目标检测模型的评价指标 mAP
在使用机器学习解决实际问题时,通常有很多模型可用。每个模型都有自己的怪癖(quirks),并且基于各种因素,性能会有所不同。
模型性能的评定都是在某个数据集上进行的,通常这个数据集被称为 “validation 或 test” 数据集。模型性能的评价常用的指标有:accuracy、precision、recall等。这些指标的选择需要根据应用场景具体而定。对于特定应用,使用合适的评价指标来客观地比较不同模型的性能是非常重要的。
在本篇,我们将讨论目标检测问题中常用的评价指标 —– Mean Average Precision (mAP)。
-
- 1. 目标检测问题
- 2. 目标检测模型的评估
- 2.1 为什么选择 mAP ?
- 2.2 什么是 Ground Truth?
- 2.3 计算 mAP 的准备工作
- 2.3.1 什么是 IoU?
- 2.3.2 什么样的预测时正确的?怎么计算 precision 及 recall?
- 2.4 计算 mAP
- 2.4.1 使用 Pascal VOC 挑战赛的评估指标
一般来说,评价指标是很容易理解、计算的。例如,在二分类任务中,precision 和 recall 是最简单、最容易想到的评价指标。但目标检测与二分类任务不同。目标检测不仅需要检测有没有目标,还需要检测在哪里,什么类别。因此怎么来定量地评价目标检测系统的性能变得有点难度。
1. 目标检测问题
要定量地评估一个目标检测系统的性能,那你首先得知道目标检测系统到底解决的问题是什么?
目标检测问题:给定一张图像,找出其中有哪些物体,给出物体的位置,以及类别(原文:Given an image, find the objects in it, locate their position and classify them)。
目标检测模型训练使用的数据集一般只有固定数量的类别,所以模型只能定位、分类图像中特定类别的物体。另外,目标检测系统一般采用 矩形边框 表示目标的位置。
下面的图片展示了 “分类”、“分类+定位”、“目标检测”、“实例分割” 四个任务的目的及区别。
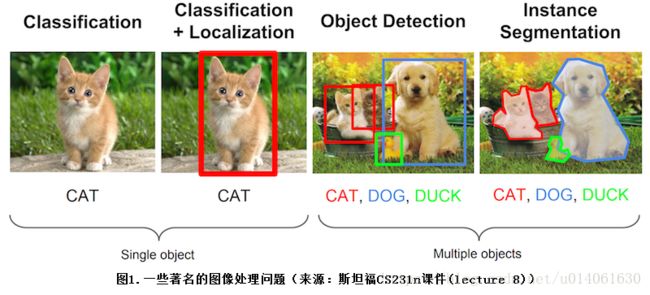
mAP 一般用于目标检测算法(需要同时检出 目标的位置、类别)。当然,mAP 对于 “分类+定位”、“实例分割” 任务的模型的评估也非常有用。
2. 目标检测模型的评估
2.1 为什么选择 mAP ?
在目标检测中,每张图片可能包含多个类别的多个目标。因此,目标检测模型的评价需要同时评价模型的 定位、分类效果。
因此,在图像分类问题中常使用的 precision 指标不能直接用于目标检测。这时 mAP 进入了人们的视野。我们希望你看完本篇文章后,知道 “什么是 mAP” 及 “其代表的实际意义”。
2.2 什么是 Ground Truth?
对于任何算法,评估的过程其实就是 评估预测值与真实值的差距。我们只知道 训练、验证、测试集上的真实值(ground truth)。
对于目标检测问题,ground truth 包括 “image”、“classes of the objects in it” 及 “true bounding boxes of each of the objects in that image”。
一个例子:

我们有实际的 image 及 annotations(bbox(x,y,w,h) 和 class)。
对这个特定的例子,我们的模型在训练过程中可以利用的信息有:

以及三组标记(假设图像的尺寸为 1000×800px,并且所有的位置是像素级别的)。
| 类别 | x 坐标 | y 坐标 | 边框宽度 | 边框高度 |
|---|---|---|---|---|
| Dog | 100 | 600 | 150 | 100 |
| Horse | 700 | 300 | 200 | 250 |
| Person | 400 | 400 | 100 | 500 |
2.3 计算 mAP 的准备工作
目标检测时,模型返回很多的 predictions,但是其中大多数有非常低的 confidence,因此我们只考虑 confidence 大于指定阈值的 predictions。
带 bbox 的 image:

因为人类是目标检测专家,所以我们能够说这些检测是正确的,但是我们该怎么量化评估这些预测呢?
我们首先需要去判断每个预测的正确性。(Intersection over Union)IoU 可以告诉我们每个预测 bbox 的正确性。IoU 是一个非常简单、可视化评价指标。
从 IoU 的字面来看,其的意思显而易见,但是我们需要一个更加详细的解释。我将用一个简单的形式解释 IoU,如果想看更加详细的解释,Adrian Rosebrock 有一篇文章你可以参考。
2.3.1 什么是 IoU?
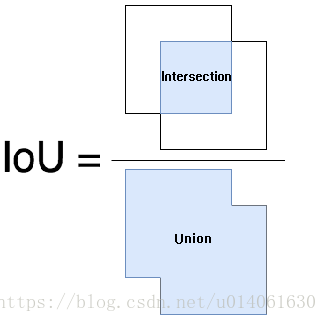
预测的边框 和 真实的边框 的交集和并集的比例 称为 IoU(Intersection over Union)。这个指标又名 “Jaccard Index”,由 Paul Jaccard 在 19 世纪早期提出。
为了获得 IoU 值,我们首先将预测边框和真实边框放在一张图像上(见下图)。对于预测的,预测边框和真实边框的重叠区的面积是 intersection area,总面积是 union。

上图中马的 IoU 的计算方式如下:

Intersection 包含青色区域,Union 包含橙色和青色区域。
IoU 将按照如下方式计算:
2.3.2 什么样的预测时正确的?怎么计算 precision 及 recall?
同其他机器学习问题一样,为了计算 precision、recall,我们不得不去判定 True Positives (TP)、False Positives (FP)、True Negatives (TN)、False Negatives (FN)。
为了得到 TP、FP,我们使用 IoU 来判定预测结果是正确的还是错误的。最常用的 IoU 阈值是 0.5。如果 IoU 大于 0.5,则认为该预测是 TP,否则认为是 FP。COCO 评估指标建议使用不同的 IoU 阈值,但是为了简单,我们假设阈值是0.5,这就是 Pascal VOC 数据集的评价指标。
为了计算 recall,我们需要统计 negatives 的数量。因为图像中没有目标的区域都是 negative,故衡量 TN 是没有意义的。所以我们只统计 FN(模型漏检的目标)。
另一个需要被考虑的因素是模型检测到的目标的 confidence。通过改变 confidence 阈值,我们能够改变预测的 box 是否是正确的。基本上,高于阈值的所有预测(box + class)被认为是 positive boxes,低于阈值则为 negatives。
到目前为止,对于每一张图片,我们有 ground truth
现在,我们计算 Ground Truth 和 模型预测的 Positive detection 的 IoU。基于设定的 IoU 阈值(这里我们暂且设置IoU阈值为0.5),我们为每一张图像的各类目标计算正确检测的数量(TP)。然后用其来为每一类计算 Precision ——— TP / (TP+FP)。
因为我们已经计算了正确检出的数量(TP)、漏检的数量(FP),因此我们可以为每一类计算 recall 了。
precision、recall、IoU 的区别:
只是分母不一样而已!

2.4 计算 mAP
2.4.1 使用 Pascal VOC 挑战赛的评估指标
mAP 其实有很多种不同的定义。这个指标通常用于信息检索、目标检测领域。mAP 在不同领域,有不同的计算方法。我们在本篇将讨论目标检测领域 mAP 的计算方法。
目标检测中 mAP 的使用需要追溯到 Pascal Visual Objects Classes challenge,该比赛包括了各种计算机视觉任务。关于该比赛的细节见 [link] (备份)
我们对于 precision 和 recall 的计算采用上节叙述的方法。
但是,正如上节介绍的一样,有两个影响 precision 和 recall 计算的变量(IoU 阈值、confidence 阈值)。
IoU 是一个简单的几何指标,其可以很容易被标准化,例如:VOC 挑战赛评估指标基于 50% IoU 计算 mAP,然而 COCO 挑战赛更进一步,计算 mAP 时使用的 IoU 阈值从 5%-95%。不同模型预测值的 confidence 可能不同,你的模型的 50% confidence 可能对应其他人模型的 80% confidence。这将改变 precision recall 曲线的形状。因此 VOC 组织者想出了一个与模型无关的评价方式。
VOC 建议我们计算一个称为 Average Precision(AP) 的指标:
对于给定的任务和类别,根据 “依据 IoU 排序后的预测” 来计算 precision / recall 曲线。AP 总结了 PR 曲线的形状,AP 被定义为等间隔[0, 0.1, …, 1]的 recall 级别上 precision 的均值。
具体来讲,我们选择了 11 个不同的 IoU 阈值来得到 PR 曲线。AP 被定义为所选的 11 个 IoU 阈值对应的 Recall 值的 Precision 值的平均值。这使得 mAP 成为整个 PR 曲线的整体概括。
本文下来详细介绍上面的计算中的 precision 的计算。
在每一个 recall 等级 r 的 precision 的计算方法为:在 recall 不超过 r 时,最大的 precision。
具体来说,对于给定的 recall 值,我们使用最大的 precision。
mAP 就是所有类别的 AP 的均值。
上面讲述了 mAP 的计算。当然在某些情况下,mAP 的计算可能发生一些变化。例如,COCO 数据集使用的直接指标更加严谨(使用不同的 IoU 阈值 和 目标尺寸 more details here)。
当我们计算 mAP 值时,需要注意一些 “点”:
- mAP 的计算通常都是在一个数据集上计算的。
- 尽管很难去解释模型的绝对性能,但 mAP 作为一个较好的相对指标,有助于评价模型。当我们在一些流行的公开数据集上计算该指标时,可以很容易地使用 mAP 去比较目标检测新旧算法的性能。
- 根据训练集的类别分布情况,不同类别的 AP 值可能会出现较大差异(训练数据较好的类别有较高的 AP 值,训练数据不好的类别有较低的 AP 值)。所以你的 mAP 可能是稳健的,但是你的模型可能对某些类别的效果较好,对于某些类别的效果不好。因此在分析模型时,建议去查看下各类别的 AP 值。这些值可以作为添加训练数据的一个参考指标。
来源:
http://tarangshah.com/blog/2018-01-27/what-is-map-understanding-the-statistic-of-choice-for-comparing-object-detection-models/