iloc函数_pandas做数据处理经常用的函数(一)
1、index 操作
reset_index,重置DataFrame的索引,并使用默认索引。如果DataFrame有一个多索引,则此方法可以删除一个或多个级别。
import pandas as pd
import numpy as np
df = pd.DataFrame([('bird', 389.0),
('bird', 24.0),
('mammal', 80.5),
('mammal', np.nan)],
index=['falcon', 'parrot', 'lion', 'monkey'],
columns=('class', 'max_speed'))
#重置索引时,会将旧索引添加为列,并使用新的顺序索引:
df.reset_index(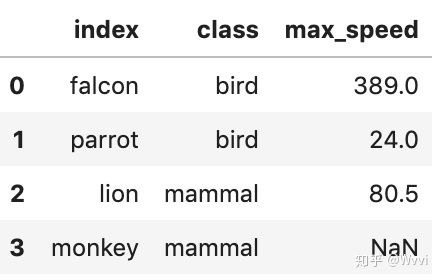
#我们可以使用drop参数来避免将旧索引添加为列
df.reset_index(drop=True)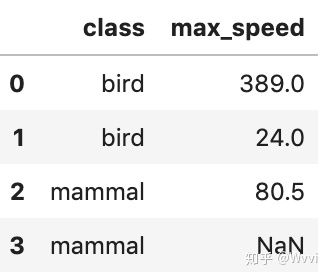
reindex,使用可选的填充逻辑设置DataFrame新索引
index = ['Firefox', 'Chrome', 'Safari', 'IE10', 'Konqueror']
df = pd.DataFrame({'http_status': [200, 200, 404, 404, 301],
'response_time': [0.04, 0.02, 0.07, 0.08, 1.0]},
index=index)
df
# 将新的列表序列作为索引
new_index = ['Safari', 'Iceweasel', 'Comodo Dragon', 'IE10',
'Chrome']
df.reindex(new_index)
set_index,使用现有列设置DataFrame索引
df = pd.DataFrame({'month': [1, 4, 7, 10],
'year': [2012, 2014, 2013, 2014],
'sale': [55, 40, 84, 31]})
df
df.set_index('month') 
2、映射操作
map,根据输入对应关系,输出Series映射值,该方法只能作用于Series
s = pd.Series(['cat', 'dog', np.nan, 'rabbit'])
s.map({'cat': 'kitten', 'dog': 'puppy'})0 kitten
1 puppy
2 NaN
3 NaN
dtype: object
apply用法与map差不多,但是其功能更加强大,Series、DataFrame都有此方法
df = pd.DataFrame([[4, 9]] * 3, columns=['A', 'B'])
df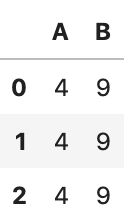
df.apply(np.sqrt) 
applymap,将函数应用于数据框的每个元素
df = pd.DataFrame([[1, 2.12], [3.356, 4.567]])
df 
df.applymap(lambda x: len(str(x)))
3、索引
iloc,主要是基于整数位置的(从轴的0到长度1)索引,但也可以与布尔数组一起使用。
mydict = [{'a': 1, 'b': 2, 'c': 3, 'd': 4},
{'a': 100, 'b': 200, 'c': 300, 'd': 400},
{'a': 1000, 'b': 2000, 'c': 3000, 'd': 4000 }]
df = pd.DataFrame(mydict)
df 
df.iloc[0, 1]
2
df.iloc[lambda x: x.index % 2 == 0]
loc,主要基于标签的索引,但也可以与布尔数组一起使用
df = pd.DataFrame([[1, 2], [4, 5], [7, 8]],
index=['cobra', 'viper', 'sidewinder'],
columns=['max_speed', 'shield'])
df 
df.loc['cobra', 'shield']
2
df.loc[lambda df: df['shield'] == 8] 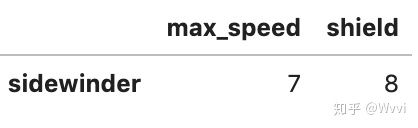
4、迭代
iterrows(),将DataFrame迭代为(insex, Series)
df = pd.DataFrame([[1, 1.5]], columns=['int', 'float'])
df
for index,col in df.iterrows():
print(index)0
#对于每一行可以通过列名访问对应的元素
for index,col in df.iterrows():
print(col['int'],col['float'])1.0 1.5
iteritems(),将DataFrame迭代为(列名, Series)对
df = pd.DataFrame({'species': ['bear', 'bear', 'marsupial'],
'population': [1864, 22000, 80000]},
index=['panda', 'polar', 'koala'])
df
for label, content in df.iteritems():
print(label)species
population
for label, content in df.iteritems():
print(content[0],content[1],content[2])bear bear marsupial
1864 22000 80000
itertuples(),将DataFrame迭代为元组
df = pd.DataFrame({'species': ['bear', 'bear', 'marsupial'],
'population': [1864, 22000, 80000]},
index=['panda', 'polar', 'koala'])
df
for row in df.itertuples(index=True):
print(row)Pandas(Index='panda', species='bear', population=1864)
Pandas(Index='polar', species='bear', population=22000)
Pandas(Index='koala', species='marsupial', population=80000)
for row in df.itertuples(index=True):
print(row[0:3])('panda', 'bear', 1864)
('polar', 'bear', 22000)
('koala', 'marsupial', 80000)
getattr(row, 'species')'marsupial'本文参考:官方文档
pandas documentationpandas.pydata.org