FusionPainting: Multimodal Fusion with Adaptive Attention for3D Object Detection(多模态融合与自适应注意的3D物体检测)
摘要:三维障碍物的精确检测是自动驾驶和智能交通的一项重要任务。在本研究中,我们提出了一个通用的多模态融合框架FusionPainting,在语义层面融合2D RGB图像和3D点云,以增强3D目标检测任务。特别是,FusionPainting框架由三个主要模块组成:多模态语义分割模块、自适应的基于注意的语义融合模块和3D对象检测器。首先,基于二维和三维分割方法获取二维图像和三维激光雷达点云的语义信息;然后,基于所提出的基于注意的语义融合模块对来自不同传感器的分割结果进行自适应融合。最后,将有融合语义标签的点云发送给三维检测器,获得三维目标结果。在大规模nuScenes检测基准上,通过与三种不同基准的比较,验证了该框架的有效性。实验结果表明,与仅使用点云的方法和仅使用点云绘制二维分割信息的方法相比,该融合策略能显著提高检测性能。此外,该方法在nuScenes测试基准测试中优于其他最先进的方法。代码可在 https:
//github.com/Shaoqing26/FusionPainting/获得。
1.介绍
三维目标检测作为计算机视觉和机器人技术的基础任务,随着自动驾驶和智能交通的发展得到了广泛的研究。目前,激光雷达传感器被广泛应用于感知任务中,因为它可以提供对周围环境的精确距离测量,特别是对车辆、行人和骑自行车等障碍物的测量。随着基于点云表示的深度学习技术的发展,许多基于lidar的三维目标检测方法被开发出来。通常,这些方法可以分为基于点的和基于体素的方法。激光雷达传感器具有提供障碍物距离信息的优势,尽管由于其扫描稀疏,往往会丢失详细的几何形状信息,而且无法捕获纹理和颜色信息。因此,在基于lidar的目标检测方案中,经常出现假阳性(FP,False Positive)检测和错误分类的问题。
相反,相机传感器可以提供高分辨率的详细纹理和颜色信息,尽管在基于透视投影的成像过程中会丢失深度。将激光雷达和相机这两种不同类型的传感器相结合,是提高自动驾驶感知性能的一种很有前途的方法。在文献中,基于多模态的目标检测方法可分为早期融合、深度融合和晚期融合。早期的融合方法旨在在将原始数据发送到检测框架之前直接将其合并,从而创建一种新的数据类型。通常,这类方法需要每种类型传感器数据之间的像素级通信。与早期融合方法不同的是,后期融合方法首先对每种类型的数据分别进行检测,然后将检测结果融合在边界框(bounding box)级别。与上述两种方法不同的是,基于深度融合的方法通常是先提取具有不同类型深度神经网络的特征,然后在特征级别进行融合。PointPainting是一种简单而有效的顺序融合方法,在不同的基准上都取得了优异的检测结果。该方法首先利用现成神经网络的二维图像语义分割结果,然后将其添加到基于2D-3D投影的基于点云的三维目标检测中。PointPainting的优越性表明,二维图像分割方法可以用于提供语义结果,它可以合并到任何三维物体检测器中,甚至是基于点或基于体素的方法。
然而,在基于图像的语义分割方法中,由于深度特征图的分辨率较低,往往会产生边界模糊效应。在将它们重新投射到3D点云之后,这种效果变得更加严重。将二维结果重新投影到三维的一个例子显示在子图1 - (a)中。以图像底部的大卡车为例,我们可以发现在二维图像中,由于分割结果不准确,背景中有很大的截锥区域(如橙色的点)被误分类为前景。此外,由于数字量化问题和多对一投影问题,3D点与2D图像像素的对应并不是精确的一对一投影。一个有趣的现象是,从3D点云(例如,子图1-(b))在障碍物边界上表现更好。然而,由于来自RGB图像的详细纹理信息,与2D图像相比,来自3D点云的类别分类往往会给出更差的结果(蓝色的点)。
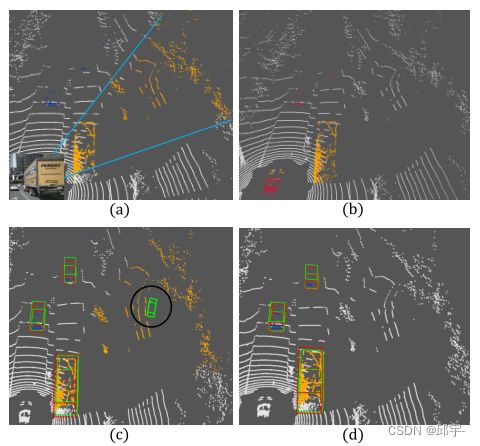
图1:(a)二维分割结果绘制的点云。蓝线内的截锥体由于边界模糊效应显示了分类错误的区域;(b)根据3D分割结果绘制点云(错误分类的点用红色表示);(c)和(d)分别给出基于二维绘制点云(a)和提出的二维/三维融合框架的假阳性(FP,False Positive)目标检测结果。
带有语义信息的画点被证明是非常有效的目标检测任务,即使存在一些语义错误。一个直观的想法是,如果二维和三维分割结果可以融合在一起,检测性能可以进一步提高。基于这一思想,我们提出了一种通用的多模态融合框架“FusionPainting”,在语义层面融合不同类型的传感器,进一步提高三维目标检测性能。首先,直接使用现成的语义段来获取语义信息。为了进一步提高性能,提出了一种注意模块,该模块基于学习到的上下文特征,以自注意方式自适应融合体素级的不同语义信息。最后,将融合后的语义标签绘制的点发送给三维检测器,获得最终的检测结果。这项工作的主要贡献可以概括如下:
(1)首次提出了一种通用的多模态融合框架“FusionPainting”,在语义层面融合不同类型的信息,以提高三维目标检测性能。
(2)为了进一步提高性能,提出了一个注意模块,通过学习上下文特征在体素级融合不同类型的语义信息。
(3)在大型自动驾驶基准nuScenes上的实验结果表明了所提出的融合框架的优越性,与其他方法相比获得了SOTA结果。
2.相关工作
A.点云中的3D目标检测
现有的基于点云的三维物体检测方法可分为基于投影的、基于体素的、和基于点的。RangeRCNN是一个典型的基于距离图像,在BEV(鸟瞰图)地图上生成锚点的三维目标检测框架。与以往的手工特征设计不同,VoxelNet提出了一个VFE(voxel feature encoding,体素特征编码)层,可以学习每个3D体素的统一特征表示。基于VoxelNet, CenterPoint提出了一种无锚方法,使用基于中心的框架,基于CenterNet,并实现了最先进的性能。SECOND利用了稀疏卷积操作,减轻了3D卷积的负担。PointPillars使用PointNet从垂直列(pillars,柱子)中提取特征,并将特征编码为伪图像,然后应用2D对象检测管道。PointRCNN是一个从原始点云直接生成3D建议的先驱工作。此外,PV -RCNN集成了多尺度3D体素CNN和基于PointNet的网络,学习更多的鉴别特征。
B .多模式融合
多种方法结合多种类型的感官数据来提高检测性能。激光雷达和照相机是最常用的传感器。MV3D提出了一种包括BEV、摄像机视图和前视图图像的多视图表示方法。该框架从BEV生成建议,并深度融合来自其他视图的功能。AVOD以LiDAR点云和RGB图像为输入,生成RPN(region proposal network,区域建议网络)和细化网络共享的特征。F-PointNet使用图像生成建议,并使用PointNet在裁剪的函数集(frustum)中改进最终的边界框。与上述方法不同,PointPainting使用了一种简单而有效的策略:通过将每个点的类得分向量投影到图像语义分割结果中,检索每个点的类得分向量(the class score vector),并将拼接后的属性输入到3D对象检测框架中。多任务融合也是一种有效的技术,例如[19]将语义分割与3D对象检测任务结合起来,可以进一步提高性能。此外,在[29]和[30]中,还将高清地图作为自动驾驶场景下可移动目标检测的强先验信息。
3.建议的方法
我们在图2中描述了我们的“FusionPainting”框架的架构。我们提出利用二维图像和三维点云信息来获取自动驾驶场景下障碍物的精确三维位置。在这里,融合过程是通过在语义级别上自适应地集成2D和3D信息来实现的。如图2所示,所提出的框架由三个模型组成,分别是多模态语义分割模块、自适应注意模块和三维检测器模块。
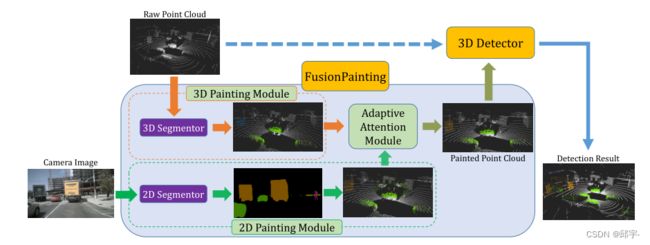
图2:“FusionPainting”框架的概述。首先用二维和三维分割器对输入点云和二维图像进行处理,得到语义估计;然后,采用自适应注意模块在语义层面融合两类传感器。最后,将绘制好的点云发送到现代3D探测器中产生检测结果。
首先,可以使用任何现成的2D和3D分割器分别对RGB图像和LiDAR点云进行语义分割;然后提出了一种简单有效的注意策略,以充分利用二维和三维语义结果的优点,抑制其缺点。最后,将带有增强语义标签的绘制3D点云发送到现代3D目标检测器,以获得最终的检测结果。
A.多模态语义分割
2D绘画模块:2D图像包含丰富的纹理和颜色信息,可以为点云提供补充线索,有利于3D检测。
为了从二维图像中获取有用的信息,我们利用语义分割网络生成像素级语义标签。特别地,所提出的框架与具体的细分模型无关,任何先进的方法都可以在这里使用,如Deeplabv3,PSPNet , HTC, FCN, MobelNetV3等。该分割网络将多视图图像作为前景实例和背景实例的输入和输出像素分类标签。在这里,我们将二维分割结果表示为S∈Rw×h×m,其中w, h为输入图像的宽度和长度,m为类数。按照[5]中的顺序融合策略,我们使用提供的摄像机投影矩阵将像素级的2D分割掩码重新投影到相应的3D点。假设内参矩阵为K∈R4×4,外参矩阵为M∈R3×4,原始三维点为P∈RN×3,则三维点云从LiDAR坐标到摄像机坐标的投影可描述为
p'= Proj(K, M, P) (1)
其中p'为摄像机坐标中的投影点,“Proj”表示项目过程。通过这种投影,可以将二维图像中的语义标签分配到三维点云上。将逐像素语义评分以一热编码方式表示,可得到二维绘制点为P2D∈RN×m。
3D Painting模块:除了二维的语义分割,我们还考虑从LiDAR点云中交替获取语义信息。具体来说,直接使用三维分割网络Cylinder3D获得逐点分割掩码。Cylinder3D是一种新颖的3D分割方法,它使用圆柱形的(cylindrical)、非对称(asymmetrical)3D卷积网络来实现SOTA性能。此外,任何SOTA 3D分割器,如Polarnet, AF2S3Net, RPVNet可用于提议的框架。此外,不需要任何额外的点语义注释(pointwise semantic annotations),我们可以自由使用3D对象边界框注释来生成分割标签。对于前景实例,3D边框内的点直接用相应的类标签分配。并将所有三维边界框外的点作为背景。从这个角度来看,提出的框架可以直接工作在任何3D检测数据集上,而不需要任何额外的点语义注释。得到训练过的网络后,可直接从分割结果中得到三维绘制点P3D∈RN×m。
B.自适应注意模块
虽然二维分割取得了令人印象深刻的效果,但由于特征图分辨率有限,边界模糊效应也不可避免。因此,二维分割掩模绘制的点云在物体边界周围通常存在分类错误的区域。例如,截锥区域如图1(a)所示大卡车后面。相反,基于点云的语义分割方法往往能产生清晰、准确的对象边界,如子图1 (b)。为了综合这两个模块的优点和抑制它们的缺点,我们提出了一种自适应注意模块,该模块将语义标签与注意机制自适应融合。通过这样做,改进后的语义标签可以进一步提高下面的3D检测结果。
所提出的自适应注意模块的详细架构如图3所示。通过定义输入点云为{Pi, i = 1,2,3…N},每个点Pi包含(x, y, z)坐标和其他特征(如果它们有的话),如强度和其他属性。为简单起见,在以下上下文中只考虑坐标(x, y, z)。我们的目标是找到一种最优的策略来融合二维分割P2D和三维分割P3D的语义标签。在此,我们提出利用学习注意掩码(the learned attention mask)来融合标签类型。具体来说,我们首先通过拼接操作将点坐标、属性和2D/3D标签组合在一起,得到一个大小为N × (2m + 3)的融合点云。为了节省内存消耗,下面的融合在体素级而不是点级执行。具体来说,每个点云被划分为均匀分布的体素,每个体素包含固定数量的点。这里,我们将体素表示为{Vi, i = 1,2,3…E},其中E为体素的总数,每个体素Vi∈RM×(2m+3)包含固定数量的M个点,具有2m+3个特征。该方法利用采样技术,使每个体素中的点数与k保持一致。然后,采用局部和全局特征聚合策略,估计每个体素的注意权重,以确定二维和三维语义标签的重要性。
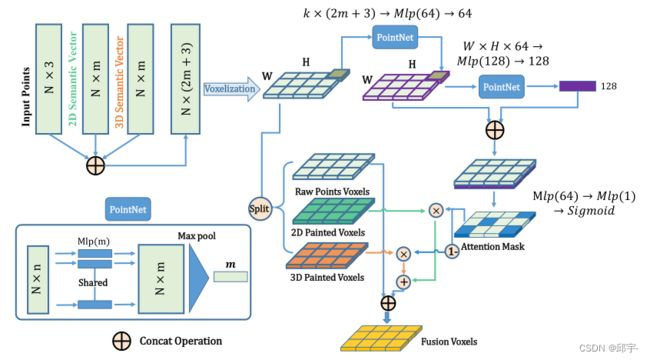
图3:提出的自适应注意模块的架构。首先利用输入点和2D/3D语义预测学习注意掩码。然后,利用学习注意掩模对原始体素进行二维/三维自适应语义标记;
对于局部特征,这里使用一个PointNet类模块来提取每个非空体素中的体素相关信息。对于第i个体素,其局部特征可以表示为
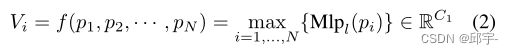
其中Mlpl(·)和max为局部多层感知(Mlp,multilayer local perception)网络和最大池化操作。具体而言,Mlpl(·)由线性层、批处理归一化层、激活层组成,通过C1通道输出局部特征。为了获得全局特征信息,我们基于E体素聚合信息。特别地,我们首先使用一个Mlpg(·)将每个体素特征从C1维映射到C2维。然后,在所有体素上应用另一个类Pointnet模块
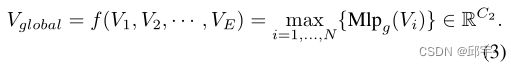
最后将全局特征Vglobal展开到体素数相同的大小,并将其与各个局部特征Vi连接,得到最终融合的局部和全局特征Vgl∈RN×(C1+C2)。
然后,采用融合特征Vgl估计每个体素的注意得分(attention score)。这是通过在Vgl上应用另一个Mlp模块mlpat(·)和Sigmod激活函数σ(·)来实现的。然后,我们将置信度分数乘以体素中每个点对应的单热点语义向量(one-hot semantic vectors),表示为
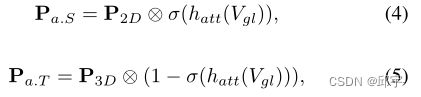
其中P2D和P3D分别为2D和3D语义分割标签,Pa.S和Pa.T是相应的增强特征。最后,我们融合{Pa.T,Pa.S}∈RN×M×m,每个体素中的原始点P得到增强体素Vm∈RN×M×(3+2m),其中m, M为体素中的语义类数和点数。最后,Vm包含了二维和三维语义标签的自适应融合信息。
C. 3D物体检测模块
在得到绘制的点云后,任何现成的3D物体检测器都可以直接用于预测3D物体检测。3D检测器接收自适应注意模块产生的绘制体素,并对所有类别获得较好的结果。详细的性能分析可以在下面的实验结果部分中找到。
4.实验结果
我们评估了所提出的“FusionPainting”在大规模自动驾驶三维物体检测数据集上的有效性。首先对实验进行了详细描述,然后给出了三种基线检测器的评价结果。
A.检测器,数据集和实现细节
基线:此外,为了验证它的通用性,我们已经在三个不同的先进3D物体检测器上实现了所提议的模块,如下所示:
•SECOND,首次将稀疏卷积应用于基于体素的三维物体检测任务中,相比以往的VoxelNet等工作,检测效率有了很大的提高。
•PointPillars,将点云划分为柱子,对每个柱子使用“柱子特征网(Pillar Feature Net)”提取点特征。然后在鸟瞰图(BEV)特征图上采用二维卷积网络进行目标检测。PointPillars是效率和性能之间的权衡。
•CenterPoint,是第一个基于无锚的3D物体检测器,非常适用于小物体的检测。
数据集:nuScenes使用3D对象检测基准进行评估,这是一个共有1000个场景的大型数据集。为了比较公平,我们将数据集正式分为train(训练集)、val(validation,验证集)和testing(测试集),分别包含700个场景(28130个样本)、150个场景(6019个样本)、150个场景(6008个样本)。每个视频只对关键帧(每0.5s)进行360度标注。nuScenes使用32线激光雷达,每帧包含大约30万点。在目标检测任务中,考虑了“汽车”、“卡车”、“自行车”和“行人”等10种障碍物。除了点云,每个关键帧还提供了相应的RGB图像。对于每个关键帧,有6张图像,覆盖360个视场。
评价指标:对于3D对象检测,[45]提出均值平均精度(mAP)和nuScenes检测评分(NDS)作为主要指标。与[46]中定义的原始mAP不同,nuScenes考虑阈值为{0.5,1,2,4}米的BEV中心距离,而不是边界框的IoUs。NDS是mAP和其他度量分数的加权和,如平均翻译误差(ATE,average translation error)和平均比例尺误差(ASE,average scale error)。
实现细节:这里分别使用HTCNet和Cylinder3D作为2D分割器和3D分割器,因为它们具有出色的语义分割能力。二维分割器在nuImages数据集上预训练,三维分割器在nuScenes检测数据集上预训练,通过提取障碍物每个边界框内的点生成点云语义信息。对于自适应注意模块(Adaptive Attention Module), m = 11, C1 = 64, C2 = 128,对于每个基线,所有实验都使用相同的设置,SECOND、PointPillar和CenterPoint的体素大小分别为0.2m × 0.2m × 8m、0.1m × 0.1m × 0.2m和0.075m × 0.075m × 0.075m。我们使用最大学习率0.001的AdamW作为优化器。接下来,10个以前的激光雷达扫描堆叠到关键帧,使点云更密集。
B.评价结果
我们已经在nuScenes基准上评估了该框架的验证和测试分割。
基线方法的评估:首先,我们将提出的融合模块集成到三种不同的基线方法中,在实验上,与所有基线相比,我们在mAP和NDS上都取得了一致的改进。详细的结果在Tab.1中给出。从这张表中我们可以明显发现,提出的模块对三个基线的mAP都有10分以上的改进,NDS都有5分以上的改进。在mAP和NDS上,PointPillars方法的改进分别达到17.31分和8.45分。此外,我们发现“交通锥”,“摩托”和“自行车”相比其他类别有了惊人的改进。特别是“自行车”类,AP在Second、PointPillar和Centerpoint的基础上分别提高了36.19%、48.83%和26.84%。有趣的是,所有这些类别都是很小的物体,因为它们上面有一些激光雷达点,所以很难被探测到。通过添加先验语义信息,使分类变得相对容易。特别是,我们这里的实验使用的是相同的设置,所以基线数据可能与官方数据有细微的差异。
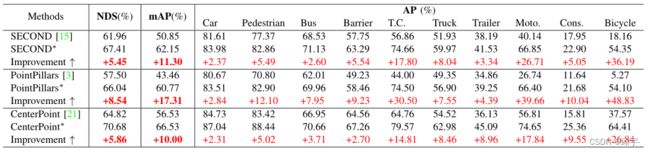
表I: nuScenes验证数据集的评估结果。“NDS”和“mAP”表示nuScenes检测分数和均值平均精度。“T.C.”、“Moto.”和“Cons.”分别是“交通锥”、“摩托车”和“施工车辆”的简称。“*”表示通过添加建议的“FusionPainting”而改进的基线。为了提高我们的方法的有效性,每种方法的改进用红色表示。
与其他SOTA方法的比较:为了将提议的框架与其他SOTA方法进行比较,我们将我们的最佳结果(在CenterPoint上提议的模块)提交给nuScenes评估服务器。详细的结果列在Tab.2中。由于篇幅所限,这里只比较有出版物的这些方法。从这个表中我们可以发现,与基线方法CenterPoint相比,“NDS”和“mAP”分别提高了3.1分和6.0分。更重要的是,我们的算法大大优于之前的多模态方法3DCVF,即在NDS和mAP指标方面提高了8.1和13.6点。
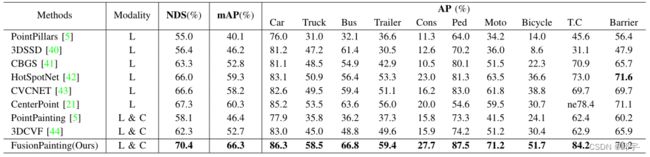
表II: nuScenes 3D对象检测基准上与其他SOTA方法的比较。模态列中的“L”和“C”分别代表激光雷达和相机。对于每一列,我们使用粗体来说明其他方法的最佳结果。在这里,我们只列出所有方法的结果与出版物。
C .定性结果
更多定性检测结果如图4所示。图4 (a)为标注后的ground truth, (b)为基于原始点云不使用任何绘制策略的CenterPoint检测结果。(c)和(d)分别为二维点云和三维点云的检测结果,(e)为基于我们提出的框架的检测结果。如图所示,由于截锥模糊效应(frustum blurring effect),二维绘制会产生假阳性检测结果,而三维绘制方法的前景类分割效果较二维图像分割差。相反,我们的FusionPainting可以结合来自2D和3D分割的两个互补信息,并更准确地检测物体。
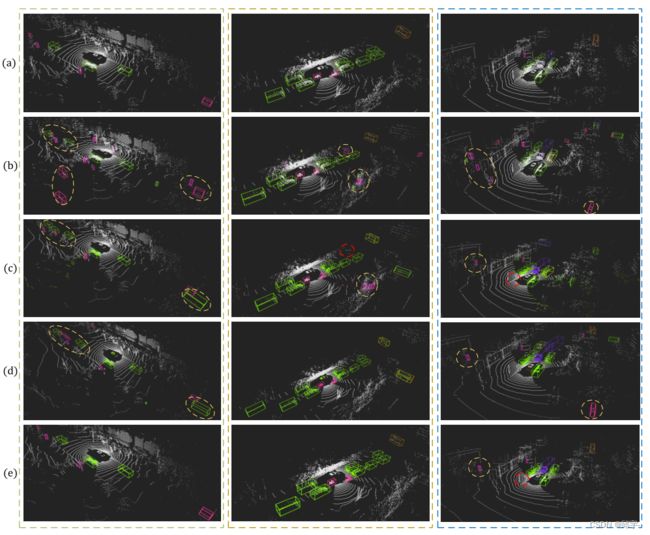
图4:检测结果可视化,其中(a)为ground-truth, (b)为基于原始点云的检测结果,(c)、(d)、(e)分别为基于具有2D语义信息、3D语义信息和融合语义信息的投影点的检测结果。特别是黄色和红色的虚线椭圆分别表示一些误检和漏检。这里使用的基线检测器是CenterPoint。
D.融合研究
为了验证不同模块的有效性,本文设计了一系列的消融研究。所有的实验都在验证分割上执行,设置与第4 -A节相同。所有的结果都在Tab.3中给出,从那里我们可以计算出每个模块的影响。
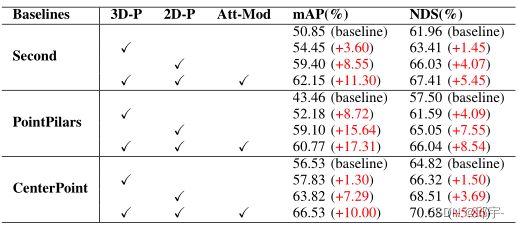
表3:不同融合策略的消融研究。“Att-Mod”是“Adaptive Attention Module”的缩写,“3D- P”和“2D- P”分别是“3D Painting Module”和“2D Painting Module”的缩写。
如Tab.3中所示,仅三维语义分割信息对mAP和NDS的贡献率分别为9.81%和3.92%,而二维语义分割信息对mAP和NDS的贡献率分别为21.90%和8.46%。二维语义信息的更高改进得益于更好的回忆能力,特别是对点云稀疏的距离范围内的对象。三维语义信息的优点是点云可以很好地处理物体之间的遮挡,而这在二维中是非常常见的,很难处理的。但最大的改善来自于3D Painting、2D Painting和自适应注意模块的结合,我们使用的3个检测器平均mAP为26.58%和10.90%。
5.结论及未来工作
我们提出了一种新的多模态融合框架“FusionPainting”,它可以融合来自2D/3D语义分割网络的丰富语义信息。更重要的是,我们首次使用三维语义分割结果作为附加信息来提高三维目标检测性能。为了融合2D/3D分割结果,提出了一种自适应注意模块来学习它们各自的注意掩码(attention mask)。在nuScenes数据集上的实验结果表明了该策略的有效性。此外,所提出的“FusionPainting”是独立于检测器的,可以自由地用于其他3D物体检测器。未来,我们计划将2D/3D语义分割分支深度集成到检测框架中,同时实现实例分割和3D对象检测任务。