【论文笔记】强化学习策略梯度(PG)专题经典论文8篇
文章目录
-
- 引子
- Asynchronous Methods for Deep Reinforcement Learning, Mnih et al, 2016. Algorithm: A3C.
- Trust Region Policy Optimization, Schulman et al, 2015. Algorithm: TRPO.
- High-Dimensional Continuous Control Using Generalized Advantage Estimation, Schulman et al, 2015. Algorithm: GAE.
- Proximal Policy Optimization Algorithms, Schulman et al, 2017. Algorithm: PPO-Clip, PPO-Penalty.
- Emergence of Locomotion Behaviours in Rich Environments, Heess et al, 2017. Algorithm: PPO-Penalty.
- Scalable trust-region method for deep reinforcement learning using Kronecker-factored approximation, Wu et al, 2017. Algorithm: ACKTR.
- Sample Efficient Actor-Critic with Experience Replay, Wang et al, 2016. Algorithm: ACER.
- Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor, Haarnoja et al, 2018. Algorithm: SAC.
- 结语
引子
Asynchronous Methods for Deep Reinforcement Learning, Mnih et al, 2016. Algorithm: A3C.

论文将基于值与基于策略两种方式结合,与其学习动作价值,不如直接学习动作的优势值,于是有A(s,a) = Q(s,a) - V(S)
论文的思路也很容易理解,就是在A2C的基础上加上了异步、集成多个A2C的学习经验。A2C结构如下图。
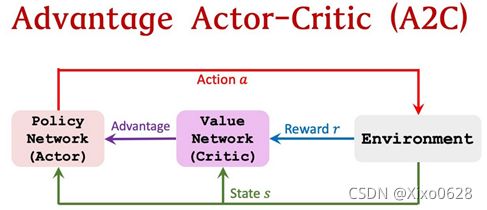
这图的含义是,根据环境给出的s和r,神经网络由Critic直接学习动作的优势值(AC方法是直接学习动作的价值),用来评估actor的行为。
在这张图中,中央就是大脑,然后下面每一个worker就是一个A2C。中央集成了所有A2C训练得到的经验。
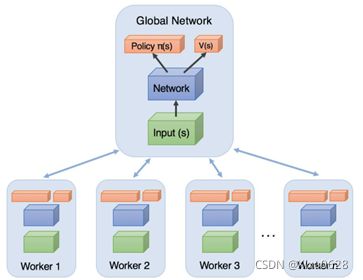
使用异步的优势就是减少了数据之间的相关性,每一个worker提供的训练数据其实都可以理解成互相之间都不相关的数据。最后A3C因为其出色的效果,成了一个非常有名、而且成熟的强化学习训练方式。
Trust Region Policy Optimization, Schulman et al, 2015. Algorithm: TRPO.
用数学技巧解决优化问题。

思想很直接,最大化新旧回报差值
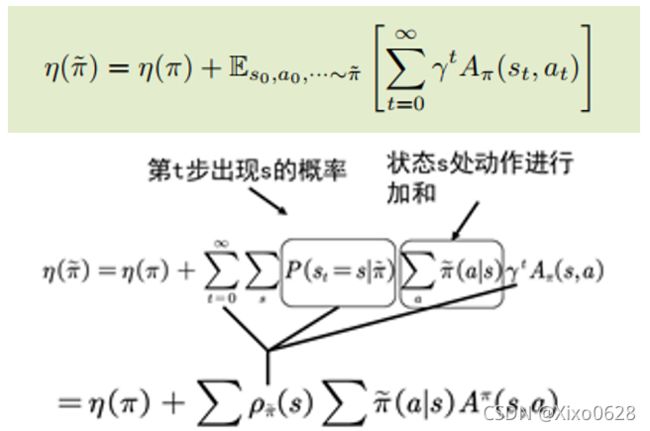
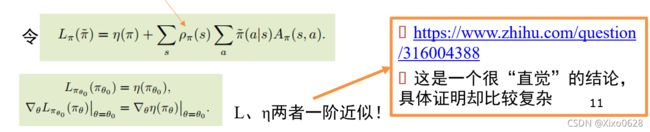
这里适合用一张图来说明两者的关系:
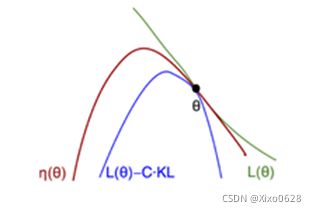
即两个函数在该点连续且一阶微分相等。
接下来结合另外一个定理:

于是得到了最终的优化目标:
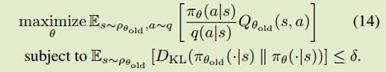
得到最终优化目标后,接下来就是利用采样得到数据,然后求样本均值,解决优化问题即可。
High-Dimensional Continuous Control Using Generalized Advantage Estimation, Schulman et al, 2015. Algorithm: GAE.

策略梯度估计方式有很多种。文中列举了6种,然后说明使用优势梯度可以减少方差、加快收敛。
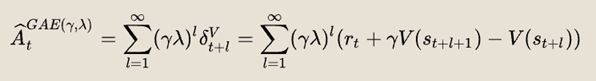
提出了一种计算广义策略梯度的方法,这思想其实类似从TD(0)到TD(λ)的拓展。
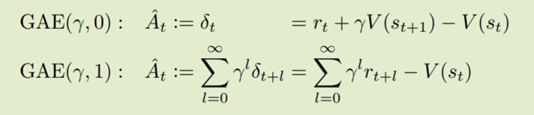
我个人的理解就是把优势估计的方式和Q-learning里TD的方法结合了一下。
后面的实验作者就是把GAE用在了TRPO上面,事实上GAE版本的TRPO和PPO已经是baselines里面的标准版本了。
Proximal Policy Optimization Algorithms, Schulman et al, 2017. Algorithm: PPO-Clip, PPO-Penalty.

可以看成是一种更加容易实现的TRPO,两者效果差不多。

上面一个式子就是TRPO的优化目标,把KL散度当作是约束条件,非常难以计算。下面就是把KL散度放进优化目标里,加上了惩罚项系数。
论文后面还介绍了Clip,Penalty两种计算优化目标的方式。不作赘述。
Clip:
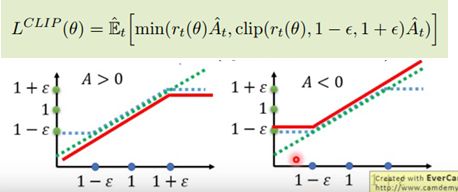
Penalty,系数可以自适应调整。

Emergence of Locomotion Behaviours in Rich Environments, Heess et al, 2017. Algorithm: PPO-Penalty.

丰富的环境促进复杂行为的学习,使用分布式PPO训练agent
在不同的复杂环境中训练,使用简单的奖励函数,在各个环境中都几乎一致。(文中提到就是向右)
虚拟人物学习在没有明确的基于奖励的指导,根据所处环境跑动、跳跃,蹲伏和转弯。效果很好地学到了各种动作。

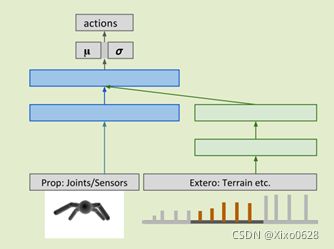
网络结构大致如下:
蓝色就是agent本体的大脑,绿色就是在不同环境中学到的信息,然后不断地换环境,把信息集中到agent中,感觉有A3C分布式学习那味道。
Scalable trust-region method for deep reinforcement learning using Kronecker-factored approximation, Wu et al, 2017. Algorithm: ACKTR.

一句话概括就是:使用自然梯度替代掉原来的梯度。
通过使用更高效的梯度更新算法来更新网络的参数,减少对样本量的需求。
因为欧式空间的度量参数变化的方式无法体现出参数变化引起的概率属性的变化量,自然梯度恰好可以。
主要贡献:将natural gradient和Kronecker-factored应用到了actor-critic的参数更新上。
Sample Efficient Actor-Critic with Experience Replay, Wang et al, 2016. Algorithm: ACER.
Off-policy actor-critic + 神经网络
在2012年文章的基础上,加上了神经网络。Degris, Thomas, Martha White, and Richard S. Sutton. "Off-policy actor-critic.“ arXiv preprint arXiv:1205.4839(2012). https://arxiv.org/pdf/1205.4839.pdf
这篇文章思想很简单,文章标题的是idea。用replay buffer的代价就是off-policy,然后在AC中off-policy的方式就是Sutton2012年的论文。
还有一个新东西,就是重要度裁剪的系数有界性证明,大概意思是把ρt连乘这个可能趋于无穷的项,拆分成两项之和,两项的系数都是有界的。(一项不大于c,一项不大于1)
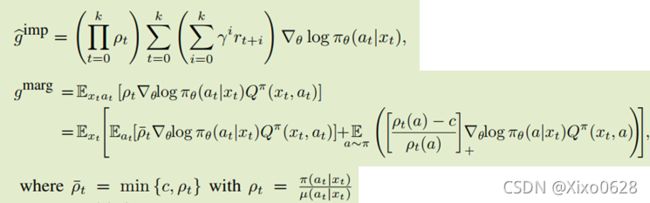
Soft Actor-Critic: Off-Policy Maximum Entropy Deep Reinforcement Learning with a Stochastic Actor, Haarnoja et al, 2018. Algorithm: SAC.
文章说的很高大上,其实思想朴素,就是让动作不要太快收敛,要多探索探索。

为了实现idea,就给动作策略的评价标准加上了一个策略的熵的惩罚。意思是希望策略尽可能地多样化。
通过改变强化学习的目标,可以实际性提升探索性和鲁棒性。值得一提的是这个Critic评价的也不只是状态的价值了,评价内容里也包含了熵这个标准(因为是神经网络拟合的嘛)。
实现了sample efficient(off-policy)和robust(maximum entropy framework)两个目标。并且由于求到的policy gradient里面有关于当前策略的期望,所以只要V值是相对于当前策略的,那么Q值的目标也是相对于当前策略的。正确性得以保证。
结语
PG在强化学习发展中也有非常重要的地位。甚至我认为PG和Q-learning这种基于价值的方法完全并列,算是两座山头。而且由于基于策略的PG可以更好的适应高维、连续的空间和动作,所以这部分的研究也将会是重中之重。
水平有限,如有错漏烦请指点。
都看到这里了,就顺手点个赞吧~