CycleGAN 源码解析
转载自:(7条消息) CycleGAN官方pytorch源码解读_Quality5899的博客-CSDN博客_cyclegan源码 https://blog.csdn.net/Quality5899/article/details/116600981
https://blog.csdn.net/Quality5899/article/details/116600981
本文主要分析了网络架构与loss的计算
该脚本为训练的起始脚本,在前几行首先实例化TrainOptions(继承了BaseOptions)来接收命令行输入参数。
opt = TrainOptions().parse() # get training options
然后是数据集的加载部分
dataset = create_dataset(opt)
紧接着就是加载模型的相关代码,要寻找网络架构一般从在这里入手
model = create_model(opt)
models/_init_.py
我们跳到create_model方法查看该函数
def create_model(opt):
"""Create a model given the option.
This function warps the class CustomDatasetDataLoader.
This is the main interface between this package and 'train.py'/'test.py'
Example:
>>> from models import create_model
>>> model = create_model(opt)
"""
model = find_model_using_name(opt.model)
instance = model(opt)
print("model [%s] was created" % type(instance).__name__)
return instance
使用find_model_using_name来导入对应的包,例如如果命令行输入参数为cycle_gan则会导入models中的cycle_gan_model.py模块, 如下面代码中print的结果所示:
def find_model_using_name(model_name):
model_filename = "models." + model_name + "_model"
modellib = importlib.import_module(model_filename)
model = None
target_model_name = model_name.replace('_', '') + 'model'
print(modellib.__dict__.items())
for name, cls in modellib.__dict__.items():
if name.lower() == target_model_name.lower() \
and issubclass(cls, BaseModel):
model = cls
if model is None:
print("In %s.py, there should be a subclass of BaseModel with class name that matches %s in lowercase." % (model_filename, target_model_name))
exit(0)
"""
我们在这里输出一下几个值,我选择的模型是cycle_gan:
print(model_name) #output:cycle_gan
print(target_model_name) #output:cycleganmodel
print(modellib) #output:
exit()
"""
return model
model = cls 成功将模型类拿到,最后用return返回,再回到create_model中利用opt实例化模型
instance = model(opt)
实例化便会调用所选模型的**_init_()方法,以CycleGANModel**为例:
cycle_gan_model.py: class CycleGANModel(BaseModel)
下面是**_init_()**方法中的网络构造代码
self.netG_A = networks.define_G(opt.input_nc, opt.output_nc, opt.ngf, opt.netG, opt.norm, not opt.no_dropout, opt.init_type, opt.init_gain, self.gpu_ids)
self.netG_B = networks.define_G(opt.output_nc, opt.input_nc, opt.ngf, opt.netG, opt.norm, not opt.no_dropout, opt.init_type, opt.init_gain, self.gpu_ids)
if self.isTrain: # define discriminators
self.netD_A = networks.define_D(opt.output_nc, opt.ndf, opt.netD,
opt.n_layers_D, opt.norm, opt.init_type, opt.init_gain, self.gpu_ids)
self.netD_B = networks.define_D(opt.input_nc, opt.ndf, opt.netD,
opt.n_layers_D, opt.norm, opt.init_type, opt.init_gain, self.gpu_ids)
生成器的网络架构主要通过models/networks里面的define_G函数进行初始化,G_A与G_B构造一样。
判别器的网络架构主要通过define_D函数进行初始化,D_A与D_B也一样。
networks.py: define_G
def define_G(input_nc, output_nc, ngf, netG, norm='batch', use_dropout=False, init_type='normal', init_gain=0.02, gpu_ids=[]):
"""Create a generator
Parameters:
input_nc (int) -- the number of channels in input images
output_nc (int) -- the number of channels in output images
ngf (int) -- the number of filters in the last conv layer
netG (str) -- the architecture's name: resnet_9blocks | resnet_6blocks | unet_256 | unet_128
norm (str) -- the name of normalization layers used in the network: batch | instance | none
use_dropout (bool) -- if use dropout layers.
init_type (str) -- the name of our initialization method.
init_gain (float) -- scaling factor for normal, xavier and orthogonal.
gpu_ids (int list) -- which GPUs the network runs on: e.g., 0,1,2
Returns a generator
Our current implementation provides two types of generators:
U-Net: [unet_128] (for 128x128 input images) and [unet_256] (for 256x256 input images)
The original U-Net paper: https://arxiv.org/abs/1505.04597
Resnet-based generator: [resnet_6blocks] (with 6 Resnet blocks) and [resnet_9blocks] (with 9 Resnet blocks)
Resnet-based generator consists of several Resnet blocks between a few downsampling/upsampling operations.
We adapt Torch code from Justin Johnson's neural style transfer project (https://github.com/jcjohnson/fast-neural-style).
The generator has been initialized by . It uses RELU for non-linearity.
"""
net = None
norm_layer = get_norm_layer(norm_type=norm)
if netG == 'resnet_9blocks':
net = ResnetGenerator(input_nc, output_nc, ngf, norm_layer=norm_layer, use_dropout=use_dropout, n_blocks=9)
elif netG == 'resnet_6blocks':
net = ResnetGenerator(input_nc, output_nc, ngf, norm_layer=norm_layer, use_dropout=use_dropout, n_blocks=6)
elif netG == 'unet_128':
net = UnetGenerator(input_nc, output_nc, 7, ngf, norm_layer=norm_layer, use_dropout=use_dropout)
elif netG == 'unet_256':
net = UnetGenerator(input_nc, output_nc, 8, ngf, norm_layer=norm_layer, use_dropout=use_dropout)
else:
raise NotImplementedError('Generator model name [%s] is not recognized' % netG)
return init_net(net, init_type, init_gain, gpu_ids)
networks.py: class ResnetGenerator(nn.Module)
以残差生成器为例,单个残差块的构造如下:残差块是带skip connection的卷积块。使用残差结构最大的优点是可以有效地缓解梯度消失的问题

class ResnetBlock(nn.Module):
"""Define a Resnet block"""
def __init__(self, dim, padding_type, norm_layer, use_dropout, use_bias):
"""Initialize the Resnet block
A resnet block is a conv block with skip connections
We construct a conv block with build_conv_block function,
and implement skip connections in function.
Original Resnet paper: https://arxiv.org/pdf/1512.03385.pdf
"""
super(ResnetBlock, self).__init__()
self.conv_block = self.build_conv_block(dim, padding_type, norm_layer, use_dropout, use_bias)
def build_conv_block(self, dim, padding_type, norm_layer, use_dropout, use_bias):
"""Construct a convolutional block.
Parameters:
dim (int) -- the number of channels in the conv layer.
padding_type (str) -- the name of padding layer: reflect | replicate | zero
norm_layer -- normalization layer
use_dropout (bool) -- if use dropout layers.
use_bias (bool) -- if the conv layer uses bias or not
Returns a conv block (with a conv layer, a normalization layer, and a non-linearity layer (ReLU))
"""
conv_block = []
p = 0
if padding_type == 'reflect':
conv_block += [nn.ReflectionPad2d(1)]
elif padding_type == 'replicate':
conv_block += [nn.ReplicationPad2d(1)]
elif padding_type == 'zero':
p = 1
else:
raise NotImplementedError('padding [%s] is not implemented' % padding_type)
conv_block += [nn.Conv2d(dim, dim, kernel_size=3, padding=p, bias=use_bias), norm_layer(dim), nn.ReLU(True)]
if use_dropout:
conv_block += [nn.Dropout(0.5)]
p = 0
if padding_type == 'reflect':
conv_block += [nn.ReflectionPad2d(1)]
elif padding_type == 'replicate':
conv_block += [nn.ReplicationPad2d(1)]
elif padding_type == 'zero':
p = 1
else:
raise NotImplementedError('padding [%s] is not implemented' % padding_type)
conv_block += [nn.Conv2d(dim, dim, kernel_size=3, padding=p, bias=use_bias), norm_layer(dim)]
return nn.Sequential(*conv_block)
def forward(self, x):
"""Forward function (with skip connections)"""
out = x + self.conv_block(x) # add skip connections
return outResnetBlock(nn.Module)
一个残差块的构造大致如下:
x → padding(reflect | replication | zero)→ conv2d → normalization layer (batch | instance | none) → Relu → conv2d → normalization layer (batch | instance | none) → x’
跳线连接 skip connections: forward 前向传播返回
![]()
看完残差块的构造后我们再来看整个生成器的构造:
class ResnetGenerator(nn.Module):
"""Resnet-based generator that consists of Resnet blocks between a few downsampling/upsampling operations.
We adapt Torch code and idea from Justin Johnson's neural style transfer project(https://github.com/jcjohnson/fast-neural-style)
"""
def __init__(self, input_nc, output_nc, ngf=64, norm_layer=nn.BatchNorm2d, use_dropout=False, n_blocks=6, padding_type='reflect'):
"""Construct a Resnet-based generator
Parameters:
input_nc (int) -- the number of channels in input images
output_nc (int) -- the number of channels in output images
ngf (int) -- the number of filters in the last conv layer
norm_layer -- normalization layer
use_dropout (bool) -- if use dropout layers
n_blocks (int) -- the number of ResNet blocks
padding_type (str) -- the name of padding layer in conv layers: reflect | replicate | zero
"""
assert(n_blocks >= 0)
super(ResnetGenerator, self).__init__()
if type(norm_layer) == functools.partial:
use_bias = norm_layer.func == nn.InstanceNorm2d
else:
use_bias = norm_layer == nn.InstanceNorm2d
model = [nn.ReflectionPad2d(3),
nn.Conv2d(input_nc, ngf, kernel_size=7, padding=0, bias=use_bias),
norm_layer(ngf),
nn.ReLU(True)]
n_downsampling = 2
for i in range(n_downsampling): # add downsampling layers
mult = 2 ** i
model += [nn.Conv2d(ngf * mult, ngf * mult * 2, kernel_size=3, stride=2, padding=1, bias=use_bias),
norm_layer(ngf * mult * 2),
nn.ReLU(True)]
mult = 2 ** n_downsampling
for i in range(n_blocks): # add ResNet blocks
model += [ResnetBlock(ngf * mult, padding_type=padding_type, norm_layer=norm_layer, use_dropout=use_dropout, use_bias=use_bias)]
for i in range(n_downsampling): # add upsampling layers
mult = 2 ** (n_downsampling - i)
model += [nn.ConvTranspose2d(ngf * mult, int(ngf * mult / 2),
kernel_size=3, stride=2,
padding=1, output_padding=1,
bias=use_bias),
norm_layer(int(ngf * mult / 2)),
nn.ReLU(True)]
model += [nn.ReflectionPad2d(3)]
model += [nn.Conv2d(ngf, output_nc, kernel_size=7, padding=0)]
model += [nn.Tanh()]
self.model = nn.Sequential(*model)
def forward(self, input):
"""Standard forward"""
return self.model(input)
如代码所示,输入首先经过reflection padding,再经过一个conv2d, norm layer 和 Rule 的组合,然后进入下采样阶段——先后经过两个下采样模块(conv2d → norm layer → Relu),然后经过若干个残差块(6 | 9),随后进入上采样阶段——先后经过两个上采样模块,只不过将下采样模块中的conv2d换成反卷积操作convtranspose2d,最后在经过一次reflection padding,conv2d, 然后经过tanh得到最后输出。
整个架构为:
x → reflection padding → conv2d → Relu → down sampling → down sampling → resblock * n → up sampling → up sampling → reflection padding → conv2d → tanh → y
判别器的构造相对简单,以NLayerDiscriminator为例:
class NLayerDiscriminator(nn.Module):
"""Defines a PatchGAN discriminator"""
def __init__(self, input_nc, ndf=64, n_layers=3, norm_layer=nn.BatchNorm2d):
"""Construct a PatchGAN discriminator
Parameters:
input_nc (int) -- the number of channels in input images
ndf (int) -- the number of filters in the last conv layer
n_layers (int) -- the number of conv layers in the discriminator
norm_layer -- normalization layer
"""
super(NLayerDiscriminator, self).__init__()
if type(norm_layer) == functools.partial: # no need to use bias as BatchNorm2d has affine parameters
use_bias = norm_layer.func == nn.InstanceNorm2d
else:
use_bias = norm_layer == nn.InstanceNorm2d
kw = 4
padw = 1
sequence = [nn.Conv2d(input_nc, ndf, kernel_size=kw, stride=2, padding=padw), nn.LeakyReLU(0.2, True)]
nf_mult = 1
nf_mult_prev = 1
for n in range(1, n_layers): # gradually increase the number of filters
nf_mult_prev = nf_mult
nf_mult = min(2 ** n, 8)
sequence += [
nn.Conv2d(ndf * nf_mult_prev, ndf * nf_mult, kernel_size=kw, stride=2, padding=padw, bias=use_bias),
norm_layer(ndf * nf_mult),
nn.LeakyReLU(0.2, True)
]
nf_mult_prev = nf_mult
nf_mult = min(2 ** n_layers, 8)
sequence += [
nn.Conv2d(ndf * nf_mult_prev, ndf * nf_mult, kernel_size=kw, stride=1, padding=padw, bias=use_bias),
norm_layer(ndf * nf_mult),
nn.LeakyReLU(0.2, True)
]
sequence += [nn.Conv2d(ndf * nf_mult, 1, kernel_size=kw, stride=1, padding=padw)] # output 1 channel prediction map
self.model = nn.Sequential(*sequence)
def forward(self, input):
"""Standard forward."""
return self.model(input)
整个架构如下:
*x → n (conv2d → norm_layer → LeakyRelu) → conv2d → norm_layer → LeakyRelu → conv2d → y
整个网络的前向传播:
def forward(self):
"""Run forward pass; called by both functions and ."""
self.fake_B = self.netG_A(self.real_A) # G_A(A)
self.rec_A = self.netG_B(self.fake_B) # G_B(G_A(A))
self.fake_A = self.netG_B(self.real_B) # G_B(B)
self.rec_B = self.netG_A(self.fake_A) # G_A(G_B(B))
回到train.py,查看代码是利用生成器与判别器计算损失的
train.py
for epoch in range(opt.epoch_count, opt.n_epochs + opt.n_epochs_decay + 1): # outer loop for different epochs; we save the model by , +
epoch_start_time = time.time() # timer for entire epoch
iter_data_time = time.time() # timer for data loading per iteration
epoch_iter = 0 # the number of training iterations in current epoch, reset to 0 every epoch
visualizer.reset() # reset the visualizer: make sure it saves the results to HTML at least once every epoch
model.update_learning_rate() # update learning rates in the beginning of every epoch.
for i, data in enumerate(dataset): # inner loop within one epoch
iter_start_time = time.time() # timer for computation per iteration
if total_iters % opt.print_freq == 0:
t_data = iter_start_time - iter_data_time
total_iters += opt.batch_size
epoch_iter += opt.batch_size
model.set_input(data) # unpack data from dataset and apply preprocessing
model.optimize_parameters() # calculate loss functions, get gradients, update network weights
发现optimize_parameters()是负责计算损失函数的,该方法继承自class BaseModel,我们来分析一下,该抽象方法在class CycleGANModel中的复写方法,代码如下:
cycle_gan_model.py: class CycleGANModel(BaseModel)
def optimize_parameters(self):
"""Calculate losses, gradients, and update network weights; called in every training iteration"""
# forward
self.forward() # compute fake images and reconstruction images.
# G_A and G_B
self.set_requires_grad([self.netD_A, self.netD_B], False) # Ds require no gradients when optimizing Gs
self.optimizer_G.zero_grad() # set G_A and G_B's gradients to zero
self.backward_G() # calculate gradients for G_A and G_B
self.optimizer_G.step() # update G_A and G_B's weights
# D_A and D_B
self.set_requires_grad([self.netD_A, self.netD_B], True)
self.optimizer_D.zero_grad() # set D_A and D_B's gradients to zero
self.backward_D_A() # calculate gradients for D_A
self.backward_D_B() # calculate graidents for D_B
self.optimizer_D.step() # update D_A and D_B's weights
其中**set_requires_grad()**方法负责设置判别器和生成器中的参数是否需要记录梯度,这里生成器不需要记录的原因是,生成器的进化只依赖于判别器给生成器的反馈与判别器的参数无关。
def set_requires_grad(self, nets, requires_grad=False):
"""Set requies_grad=Fasle for all the networks to avoid unnecessary computations
Parameters:
nets (network list) -- a list of networks
requires_grad (bool) -- whether the networks require gradients or not
"""
if not isinstance(nets, list):
nets = [nets]
for net in nets:
if net is not None:
for param in net.parameters():
param.requires_grad = requires_grad
backward_G()负责计算G_A和G_B的loss

总共有三种loss:
Identity loss(选用)
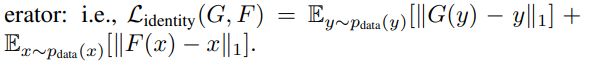
GAN Loss:

Cycle Loss:

ambda_A:weight for cycle loss (A -> B -> A) A方向重建损失权重
lambda_B:weight for cycle loss (B -> A -> B) B方向重建损失权重
lambda_identity:identity loss相对于cycle loss的比例
通过判断lambda_idt是否大于0,来判断当前实验是否计算Identity Loss
def backward_G(self):
"""Calculate the loss for generators G_A and G_B"""
lambda_idt = self.opt.lambda_identity
lambda_A = self.opt.lambda_A
lambda_B = self.opt.lambda_B
# Identity loss
if lambda_idt > 0:
# G_A should be identity if real_B is fed: ||G_A(B) - B||
self.idt_A = self.netG_A(self.real_B)
self.loss_idt_A = self.criterionIdt(self.idt_A, self.real_B) * lambda_B * lambda_idt
# G_B should be identity if real_A is fed: ||G_B(A) - A||
self.idt_B = self.netG_B(self.real_A)
self.loss_idt_B = self.criterionIdt(self.idt_B, self.real_A) * lambda_A * lambda_idt
else:
self.loss_idt_A = 0
self.loss_idt_B = 0
# GAN loss D_A(G_A(A))
self.loss_G_A = self.criterionGAN(self.netD_A(self.fake_B), True)
# GAN loss D_B(G_B(B))
self.loss_G_B = self.criterionGAN(self.netD_B(self.fake_A), True)
# Forward cycle loss || G_B(G_A(A)) - A||
self.loss_cycle_A = self.criterionCycle(self.rec_A, self.real_A) * lambda_A
# Backward cycle loss || G_A(G_B(B)) - B||
self.loss_cycle_B = self.criterionCycle(self.rec_B, self.real_B) * lambda_B
# combined loss and calculate gradients
self.loss_G = self.loss_G_A + self.loss_G_B + self.loss_cycle_A + self.loss_cycle_B + self.loss_idt_A + self.loss_idt_B
self.loss_G.backward()
三项损失的计算方法在**_init_()时已经被调用了,GAN Loss调用了networks.py的中的class GANLoss**,其他两项皆为L1损失函数。
self.criterionGAN = networks.GANLoss(opt.gan_mode).to(self.device) # define GAN loss.
self.criterionCycle = torch.nn.L1Loss()
self.criterionIdt = torch.nn.L1Loss()
networks.py: class GANLoss(nn.Module)
首先,在**_init_()方法中有三种loss可以选择:lsgan,vanilla,wgangp。然后,使用register_buffer**(无需在反向传播中更新,因此用buffer创建,state_dict也会记录用buffer创建的参数)创建real label,fake label对应的tensor。随后在get_target_tensor()方法中将label tensor用expend_as扩展为和prediction一样shape的tensor,方便后续loss的计算。
class GANLoss(nn.Module):
"""Define different GAN objectives.
The GANLoss class abstracts away the need to create the target label tensor
that has the same size as the input.
"""
def __init__(self, gan_mode, target_real_label=1.0, target_fake_label=0.0):
""" Initialize the GANLoss class.
Parameters:
gan_mode (str) - - the type of GAN objective. It currently supports vanilla, lsgan, and wgangp.
target_real_label (bool) - - label for a real image
target_fake_label (bool) - - label of a fake image
Note: Do not use sigmoid as the last layer of Discriminator.
LSGAN needs no sigmoid. vanilla GANs will handle it with BCEWithLogitsLoss.
"""
super(GANLoss, self).__init__()
self.register_buffer('real_label', torch.tensor(target_real_label))
self.register_buffer('fake_label', torch.tensor(target_fake_label))
self.gan_mode = gan_mode
if gan_mode == 'lsgan':
self.loss = nn.MSELoss()
elif gan_mode == 'vanilla':
self.loss = nn.BCEWithLogitsLoss()
elif gan_mode in ['wgangp']:
self.loss = None
else:
raise NotImplementedError('gan mode %s not implemented' % gan_mode)
def get_target_tensor(self, prediction, target_is_real):
"""Create label tensors with the same size as the input.
Parameters:
prediction (tensor) - - tpyically the prediction from a discriminator
target_is_real (bool) - - if the ground truth label is for real images or fake images
Returns:
A label tensor filled with ground truth label, and with the size of the input
"""
if target_is_real:
target_tensor = self.real_label
else:
target_tensor = self.fake_label
return target_tensor.expand_as(prediction)
def __call__(self, prediction, target_is_real):
"""Calculate loss given Discriminator's output and grount truth labels.
Parameters:
prediction (tensor) - - tpyically the prediction output from a discriminator
target_is_real (bool) - - if the ground truth label is for real images or fake images
Returns:
the calculated loss.
"""
if self.gan_mode in ['lsgan', 'vanilla']:
target_tensor = self.get_target_tensor(prediction, target_is_real)
loss = self.loss(prediction, target_tensor)
elif self.gan_mode == 'wgangp':
if target_is_real:
loss = -prediction.mean()
else:
loss = prediction.mean()
return loss
作者虽然写了wgangp但好像并没有调用,可能是代码没有实现。
判别器计算损失更为简单,与此相差不大。
到此整个训练过程中最主要的部分就都分析完成了。