Pytorch梯度下降和和反向传播
目录
1. 向前计算
1.1 计算过程
1.2 requires_grad和grad_fn
2 梯度计算
1. 向前计算
对于pytorch中的一个tensor,如果设置它的属性,requires_grad为True,那么它将会追踪对于该张量的所有操作。
1.1 计算过程
假设有以下条件(1/4表示均值,xi中有四个数),使用torch完成其向前计算的过程
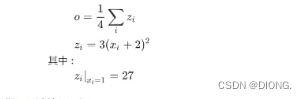
如果x为参数,需要对其进行梯度的计算和更新,所以在最开始随机设置x的值的过程中,需要设置他的requires_grad属性为True,其默认为False
下述代码 1. x的requires_grad属性True
2. 之后的每次计算都会修改grad_fn属性,用来记录做过的操作
1.通过这个函数和grad_fn能够组成一个和前一小节类似的计算图
import torch # 创建全为1的tensor,requires_grad=True的作用就是用来追踪其计算历史 x = torch.ones(2,2,requires_grad=True) # 初始化参数x并设置 print(x)# tensor([[1., 1.], # [1., 1.]], requires_grad=True) y = x + 2 """ grad_fn=的作用 https://www.cnblogs.com/picassooo/p/13757403.html """ print(y) # tensor([[3., 3.], # [ 3., 3.]], grad_fn=) 表示相加 z = y*y*3 print(z) out = z.mean() #求平均值 print(out) # tensor(27., grad_fn= )
1.2 requires_grad和grad_fn
下述代码中with torch.no_grad():可以有效解决跟踪历史记录(和使用内存),在评估模型中很有用
# 创建一个两行两列的张量,其服从正态分布 a = torch.randn(2,2) a = ((a * 3) / (a - 1)) print(a.requires_grad) # False a.requires_grad_(True) # 就地修改 print(a.requires_grad) # True b = (a*a).sum() print(b.grad_fn) ## 不想让grad去记录每次的使用情况可以这样 with torch.no_grad(): c = (a*a).sum() print(c.requires_grad) #False print(c.grad_fn) # None
2. 梯度计算
对于1.1中获得的out,可以使用backward方法来进行反向传播,计算梯度out.backward(),此时调用x.gard能够获取导数值得到
out.backward()
print(x.grad)#tensor([[4.5000, 4.5000],
# [4.5000, 4.5000]])很多情况下损失函数都是一个标量,所以这里就不在介绍损失为向量的情况。
loss.backward()就是根据损失函数,对参数去计算他的梯度,并且把他累加保存到x.gard,此时还未更新其梯度。
注意点:
1. tensor.data:
a. 在tensor的require_grad=False,tensor.data和tensor等价
b. require_grad=True时,tensor.data仅仅是获取tensor中的数据
2.tensor.numpy():
require_grad=True不能够直接转换,需要使用tensor.detach().numpy()
可以看如下代码了解注意点:
print(a) # tensor([[ 1.4489, 0.2289],
# [ 0.6411, 14.3347]], requires_grad=True)
print(a.data)# tensor([[ 1.4489, 0.2289],
# [ 0.6411, 14.3347]])
# 将a转换成numpy
b = a.detach().numpy()
print(b) #[[ 0.6715026 -0.44541362]
# [ 0.82781005 1.735428 ]]