系以最小化标记工作。利用空间、时间和外观约束来恢复整个序列中的完整手姿势。
Rogez等人[102]开发了一种半自动注释工具。首先在深度图中手动标记几个2D关节,并用于在训练集中选择最接近的合成样本。通过将手工标注的结果与所选的三维样本相结合,生成完整的手部姿势,然后进行手工细化。这些步骤导致了一个新范例的选择,以及一个新姿势的创建。接着进行迭代过程,直到获得满意的注释。Tang等人[100]、Sun等人[105]和Qian等人[35]采用了“跟踪+细化”的方法。采用优化算法得到初步注释。然后手动更正初步注释,直到发现它是正确的。
4.1.6. 标记器运动捕捉设备
Schröder等人[95]利用Vicon运动跟踪系统捕捉手部运动,在手上放置16个反光标记以获取关节位置。基于标记的方法释放了同步和校准的空间,但是对于用户来说,它不够自然和沉浸感。Aristidou等人[184]提出了一种通过八个摄像头的PhaseSpace Pulsex2Motion捕捉系统重建手姿势的有效方法,该系统在每个手指上附着一个标记,并在手掌上的战略位置放置三个以上的标记,以帮助识别手的根部和方向。
4.1.7. 小结
自动完成了合成深度图注记的全过程。对于实际深度图,根据人工干预的程度,注释方法可分为手动注释方法(如[57])、半自动注释方法(如[102])和自动注释方法(如[110])。 Supancic等人[30]指出,手姿势数据集的真实性和多样性与模型架构的选择同样重要;因此,如何有效地获取高质量的数据集仍然需要仔细研究。
4.2. 评估指标
给定一个基准数据集,定义一个合理的评价指标至关重要。在当前的度量标准中,有些是非常流行的,而另一些则没有得到广泛的应用。在应用场景方面,有的是纯手姿态估计,有的是面向手-物交互的手姿态估计。
4.2.1. 流行的评估指标
**有两种流行的评估指标。第一个是预测的关节位置和ground truth之间的平均欧氏距离。第二个是测试帧中所有预测的关节位置都低于距ground truth的最大欧氏距离的部分。**对于基于关节角度的方法,如[46,112],关节位置的欧几里德距离应替换为关节角度。
第二个度量最初用于人体姿势估计[154]。一般来说,这被认为是更具挑战性的,因为一个单一的脱臼关节可以恶化整个手姿势。Supancic等人[30]研究了第二个度量,并提出了定性的可视化。他们得出的结论是,20毫米的最大误差接近人类对近距手的精确度极限,50毫米的最大误差与大致正确的手姿势一致,100毫米以内的误差与正确的检测一致。
4.2.2. 其他评估指标
Sridhar等人[56]介绍了一种新的手-物体交互的手姿势估计数据集。对于数据集中的每一帧,他们标注了8个不同的地标(5个指尖位置和3个物体角)。如果某个位置不可见,则相应的地标被设置为无效,并且在误差测量中不被考虑。对于物体来说,这三个地标沿着长方体的两个主轴线跨越一个坐标系,这两个主轴线相对于对称轴唯一地定义了长方体。Sridhar等人定义了一个评估指标来将估计结果与地面真值注释进行比较。Goudie等人[115]也引入了一个公共数据集,用于手-物体交互的手姿势估计,但他们仍然采用了上述两种流行的评估指标。
Sharp等人[44]和Taylor等人[5]采用了一种基于将像素分类为手的几个部分之一的度量。该度量统计平均或最大像素分类错误率低于某个阈值的帧的百分比。与这两个流行的指标相比,这种方法评估了系统全面准确地解释每个像素的能力。严格地说,它适合于手解析,因此在我们的调查中,在[5,44]中使用的FingerPaint数据集不被视为手姿势估计数据集。 I.Oikonomidis等人[84]采用了一种度量方法,在该方法中,测量了地面真值中相应的指骨端点与估计的手模型之间的距离。序列所有帧上所有距离的平均值构成最终的结果误差。
4.3. 基准数据集
在现有总结工作[30,32151]和近期进展的基础上,我们总结了22个基准数据集,如表6所示。主题列包含参与收集数据集的主题数。frame列包含总帧数。注释列包含an-notation方法。设备列指定用于收集数据集的摄像机和辅助设备。“对象”列表示是否发布数据集以进行手-对象交互的手姿势估计。“关节”列提供带注释的手关节的数量。
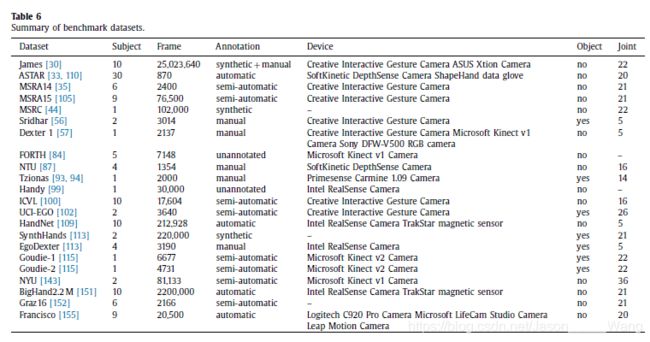
在表6中,MSRC数据集也称为合成或MSHD数据集,ASTAR数据集也称为A*STAR数据集,Dexter 1数据集也称为Dexter数据集。Qian等人在2014年[35]和2015年[105]发表了两个MSRA数据集。为了避免混淆,我们将年份添加到原始数据集名称中。有些数据集没有名称,包括Sridhar[56]、Tzionas[93,94]、Goudie-1[115]、Goudie-2[115]和Francisco[155]。我们使用作者的名字来表示这些数据集。
我们认为,如果一个数据集可以被视为一个基准数据集,那么至少应该满足两个要求。第一个要求是必须公开。Chen等人[141]、Banzi等人[121]和Taylor等人[11]收集了他们自己的数据集,但他们的论文中没有提供公共URL。这些数据集不包括在表6中。第二个要求是,它必须专门公布的手姿势估计。Keskin等人[19]和Kirac等人[18]在美国手语(ASL)数据集上测试了他们的手姿势估计方法的运行时性能。Choi等人[118]在一个物体抓取数据集上评估了他们的手姿势估计方法。这些数据集不包括在表6中。
4.4. 评价实验
现有的手位估计研究主要集中在模型改进和数据集的增强效应上。深度相机对跟踪精度的影响从来没有被仔细研究过。假设在基准数据集上,手姿态估计方法得到的估计结果的平均欧氏距离误差为3mm,但即使在理想条件下,深度相机的跟踪精度也为4mm。在这种情况下,报告的估计结果的显著性将不可避免地降低;例如,实现平均欧氏距离误差为3mm的方法不一定比实现平均欧氏距离误差为2mm的方法工作得更好,因为没有考虑深度相机的系统误差。我们试图探索当前深度相机是否已经成为限制手姿势估计进展的硬件瓶颈这一问题的答案。
深度相机的性能同时受到光照、距离、材料、温度等因素的影响,综合考虑这些因素,评价过程将变得极其复杂。因为我们关注的是动态特性,所以我们只研究最相关的因素:位置、运动方向和运动速度的影响。Kinect v2和Intel RealSense SR300分别作为ToF和结构光相机的两个代表性示例。所有实验均在室内进行。扩展图4所示的装置以考虑其他因素或评估其他照相机是直接和明显的,并且不需要进一步的解释。
4.4.1. 实验安排
对于Kinect v2的评估实验,我们使用Kinect For Windows SDK 2.0读取深度数据。帧大小和帧速率分别为424×512和30fps。对于intelrealsensessr300的评测实验,我们使用intelrealsensesdk读取深度数据。帧大小和帧速率分别为480×640和30fps。
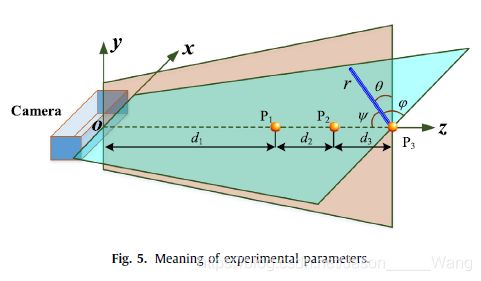
我们定义了一些参数来描述实验安排,如图5所示。我们假设在所有的实验中摄像机都是固定的。根据两个摄像机的最佳工作距离,我们考虑了感兴趣点的三个起始运动位置。有必要再次提醒读者,关注点是白瓷棒的顶端,白瓷棒牢固地安装在图4所示的滑块上。三个起始运动位置位于z轴上,表示为p1、p2和p3,其相对位移由d1、d2和d3确定。感兴趣点的运动位移用r表示,其大小在所有实验中都是固定的。ν、θ和ψ表示r和三个正交轴之间的角度。对于每个起始运动位置,我们考虑由ν、θ和ψ确定的七个运动方向。对于每个起始运动位置和每个运动方向,我们考虑用v表示的十个速度。表7列出了所有这些参数的值。

每个实验都需要一组预先给定的起始运动位置、运动方向和运动速度。通过手动调整数控直线运动导轨来确定起始运动位置和运动方向,运动速度由计算机编程控制。由于对称性,所有的实验都是在一个倍频器中进行的。在测试点的运动过程中,记录深度图,然后用于后续的实验分析。
4.4.2. 评价标准
我们提出了一个线性轨迹测量误差(LTME)来评估跟踪精度。假设S=[s1,s2,…,sn](i=1,2,…,n)是在关注点的运动期间由相机采样的位置的连续集合,并且S i=[xi,yi,zi]是第i个采样位置。利用最小二乘法(OLS)估计生成拟合线。我们假设hi是sii拟合残差的绝对值。LTME定义为{hi}的平均值。对于每组的起始运动位置、运动方向和运动速度,进行10次独立的重复实验。十个实验的平均值被定义为最终的LTME,定量地反映了线性轨迹的整体近似。
4.4.3. 评价结果
Kinect v2和Intel RealSense SR300的评估结果如图所示。分别为6和7。对于紧凑性,省略了x轴和y轴的标签。对于所有子图形,x轴表示速度(单位:mm/s),y轴表示LTME(单位:mm)。第一、第二和第三列中的子图分别对应于三个起始运动位置p1、p2和p3的评估结果。
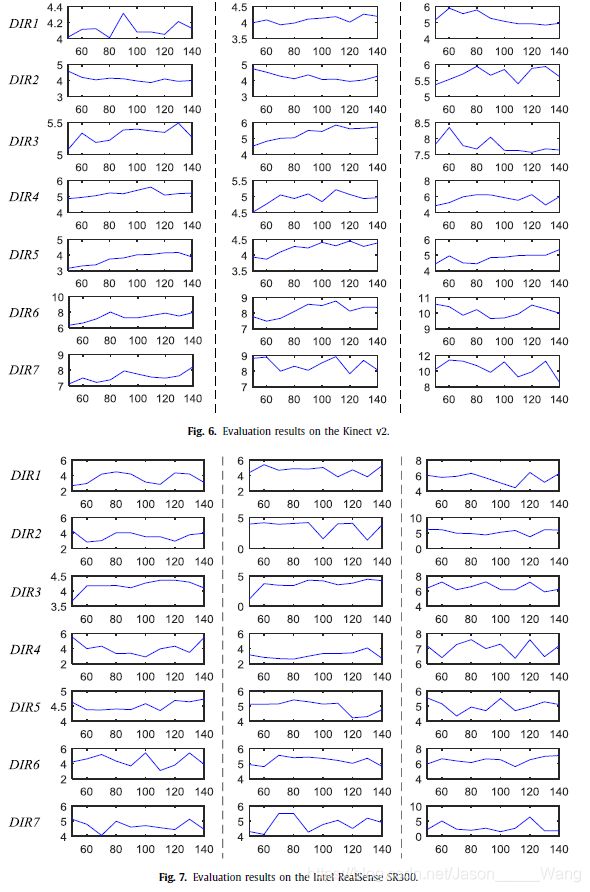
同一行中的子图形对应于相同的运动方向。七行代表七个运动方向。每个子图中的虚线由十个点组成。每个点对应一个运动速度。表7给出了七个运动方向和十个运动速度。根据第4.4.2节中描述的十个独立重复实验,计算折线中每个点的LTME。我们以第三行第二列中的子图为例进行进一步说明。此子图显示LTME随运动速度变化的情况,其中起始运动位置为P2,运动方向为DIR3。
从图中至少可以得出两个重要结论。6号和7号。首先,正如预期的那样,当摄像机和关注点之间的距离增加时,跟踪精度通常会降低。对于Kinect v2和Intel RealSense SR300,如果我们仔细比较同一行中的三个子图形,即运动速度和运动方向是固定的,我们可以发现从p2到p3的跟踪精度下降比从p1到p2更为显著。超过p2后,跟踪精度明显下降。因此,建议使用这两个摄像机的范围在p2的范围内。
其次,我们可以看到不同的折线没有统一的变化趋势,因此在试验范围内跟踪精度与运动速度之间没有必然的联系。对于Kinect v2,相对振幅方面的LTME变化不大;例如,p1处DIR1的LTME从4 mm到4.4 mm不等。与Kinect v2相比,Intel RealSense SR300的LTME变化更为明显。换句话说,Kinect v2的跟踪结果比Intel RealSense SR300的跟踪结果更稳定。其中一个重要的原因是使用不同的传感原理(ToF与结构光)。
4.4.4. 与静态测量结果的比较
在本质上,一个动态测量实验是同时引入时间约束和运动轨迹约束的多个静态测量实验的顺序组合。为了突出我们的实验评估动态跟踪精度的必要性,我们与现有的静态测量结果进行了比较。根据Lachat等人[69]报告的Kinect v2技术规范,当相机距离物体0.5 m时,深度精度约为1.4 mm。Yang等人[68]进行的测量实验表明,当Kinect v2与物体的距离在0.5 m至3 m、3 m至3.5 m和3.5 m至4 m之间时,深度精度分别小于2 mm、2 mm至4 mm和大于4 mm。
根据官方网站提供的Intel RealSense SR300数据表[188],当到物体的距离小于1米时,深度精度在1毫米到3毫米之间。House等人[60]进行的测量实验表明,在20×16×10cm的工作空间内,intelrealsenessr300的定位精度为3.3mm。
我们可以看到我们的动态测量结果如图所示。6和7大于现有静态测量结果。这种差异是由测量方法和精度定义造成的。静态测量实验通过测量固定兴趣点与摄像机之间的距离来评估定位能力,而我们的实验通过测量动态兴趣点与摄像机之间的距离来评估跟踪能力。实际上,深度相机沿不同方向的精度分布是不同的[60,67–68],但是静态测量实验没有考虑这种耦合效应。这就是静态测量方法不能推广到动态评价实验的原因。关于跳跃运动的静态测量结果和动态测量结果的比较[79]也反映了这一事实。
为了直观地显示摄像机跟踪兴趣点过程中的系统误差,我们采集并观察了图4所示的白瓷棒的分段深度图。在考虑最佳工作距离的基础上,白瓷棒距离Kinect v2为1.0米,距离Intel RealSense SR300为0.5米。每一个运动步记录一个深度图,深度为5mm。Kinect v2和Intel RealSense SR300获取的分段深度图分别如图8 a和b所示。这两个摄像头的边缘差和形状扭曲说明,对于一个与人类手指大小相似的物体,这两个摄像头的成像质量不是很好。

4.4.5. 手位估计的意义
我们尝试使用三个最广泛使用的基准数据集来找出最佳方法。Rad等人[124]提出的方法在纽约大学数据集上实现了5.5mm的平均欧氏距离误差,Moon等人[126]提出的方法在ICVL数据集上实现了6.3mm的平均欧氏距离误差,Wan等人[153]提出的方法在MSRA15数据集上获得了平均7.2mm的欧氏距离误差。当NYU、ICVL和MSRA15数据集最初发布时,平均欧氏距离误差分别为19.8 mm[101]、12.6 mm[100]和15.2 mm[105]。我们可以看到,在过去的四年中,手姿势估计得到了迅速的发展。
从表6与7中,不难看出,在适当的条件下,两台摄像机的最佳跟踪精度大约在4 mm到6 mm之间。用于记录纽约大学、ICVL和MSRA15数据集的摄像头是在四年前发布的,它们的性能最多与Kinect v2[72]和Intel RealSense SR300[67]相同。在不考虑手部检测误差的情况下,现有最佳方法的平均欧氏距离误差已接近用于记录三个数据集的摄像机的精度极限,但在目前的定量评价实验中,完全忽略了摄像机的系统误差影响。这就是为什么我们声称,明确动态跟踪精度有助于重新评估现有的手姿态估计方法。
我们相信,在未来几年,新兴的手姿势估计方法将打破相机的精度限制,用于记录数据集,如纽约大学,ICVL和MSRA15。为了对不同的方法进行独立于摄像机的比较,有必要引入新的由高精度摄像机记录的基准数据集。深度相机的发展似乎不如手部姿态估计方法的发展那么快。我们的评估实验是在接近理想的条件下进行的,例如适当的距离和均匀的照明。我们发现,如果把相机放在具有挑战性的环境中,实验结果会变得更糟,特别是对于Intel RealSense SR300。图9显示了由两个具有不均匀照明的相机获取的白瓷棒的一些分段深度图。由于Intel RealSense SR300基于结构光,因此更容易受到照明的影响。

5.结论
在过去的几年里,无论是在学术研究还是在商业产品中,手姿势估计领域都取得了令人瞩目的进展。基准数据集的最佳记录不断被打破。然而,对于基于真实手势的人机交互系统来说,手的姿态估计还远远不够理想。关于摄像机、方法、数据集和应用的一些问题仍然没有解决。
尽管摄像机在推动手部姿态估计的研究中起到了重要作用,但目前它们仍然是阻碍手部姿态估计进展的瓶颈,即使在理想情况下,其动态跟踪精度也反映了这一点。由于捕获范围、深度分辨率以及对光照和材料表面的鲁棒性有限,基于室外深度的手姿态估计一直没有被研究过。深度相机的影响至少在短期内不应被忽视。相反,基于室外RGB的手姿势估计已经被研究[156157]。由于Cannikin定律(或木桶理论),将RGB视频和深度图的主要优点结合起来的可能性很低;例如,ToF深度相机可以部署在黑暗环境中,但RGB相机不能。
就方法而言,有四个局限性。首先,现有的研究主要集中在限制性的手姿态估计上,例如假设手的背景是干净的,这样可以很容易地分割出手,场景中只假设一只手,如何处理两只手的交互,目前还不清楚,手-物交互下的手姿态估计很少研究。其次,基于深度学习的方法已经成为主流,对于其中许多方法来说,实时性能是由高端GPU保证的。这可能会限制便携式设备的应用,例如手机和智能手表。第三,目前的方法只能在室内环境中进行测试。在挑战性的环境中,它们的有效性是未知的。第四,单视点手姿态估计是一个不适定问题。引入多个摄像头可能是一个有效的方法,以减轻部署的便利性为代价的缺点。目前,多视点手部姿态估计还没有得到足够的重视。
在数据集方面,如何自动获得高质量的注释数据仍然没有得到很好的解决。真实深度图以半自动或手动方式标注,精度有限。合成帧会自动生成,但真实的合成差异会影响最终模型。
在应用方面,现有的手位估计成果仅通过实证检验。如何真正弥合理论成果与应用之间的鸿沟的研究相对较少,例如Midas触摸问题[158]。毫无疑问,手部姿态估计的进展将给虚拟装配、机器人抓取等许多工业领域带来福音。
总之,我们认为未来的研究工作应该集中在准确性、效率、健壮性、通用性和适用性等方面。手势估计的实际意义在于它为基于手势的人机交互系统打开了大门。毫无疑问,随着深度相机的发展,快速增长的手部姿态估计方法正在悄然加速虚拟现实和增强现实的普及。