TT100K数据情况、扩增与检查
一、数据集情况
TT100K字面的意思就是腾讯和清华一起合作制作的交通标志数据集(100K就是10万张)
但是,里面差不多有1万多张图片有包含交通标志,训练数据集(train文件夹里面是有6105张图片),测试数据集(test文件夹里面是有3071张图片),当然每张图片包含多个实例,图片的标注文件格式是json,经过计算,训练数据集总共包含16527个实例,测试数据集包含8190个实例。
作者也说了存在类别不均衡现象,毕竟有些标志(比如山体滑坡、前面村庄)在市中心是看不到的,数据里面类别不均衡还是很严重的,json文件的types共221个类别。
缺失了70个类别,也就是说有70个类别没有实例。占到了快1/3。
0 < 实例数 < =10 :73个类别
10 < 实例数 < =50 :32个类别
50 < 实例数 < =100 :13个类别
100 < 实例数 < =500 :22个类别
实例数 > 500 :11个类别
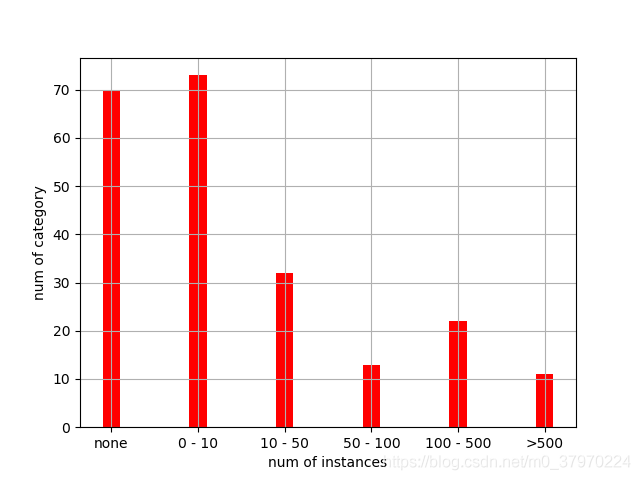
还有marks里面也不完整,从柱状图可以看出实例大于500的类别仅为11个,数据扩增显得尤为重要!(坑)
刚开始我以为数据量是ok的,没想到数据质量并不理想,这也是我训练时候模型一直很差才发现的~
二、数据扩增的思路
1、方案一:没有数据,当然是上网找数据来扩充,但是呢,关于中国交通标志的数据集匮乏(很少),本来是想拿其他数据集来进行补充,有一个长沙理工做的,博客放这:
https://blog.csdn.net/dong_ma/article/details/84339007
但是这个分类就没那么细了,就是粗分类,分七大类,粒度太粗啦,数据是从行车视频记录仪上面截下来,重复度较高。(弃用)
2、方案二:同样像TT100K那样去爬腾讯街景图片是否可行?爬下来那还是得人工进行分类,或者利用别人训练好的模型来检测识别街景图片,并打上标注扩增数据,应该也是可以,但是最终还是得check一下。
3、方案三:当时脑子里有个想法就是有没有那种无中生有的算法,让它先看下交通标志长啥样,再让它看下场景,最后看下那个有交通标志的实际场景,然后input一张场景图片,out就是一张带交通标志的图片,是不是叫做GAN?也就是说它是一个会想象的模型,还没有尝试了解~(很好的一个点)
4、方案四:发现数据集中有marks,就是每个交通标志的大头贴,如下图所示:
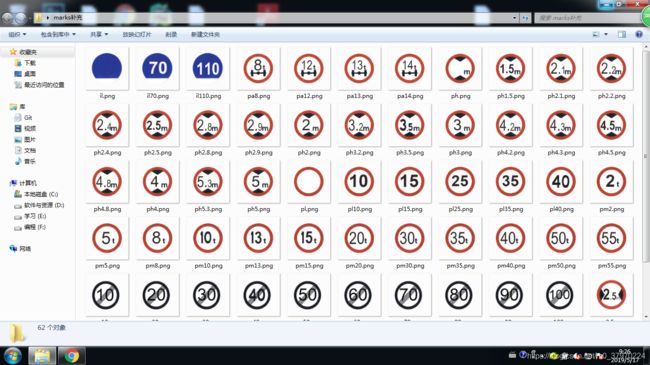
这是我补充进去的,原本的不全~
根据禁令、指示和警告各类交通标志的形状颜色相近的特点(如指示的就是外形为圆,蓝底白字)
就想能不能把缺少的mark来P到同一个大类的训练图片上来(同一bbox)上去就好了~
p之前长这样(如下)
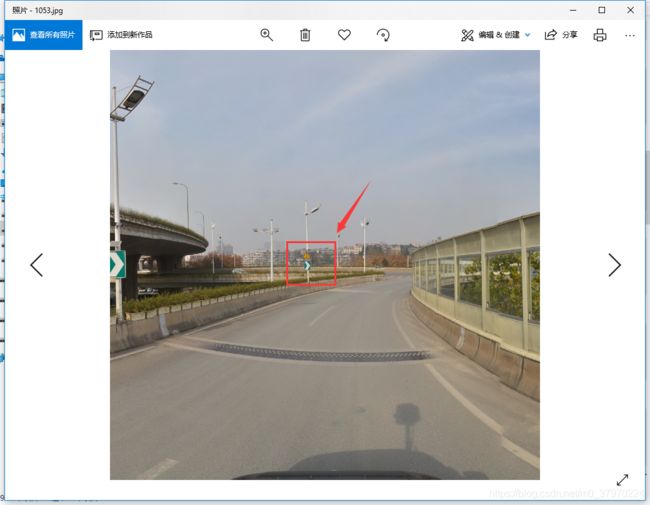
把这个给p掉,同一位置,换了个类别~

当然,如果有原始数据那就很好咯,但是没有,那就自己p
这里会出现几个问题:
1、亮度。p上去的交通标志太突兀了,因为亮度问题(其实我在p的过程中已经随机选择一个亮度值来p了,可能这种随机取亮度值没有考虑被p图片的亮度,是否应该计算下被p那个位置的亮度,再来p,这样效果会更好吧)
2、变形。p的过程发现,正正的那种交通标志,p上去效果好,但是那种角度偏的交通标志就产生变形了,所以p的时候也应该进行缩放变形。
然后,写了个程序就给它批量的p上去啦~
代码还是贴一下吧,怕下次找不到~
写了两种,一种是p指定类别,一种是随机p
# p指定的类别
# annos:你的json文件
# label:你要p的类别
# num:你要p几张
def p_one_category(annos, label, num):
print('p指定的类别')
annos_add = '{}'
# 打开训练图片的ids,num就是你想p几张
with open('E:\data\TT100K\data\/train\ids.txt') as f:
filenames = f.readlines()
image_ids = sample(filenames, num)
i = 0
while i < len(image_ids):
# 开始读json
image_id = image_ids[i].strip()
objects = annos['imgs'][image_id]['objects']
# 复制一份json出来
annos_copy = annos['imgs'][image_id]
print(annos_copy)
# 打开图片
im2_path = os.path.join('E:\data\TT100K\data\/train\/', image_id + '.jpg')
im2 = Image.open(im2_path)
count = 1
# 看是以谁开头
start = label[0:1]
print(start)
for index, obj in enumerate(objects):
if obj['category'].startswith(start):
im2 = paste(obj, label, im2)
annos_copy['objects'][index]['category'] = label
# p一个就好啦,因为可能存在objects里面存在两个一样的类型(比如i1),我们要一个就够啦
break
count = 0
# 可能出项这张图片并没有你想要的类型(如i1),如果有,上面的for循环就跳出来,当然count就不会为0
if count != 0:
# 修改json和图片
annos_copy['path'] = 'train/' + image_id + label + '_add.jpg'
annos_copy['id'] = image_id + label + '_add'
annos_add = json.dumps({**json.loads(annos_add), **{image_id + label + '_add': annos_copy}})
print(annos_add)
add_path = 'E:\data\TT100K\data_noin_w\/' + label + '/' + label + '_add/'
if not os.path.exists(add_path):
os.makedirs(add_path)
im2.save(add_path + image_id + label + '_add.jpg', 'JPEG')
# print('第%d张', i)
print('\r>> Finished image %d/%d' % (i + 1, num))
i += 1
print('结束!')
# 写入json数据
with open(add_path + label + '_add' + '.json', 'w', encoding='utf-8') as json_file:
json.dump(annos_add, json_file, ensure_ascii=False)
随机p又是啥
其实,思路一样啦
就是一张图片对应一个objects,objects包含object,随机p就是可以p一个object或两个,要p的类别也是随机挑~
# 增加这70个类别没有的数据
# 随机选择2500张训练图片
def random_choose_image(annos):
print('随机选择2500张!')
expand_class = []
no_prohibitory, no_indication, no_warning = filter_data()
annos_add = '{}'
with open('E:\data\TT100K\data\/train\ids.txt') as f:
filenames = f.readlines()
image_ids = sample(filenames, 2500)
i = 0
while i < len(image_ids):
image_id = image_ids[i].strip()
objects = annos['imgs'][image_id]['objects']
annos_copy = annos['imgs'][image_id]
print(annos_copy)
count = 0
if len(objects) > 0 and len(objects) < 4:
count = 1
if len(objects) > 4:
count = 2
obj_sample = sample(objects, count)
im2_path = os.path.join('E:\data\TT100K\data\/train\/', image_id + '.jpg')
im2 = Image.open(im2_path)
class0 = ""
for obj in obj_sample:
label = obj['category']
# print(label)
print('obj')
print(obj)
if label.startswith('i'):
no_obj = sample(no_indication, 1)
if label.startswith('p'):
no_obj = sample(no_prohibitory, 1)
if label.startswith('w'):
no_obj = sample(no_warning, 1)
print(no_obj[0])
class0 = no_obj[0]
if class0 != "":
expand_class.append(class0)
# 干正事(粘贴上去)
im2 = paste(obj, no_obj[0], im2)
# 替换json数据
for obj in annos_copy['objects']:
if obj['category'] == label:
obj['category'] = no_obj[0]
print("class0" + class0)
annos_copy['path'] = 'train/' + image_id + '_add.jpg'
annos_copy['id'] = image_id + '_add'
annos_add = json.dumps({**json.loads(annos_add), **{image_id + '_add': annos_copy}})
# print(annos_add)
# imgs[image_id + '_add']
if count != 0:
im2.save('E:\data\TT100K\data_noin\/' + class0 + '/' + image_id + '_add.jpg', 'JPEG')
print('第%d张', i)
i += 1
print('结束!')
print(expand_class)
# print(annos_add)
# print(annos['imgs'])
# annos['imgs'] = json.dumps({**annos['imgs'], **annos_add})
# 写入json数据
with open("E:\data\TT100K\/data_noin\/data_noin.json", 'w', encoding='utf-8') as json_file:
json.dump(annos_add, json_file, ensure_ascii=False)
贴的那个函数得上一下:
def paste(obj_anno, mark, im2):
width = round(obj_anno['bbox']['xmax']) - int(obj_anno['bbox']['xmin'])
height = round(obj_anno['bbox']['ymax']) - int(obj_anno['bbox']['ymin'])
im1_path = os.path.join('E:\data\TT100K\data\/marks_small\/', mark + '.png')
im1 = io.imread(im1_path)
# 随机亮度调节
gamma = round(random.uniform(0.5, 2), 1)
gam = exposure.adjust_gamma(im1, gamma)
im_resized0 = transform.resize(gam, (height, width))
img = im_resized0 * 255
img = img.astype(np.uint8)
im_resized = Image.fromarray(img, mode='RGBA')
im2.paste(im_resized, (int(obj_anno['bbox']['xmin']), int(obj_anno['bbox']['ymin'])), mask=im_resized)
print("success!")
return im2
三、数据检查
我这边用的是方案四来进行批量p
但是,很担心数据的质量,数据质量差模型就很难train
基于此,开发一个数据质检程序
主要达到两个目的:
1、方便查看p后的位置准不准,直观的展示,提高工作效率
2、如果质量差,那可以在程序上面进行bbox的微调,要是实在差的不行的,还可一键删除
图形界面如下:
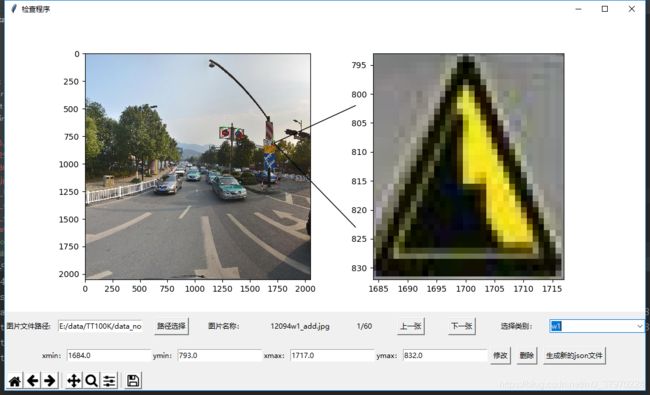
放大后:

代码就不贴了~
还在犹豫什么?一键三连,谢谢~