端到端的3D点云目标检测:Complex-YOLO(一)———KITTI数据集解析
博主最近一直都在看3D点云目标检测,且有一个可视化课设要结,还有一个CV课设,太酸爽了。
搜了一些paper,发现3D点云目标检测论文都不带公开源码的,GitHub上找项目配置来配置去总是会报一系列的错误,比如我上一个博客想要把CenterPoint跑起来,结果夭折了,配了半天(且把办公室的电脑重装了n遍系统),最终还是放弃了,毕竟玩不懂nuScenes数据集。
BUT!!!
带YOLO字眼的检测项目简直就是正道的光啊!!而且KITTI数据集明显更容易分析~
那就开始我们的3D点云检测之旅吧。
文章目录
- 3D点云目标检测算法历程简介
-
- 2-stage vs 1-stage
- point-based、voxel-based & fusing method
- KITTI数据集
-
- 数据集下载
- 数据采集介绍
- 数据集文件具体介绍
-
- image_2
- velodyne
- calib
- label
- References
3D点云目标检测算法历程简介
2-stage vs 1-stage
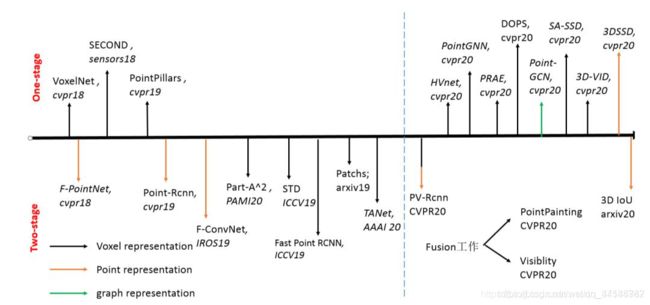
- 根据对于2D目标检测的改进,3D点云目标检测大体上也可以分为1-stage和2-stage两种,和2D目标检测一样,2-stage的算法一般更加准确,但是在速度上不如1-stage算法。可以看出,最近的3D目标检测工作也大多数是建立在1-stage检测算法上的,毕竟real-time对于自动驾驶来说更加重要!
- 18年的VoxelNet可以说是3D点云检测的开山鼻祖了,前两天想要配起来跑一下,但是发现代码所用的很多库都版本都比较旧,跑起来属实麻烦。
- 本次项目也将着重基于1-stage的3D点云检测算法来解决问题,端到端的方法yyds。
point-based、voxel-based & fusing method

- 上半部分主要是利用了图片以及激光雷达(fusing method)作为输入,例如F-PointNet网络先从2D图片上检测出目标,然后投影到3D点云中。但是这种方法存在遮挡等问题。
- 然后下半部分是仅仅利用了激光雷达的点云作为输入,其中同理分为两种类型,一是基于无规则的点云直接提取特征做检测即Point-based,另一种是Voxel-based(基于体素的),其主要先把无规则点云处理为有规则的,然后再提取特征。
- 这里注意的是AP主要是car的检测,再行人检测其没有还这么好的效果,因为很多物体和人比较相似所以误差较大。
- 所以博主将3D点云目标检测分了一下类:
- Lidar only, point-based method:直接输入点云数据给网络,或者将点云数据pre-process一下,如将三维点云投射到多个二维平面形成图像。Complex-yolo就是这类的,首先将点云数据转换到2d-bev图,然后在bev图上进行检测。
- Lidar only, voxel-based method:三维点云切割成多个小块,这些小块就叫体素,后期可以使用3D卷积像图像一样进行操作。我认为这种方法的计算量实在是太大了。so本项目不会尝试。
- Lidar + image,fusing method:多感知融合的方法,即有图片数据又有点云数据作为输入。我的理解是这样的:lidar only的方法再结合image检测的方法,最后将结果融合。结果会更准确一些?(如果融合的好的话),但毕竟多用了一个传感器(camera),计算量会更大。但实车一般都是多感知融合来解决问题吧。
- 我的想法是,主攻Lidar only, point-based method,因为他最容易达到real-time。融合的工作我觉得可以后期再进行处理:图像、激光雷达、毫米波雷达先分别得到结果,再利用算法来更全面得进行三者之间的融合。
KITTI数据集
数据集下载
- 下载KITTI http://www.cvlibs.net/datasets/kitti/eval_object.php?obj_benchmark=3d,去官网上下载,需要输一下邮箱号,然后会收到带有下载链接的邮件,下载速度还可以~只需要下载下面四个部分:
- left color images of object data set (12 GB) RGB图像.png
- Velodyne point clouds, if you want to use laser information (29 GB) 点云数据.bin
- camera calibration matrices of object data set (16 MB) 相机校准矩阵.txt
- training labels of object data set (5 MB) 训练标签.txt

- 3D目标检测数据集由7481个训练图像和7518个测试图像以及相应的点云数据组成,包括总共80256个标记对象。
- 其中彩色图像数据、点云数据、相机矫正数据均包含training(7481)和testing(7518)两个部分,标签数据只有training数据(testing的数据没有训练标签噢~~,用于test)
数据采集介绍
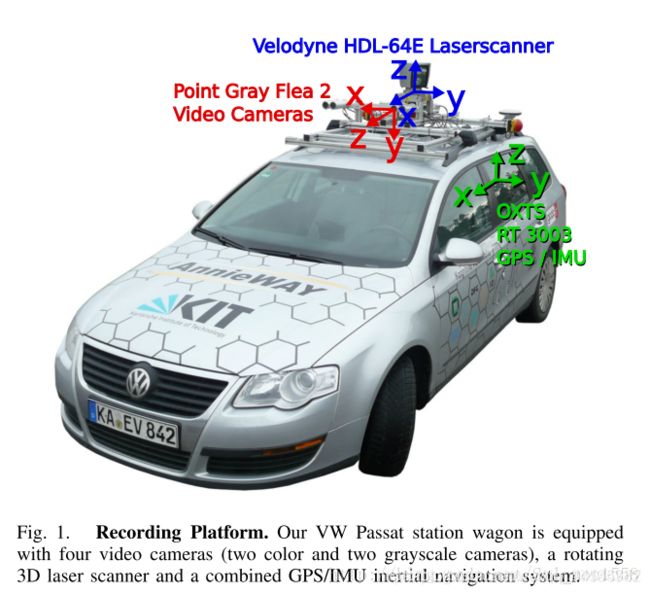
- KITTI数据集的数据采集平台装配有2个灰度摄像机,2个彩色摄像机,一个Velodyne 64线3D激光雷达,4个光学镜头,以及1个GPS导航系统。
- 为了生成双目立体图像,相同类型的摄像头相距54cm安装。由于彩色摄像机的分辨率和对比度不够好,所以还使用了两个立体灰度摄像机,它和彩色摄像机相距6cm安装。为了方便传感器数据标定,规定坐标系方向如下:
• Camera: x = right, y = down, z = forward
• Velodyne: x = forward, y = left, z = up
• GPS/IMU: x = forward, y = left, z = up

- 雷达采集数据时,是绕着竖直轴旋转扫描,只有当雷达旋转到与相机的朝向一致时会触发相机采集图像。不过在这里无需关注这一点,直接使用给出的同步且校准后的数据即可,它已将雷达数据与相机数据对齐,也就是可以认为同一文件名对应的图像数据与雷达点云数据属于同一个场景。
数据集文件具体介绍
image_2
- 相同文件名即相同场景,so如果要做连续的检测(多帧),把文件名设置好就行,然后多帧检测?(我目前的思路)

velodyne

- 数据格式:x y z intensity ; x,y,z单位为米,intensity为回波强度,范围在0~1.0之间。每位数由四位十六进制数表示(浮点数)


- 拿pycharm、gedit什么的读取文件都是乱码
- 这里使用了hexdump来读取,看一看数据长什么样子。
pip install hexdump
hexdump 000001.bin
- 可以对存储得点云数据进行可视化
import numpy as np
import mayavi.mlab
# 000010.bin这里需要填写文件的位置
pointcloud = np.fromfile(str("velodyne/000001.bin"), dtype=np.float32, count=-1).reshape([-1, 4])
print(pointcloud)
print(pointcloud.shape)
x = pointcloud[:, 0] # x position of point
y = pointcloud[:, 1] # y position of point
z = pointcloud[:, 2] # z position of point
r = pointcloud[:, 3] # reflectance value of point
d = np.sqrt(x ** 2 + y ** 2) # Map Distance from sensor
vals = 'height'
if vals == "height":
col = z
else:
col = d
fig = mayavi.mlab.figure(bgcolor=(0, 0, 0), size=(640, 500))
mayavi.mlab.points3d(x, y, z,
col, # Values used for Color
mode="point",
colormap='spectral', # 'bone', 'copper', 'gnuplot'
# color=(0, 1, 0), # Used a fixed (r,g,b) instead
figure=fig,
)
x = np.linspace(5, 5, 50)
y = np.linspace(0, 0, 50)
z = np.linspace(0, 5, 50)
mayavi.mlab.plot3d(x, y, z)
mayavi.mlab.show()

calib
calib主要和坐标系转换有关。
# 000001.txt calib文件中的内容
P0: 7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 0.000000000000e+00 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 0.000000000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 0.000000000000e+00
P1: 7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 -3.875744000000e+02 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 0.000000000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 0.000000000000e+00
P2: 7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 4.485728000000e+01 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 2.163791000000e-01 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 2.745884000000e-03
P3: 7.215377000000e+02 0.000000000000e+00 6.095593000000e+02 -3.395242000000e+02 0.000000000000e+00 7.215377000000e+02 1.728540000000e+02 2.199936000000e+00 0.000000000000e+00 0.000000000000e+00 1.000000000000e+00 2.729905000000e-03
R0_rect: 9.999239000000e-01 9.837760000000e-03 -7.445048000000e-03 -9.869795000000e-03 9.999421000000e-01 -4.278459000000e-03 7.402527000000e-03 4.351614000000e-03 9.999631000000e-01
Tr_velo_to_cam: 7.533745000000e-03 -9.999714000000e-01 -6.166020000000e-04 -4.069766000000e-03 1.480249000000e-02 7.280733000000e-04 -9.998902000000e-01 -7.631618000000e-02 9.998621000000e-01 7.523790000000e-03 1.480755000000e-02 -2.717806000000e-01
Tr_imu_to_velo: 9.999976000000e-01 7.553071000000e-04 -2.035826000000e-03 -8.086759000000e-01 -7.854027000000e-04 9.998898000000e-01 -1.482298000000e-02 3.195559000000e-01 2.024406000000e-03 1.482454000000e-02 9.998881000000e-01 -7.997231000000e-01
BEV space – bird eye view space 鸟瞰图空间
Each calibration file contains the following matrices (in row-major order):
P0 (3x4): Projection matrix for left grayscale camera in rectified coordinates 左边灰度相机的投影矩阵,坐标已修正
P1 (3x4): Projection matrix for right grayscale camera in rectified coordinates 右边灰度相机
P2 (3x4): Projection matrix for left color camera in rectified coordinates 左边彩色相机
P3 (3x4): Projection matrix for right color camera in rectified coordinates 右边彩色相机
R0_rect (3x3): Rotation from non-rectified to rectified camera coordinate system 从非矫正到矫正摄像机坐标系统的旋转
Tr_velo_to_cam (3x4): Rigid transformation from Velodyne to (non-rectified) camera coordinates 从Velodyne到(非矫正)相机坐标的刚性转换
Tr_imu_to_velo (3x4): Rigid transformation from IMU to Velodyne coordinates 从IMU到Velodyne坐标的刚性变换
Tr_cam_to_road (3x4): Rigid transformation from (non-rectified) camera to road coordinates 从(非矫正)摄像机到道路坐标的刚性变换,我下载的数据中没有这个矩阵变换。
具体的内容见如下笔记~博主是个喜欢五彩斑斓笔记的女孩子哈哈哈哈哈


label
000001.txt label内容
Truck 0.00 0 -1.57 599.41 156.40 629.75 189.25 2.85 2.63 12.34 0.47 1.49 69.44 -1.56
Car 0.00 0 1.85 387.63 181.54 423.81 203.12 1.67 1.87 3.69 -16.53 2.39 58.49 1.57
Cyclist 0.00 3 -1.65 676.60 163.95 688.98 193.93 1.86 0.60 2.02 4.59 1.32 45.84 -1.55
DontCare -1 -1 -10 503.89 169.71 590.61 190.13 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 511.35 174.96 527.81 187.45 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 532.37 176.35 542.68 185.27 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 559.62 175.83 575.40 183.15 -1 -1 -1 -1000 -1000 -1000 -10
每一行代表一个object,每一行都有16列分别表示不同的含义,具体如下:
- 第1列(字符串):代表物体类别(type)
总共有9类,分别是:Car、Van、Truck、Pedestrian、Person_sitting、Cyclist、Tram、Misc、DontCare。其中DontCare标签表示该区域没有被标注,比如由于目标物体距离激光雷达太远。为了防止在评估过程中(主要是计算precision),将本来是目标物体但是因为某些原因而没有标注的区域统计为假阳性(false positives),评估脚本会自动忽略DontCare区域的预测结果。 - 第2列(浮点数):代表物体是否被截断(truncated)
数值在0(非截断)到1(截断)之间浮动,数字表示指离开图像边界对象的程度。 - 第3列(整数):代表物体是否被遮挡(occluded)
整数0、1、2、3分别表示被遮挡的程度。 - 第4列(弧度数):物体的观察角度(alpha)
取值范围为:-pi ~ pi(单位:rad),它表示在相机坐标系下,以相机原点为中心,相机原点到物体中心的连线为半径,将物体绕相机y轴旋转至相机z轴,此时物体方向与相机x轴的夹角,如图1所示。

- 第5~8列(浮点数):物体的2D边界框大小(bbox)
四个数分别是xmin、ymin、xmax、ymax(单位:pixel),表示2维边界框的左上角和右下角的坐标。 - 第9~11列(浮点数):3D物体的尺寸(dimensions)分别是高、宽、长(单位:米)
- 第12-14列(整数):3D物体的位置(location)分别是x、y、z(单位:米),特别注意的是,这里的xyz是在相机坐标系下3D物体的中心点位置。
- 第15列(弧度数):3D物体的空间方向(rotation_y)取值范围为:-pi ~ pi(单位:rad),它表示,在照相机坐标系下,物体的全局方向角(物体前进方向与相机坐标系x轴的夹角),如图1所示。
- 第16列(整数):检测的置信度(score)要特别注意的是,这个数据只在测试集的数据中有。
References
- kitti数据集在3D目标检测中的入门
- Kitti road calib 对应的解释
- KITTI数据集–label解析与传感器间坐标转换参数解析