利用LSTM对一维销量数据进行销量预测(内附数据集)
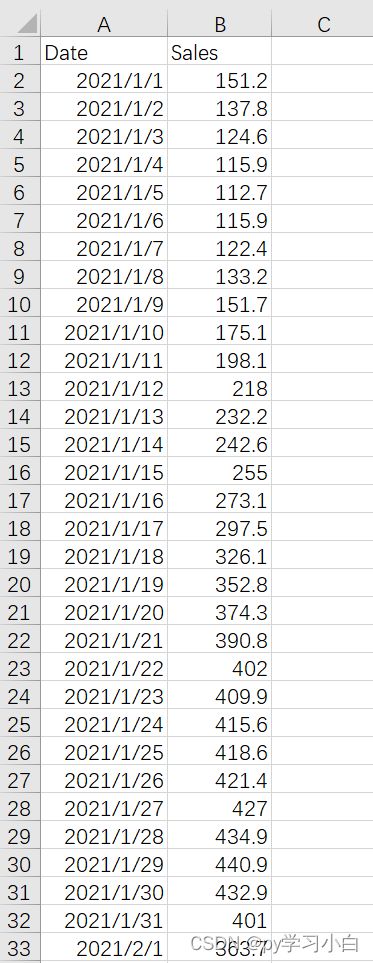
1、数据概况
数据十分简单,就只有日期,以及对应的销量。
2、代码
本次我使用jupyter notebook 来整,,主要是可以更方便的看出每组代码的输出结果。代码如下,
#导入相关库
import numpy
import matplotlib.pyplot as plt
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import LSTM
import pandas as pd
import os
from keras.models import Sequential, load_model
from sklearn.metrics import mean_absolute_error, mean_squared_error, r2_score
from sklearn.preprocessing import MinMaxScaler然后进行数据导入和相关处理
dataframe = pd.read_csv(r"D:\桌面文件夹哦\数据统计\悠度数据\2特征.CSV", usecols=[1], engine='python', skipfooter=3)
dataset = dataframe.values
# 将整型变为float
dataset = dataset.astype('float32')
#归一化
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset)
train_size = int(len(dataset) * 0.80)
trainlist = dataset[:train_size]
testlist = dataset[train_size:]定义一个划分测试集和训练集的函数
def create_dataset(dataset, look_back):
#这里的look_back与timestep相同
dataX, dataY = [], []
for i in range(len(dataset)-look_back-1):
a = dataset[i:(i+look_back)]
dataX.append(a)
dataY.append(dataset[i + look_back])
return numpy.array(dataX),numpy.array(dataY)
#训练数据太少 look_back并不能过大
look_back = 1
trainX,trainY = create_dataset(trainlist,look_back)
testX,testY = create_dataset(testlist,look_back)
trainX = numpy.reshape(trainX, (trainX.shape[0], trainX.shape[1], 1))
testX = numpy.reshape(testX, (testX.shape[0], testX.shape[1] ,1 ))拟合并保存模型
# create and fit the LSTM network
model = Sequential()
model.add(LSTM(5, input_shape=(None,1)))
model.add(Dense(1))
model.compile(loss='mean_squared_error', optimizer='adam')
model.fit(trainX, trainY, epochs=100, batch_size=2, verbose=2)
model.save("D:\桌面文件夹哦\预测模型保存")#模型保存位置加载保存好的模型,进行测试(将训练集,测试集数据输入,输出对应预测结果,对输出的结果进行反归一化,再与真实的训练测试数据进行对比)
model = load_model(r"D:\桌面文件夹哦\预测模型保存")
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)
#反归一化
trainPredict = scaler.inverse_transform(trainPredict)
trainY = scaler.inverse_transform(trainY)
testPredict = scaler.inverse_transform(testPredict)
testY = scaler.inverse_transform(testY)将预测的结果与真实结果进行作图
plt.plot(trainY)
plt.plot(trainPredict[1:])
plt.show()
plt.plot(testY)
plt.plot(testPredict[1:])
plt.show()
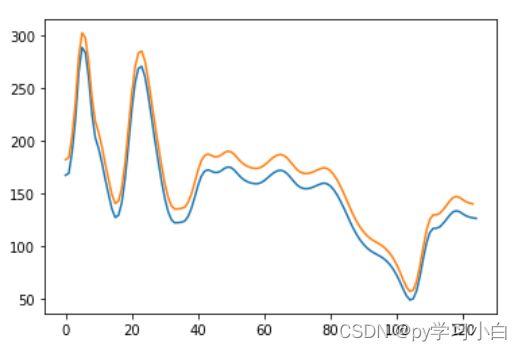 测试集预测结果(蓝色为真实数据,橙色为预测数据)
测试集预测结果(蓝色为真实数据,橙色为预测数据)
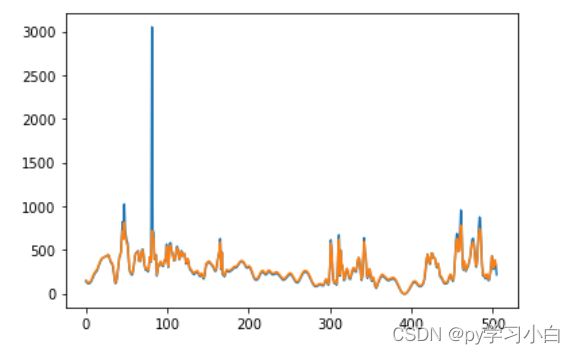 训练集预测结果
训练集预测结果
最后用r2、rmse等指标来衡量预测结果
r_2 = r2_score(testPredict,testY)
print('Test r_2: %.3f' % r_2)
# 计算MAE
mae = mean_absolute_error(testPredict,testY)
print('Test MAE: %.3f' % mae)
# 计算RMSE
from math import sqrt
rmse = sqrt(mean_squared_error(testPredict,testY))
print('Test RMSE: %.3f' % rmse)预测结果如下

拟合的还行,误差也比较小。
数据集如下(永久有效)
链接:https://pan.baidu.com/s/1VGWpGuNM4PUVzoULaCUyGA
提取码:zxt1