注意力机制 Attention模型 global attention 和 local attention
Attention model 可以应用在图像领域也可以应用在自然语言识别领域
本文讨论的Attention模型是应用在自然语言领域的Attention模型,本文以神经网络机器翻译为研究点讨论注意力机制,参考文献《Effective Approaches to Attention-based Neural Machine Translation》
这篇文章提出了两种Attention模型分类:global、local
首先我们先定义些概念,以免在之后的讨论中混淆,机器翻译中输入的语言我们称为source,输出的语言我们称为target
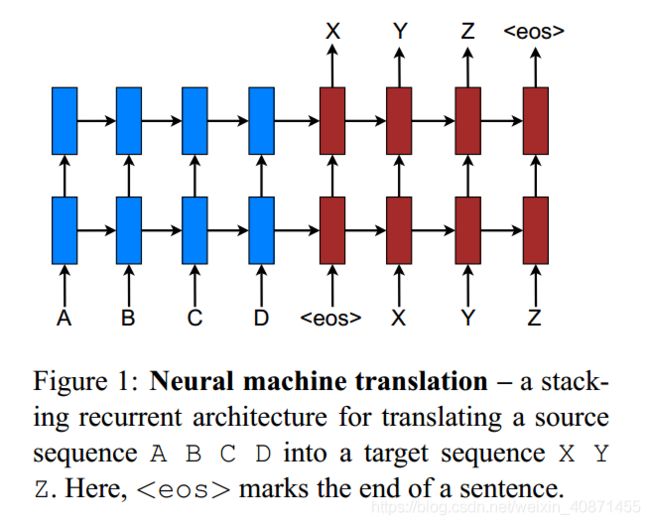
上图中A、B、C、D 是输入端称为source,X、Y、Z是输出端称为target,图中采用了两个RNN(循环神经网络),下边的称为编码器用于计算source的向量表示形式,上边的称为译码器,在每个时间步产生一个target单词,多个时间步之后就产生了一个句子,如果这里关于RNN、编码器和译码器不清楚,大家自行百度。
翻译模型就是在给定输入的情况下,算出每个单词输出的概率,即 p(y|x) x是source x1, . . . , xn, y是target sentence, y1, .. , ym
传统的target单词产生概率的计算定义为以下方式:
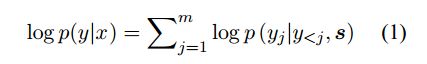
加 log 是为了防止每个概率直接相乘导致最后总的概率趋于0,s为source
这篇文章提出了一种概率计算方式:
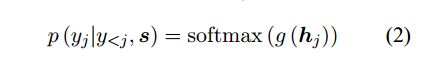
g是转换函数 输出的是一个向量,维度和词典中单词个数一样;hj 是RNN中隐层单元的输出值
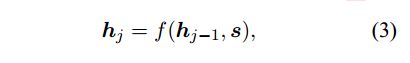
f 函数计算值hj是当前解码器RNN隐层节点的状态向量,输入和hj-1和s分别是前一时间步的隐层节点状态向量和source
这个神经网络的目标函数:
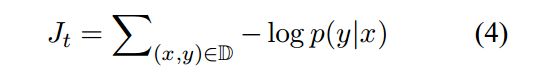
以上为准备阶段,接下来要讨论attention:
如果我们仔细观察,刚刚图一的上层蓝色的方块是没有输出的,实际上不是没有输出,而是在attention之前我们没有用到这个输出,所以就没有画上去,现在我们可以假设蓝色的方块上方也有向上的箭头,而attention模型就是要利用这些输出,attention认为这些信息反映了source的状态,我们利用这些状态在这些状态之上加一层attention层,让模型能注意到输入的状态,经过这个attention之后我们就获得的反映source的上下文信息。无论是global attention还是local attention在获取到source-side上下文信息(表示为 ct 向量)后就可以计算target的概率了。
我们把ct和ht拼接到一起,然后乘以一个参数矩阵,(这个矩阵是需要我们训练的)然后进行tanh运算后得到注意力隐层状态
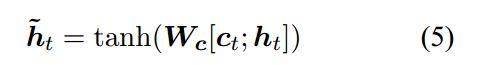
这里ht是decoder的隐层状态的输出,我们可以提前往下翻一下,看一下图二
target概率计算公式:
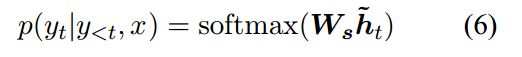
以上就是神经网络翻译模型计算每个单词输出概率的过程
然后我们来讨论注意力模型,
先看global attention
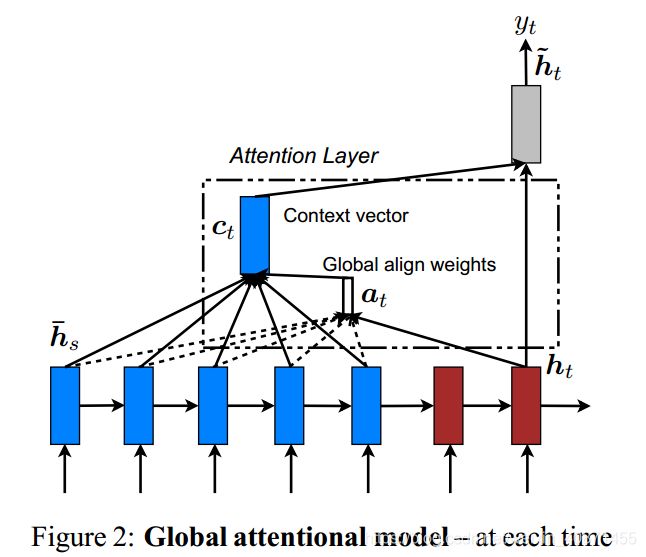
这里需要解释一下:这个图中的五个蓝框是encoder,两个红框是一个decoder,他们对应着图一的第一层(和X、Y、Z连着的那一层的蓝框和红框),也就是说我们这个图二下边还有一层,只是这个图没有画出来而已,从图中我们可以看到每个蓝色框都与ct相连,这就意味着所有的输入状态attention都可以监控到,所以名为global。αt是一个权重向量:
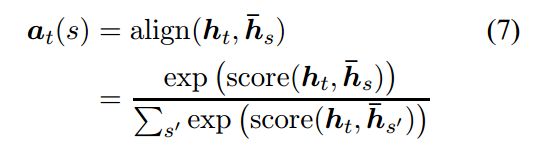
h-s 是每个蓝框的输出,所以对应到图中,每个蓝框h-s和ht进行一次 align() 操作,一共五次,所以α的维度是随着输入的source的字数的长度变化的,第二行中score函数可以定义如下:
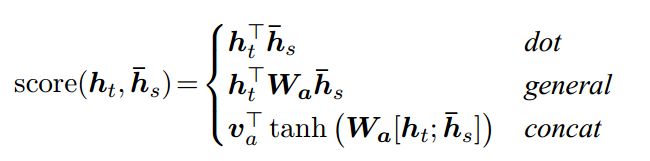
三个函数任选一个即可,最简单的选第一个,直接做一个点积操作得到一个实数。
至此我们就算出了权重αt,αt和h-s组成的向量进行点积得到了ct了
注意:
这些只是在一个ht下进行的操作,在图中表现为第二个红色的框框计算出来的ct向量,然后ct和第二个红框ht拼接之后才可以计算第二target单词概率(公式5和公式6);然后再选第三个红框,计算这个ht下对应的 αt ,然后再计算第三个target概率,一直往下,知道算到这个输出为
然后我们来看local attention
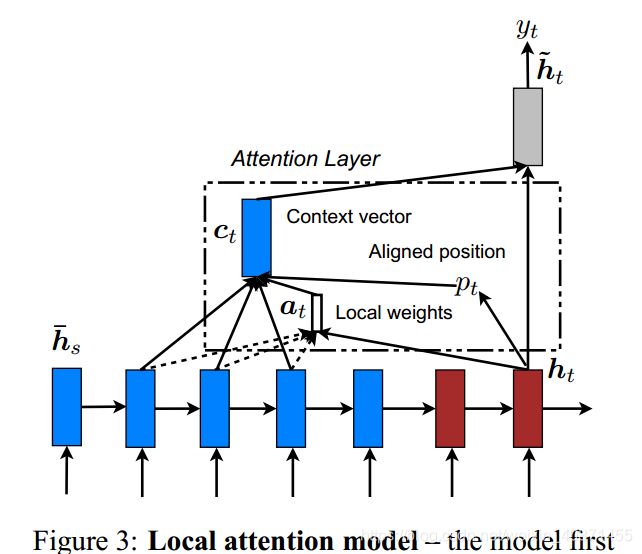
不同于global,local顾名思义就是取了一部分的hidden state,如图三,五个蓝色框我们不全部都做attention,而是根据每次输出的target的ht来选取一段,比如:第二个红色ht选择中间的三个蓝色框框在其上做attention,首先我们需要解决怎么选择蓝色框框这个问题,确定了位置才能做attention
我们这里介绍一种方法:predictive alignment
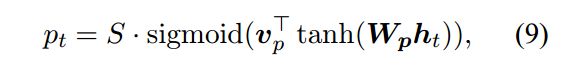
vp和wp为训练参数,sigmoid为输出为0-1之间的实数,S为蓝色框框的数量,相乘正好就是一个正整数位置pt,然后在pt前取D个,在pt后取D个,加起来就是2D+1个,这就是local attention的窗口。
然后我们来看权重αt怎么确定,由于窗口大小是确定的,所以αt的维度是确定的,这点和global不一样,
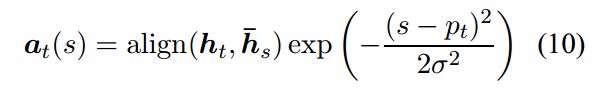
align函数和global的align函数一样,exp(*) 是一个高斯分布,σ=D/2,s是一个在pt为中心的窗口内的位置参数
这样我们有了αt,有了h-s,就可以得到ct;有了ct后面就可以计算概率了,同样,这只是在某个target对应的ht下的计算出来的单词的概率,后面需要继续根据ht往后移动,选择新的窗口计算新的ct,得出新的target概率,直到得出结束标志

图四是为了提高准确率,将前一步得出的target,作为输入,输入到下一步target预测的计算中,这其中的道理就是在翻译时,已经翻译过的单词,就不需要再一次出现了,所以将其再次输入,告诉模型这个参数后面不需要了,或者减少之后这个单词出现的概率。
至此,神经网络翻译中的attention模型就介绍完了