基于集成学习的不平衡数据集分类问题研究--文献阅读

参考文献
基于集成学习的不平衡数据集分类问题研究 - 中国知网 https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CMFD&dbname=CMFD202201&filename=1021697818.nh&uniplatform=NZKPT&v=K9J_5NETTyZXPhDr5D6KwISCv2zm0skRm7rEZ0KmYS0Yv_zs562Re8oiwR5h_ylK
https://kns.cnki.net/kcms/detail/detail.aspx?dbcode=CMFD&dbname=CMFD202201&filename=1021697818.nh&uniplatform=NZKPT&v=K9J_5NETTyZXPhDr5D6KwISCv2zm0skRm7rEZ0KmYS0Yv_zs562Re8oiwR5h_ylK
文章总体思路
问题
当应用于不平衡数据集时,这两种算法都存在对样本量较少的正类样本不能正确分类以至于分类精度不高、泛化误差较大的问题
目的
本文将集成学习算法与不平衡数据集数据层面的优化算法组合构造分类性能更好的模型
算法结合构造的新模型
机器学习算法
随机森林与 XGBoost
数据处理算法
SMOTE 过采样、随机欠采样以及 SMOTEtomek 混合采样
结合结果
RUS-RF、SMOTE-RF、SMOTEtomek-RF、
RUS-XGBoost、SMOTE-XGBoost 和 SMOTEtomek-XGBoost 模型
数据集:
本文选用了 UCI 中的 Adult 数据集,同时利用与 Adult 数据集不平衡比例不同的 BankMarketing 数据集与 Credit Card 数据集进行结果对比
实验发现:
(1)从总体来看,以 XGBoost 为基础算法的模型的分类效果要优于以随机森林为基础算法的模型;
(2)从模型选择的角度来看,当样本量充足时,RUS-XGBoost 模型的 AUC 与 G-mean 取值最高,比起其他模型更适合作为不平衡数据集的有效分类模型;
(3)从数据重采样方法的角度来看,采用随机欠采样的模型比采用SMOTE 过采样或者 SMOTEtomek 混合采样的模型分类效果更好。
为什么要对此进行研究
机器学习致力于利用机器从已知数据中挖掘数据规律并生成学习模型进而对未知数据做出反馈。
传统的机器学习方法如决策树、K 最近邻、支持向量机以及人工神经网络等算法都是根据平衡数据设计的,以提高总体分类精度为目标,这就使得在不平衡数据中进行学习时,极易造成分类器倾向于负样本,导致误分成本上升。
针对分类任务,多数学习算法都有一个共同的基本假设——不同类别的训练样本数目相当。如果不同类别的样本数稍有差别,通常对算法的泛化性能影响不大,但是若不同类别样本数差别很大即存在类别不平衡问题,则会对学习过程造成困扰。
采样方法研究现状
欠采样
欠采样:通过选择部分具有典型意义的负样本,构造正样本与负样本数目相当的平衡数据集。随机欠采样是最简单有效的欠采样方法,它随机抽取出与正样本一致规模的负样本,然后将抽取到的负样本放入正样本空间中组成新的平衡数据集。
随机欠采样(Random Under-Sampling,RUS)
是最简单的欠采样方法,该算法通过从负类样本中随机抽取与正类样本规模一致的数据来达到数据平衡,然而抽取样本同样会造成关键信息的流失;
Easy Ensemble 算法与Balance Cascade 算法,
这两种算法都采用了集成的思想,对负类样本进行多次采样构建不同的分类器,从而弥补随机欠采样存在的弊端
基于聚类的欠采样:
CBUS算法和 Fast-CBUS算法
遗传算法的欠采样:
GAUS算法以及类似于噪声检测的 ENN算法和 Tomek算法
过采样
过采样:通过生成足量的正样本实现正样本与负样本的平衡。其优点是提高了正样本的学习量;缺点是生成的正样本并不是通过抽样得到的真实正样本,从而容易带来样本噪声,降低算法模型少数类样本的分类正确率
随机过采样
基本步骤
是反复随机地抽取正样本,并将抽取到的样本放入原始样本空间,形成新的样本空间
优点
抽样方法速度很快
缺点
会在正类样本中产生大量相似数据,因此在分类器的训练中容易使模型过拟合。同样, 如果正类样本中存在噪声数据,那么在多次抽取正类样本后,噪声数据对模型的影响也会增 大
SMOTE 算法
改进方面
采用数据合成的方式取代数据替换来进行过采样
步骤
 Borderline-SMOTE 算法与 ADASYN 算法
Borderline-SMOTE 算法与 ADASYN 算法
针对 SMOTE 算法没有考虑近邻样本的分布特点带来的样本重叠度高的问题
混合采样
结合了欠采样和过采样,
目前常用的算法有:
将随机欠采样和 SMOTE 组合的 RU-SMOTE算法,
将 SMOTE 和Tomek 结合的 SMOTEtomek 算法

将 SMOTE 和 ENN 结合的 SMOTEENN 算法。
不平衡数据集算法层面的优化方法
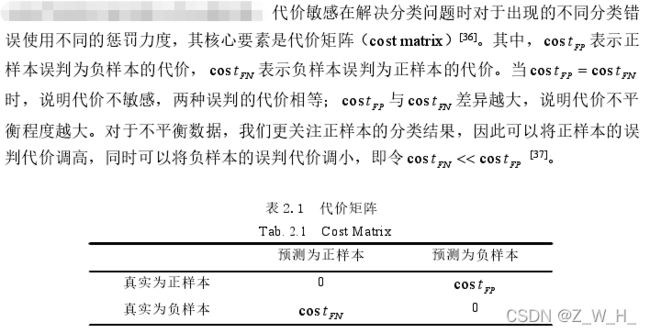
价敏 感(Cost-Sensitive) 学习、集成学习、单类学习