第六节Pytorch_BERT_CASREL关系抽取模型学习记录
上一节我们已经完成了Dataset类的完成,完成了collate_fn函数并且返回了我们想要的数据,接下来就要将这些数据传入Casrel模型,所以从本节开始我们来构建Casrel模型
一、添加配置项
#config.py
import torch
DEVICE='cuda' if torch.cuda.is_available() else 'cpu'
BATCH_SIZE=2
BERT_DIM=768
LR=5e-5#学习率
EPOCH=50
MODEL_DIR='./data/output'二、新建模型文件
#model.py
import torch.nn as nn
from transformers import BertModel
from config import *
import torch
import torch.nn.functional as F
#忽略transformers的警告
from transformers import logging
logging.set_verbosity_error()三、模型总体架构
1.模型的初始化
#class Casrel
def __init__(self):
super().__init__()
self.bert=BertModel.from_pretrained(BERT_MODEL_NAME)
#冻结Bert参数,只训练下游模型
for name,param in self.bert.named_parameters():
param.requires_grad=False
#序列
self.sub_head_linear=nn.Linear(BERT_DIM,1)
self.sub_tail_linear=nn.Linear(BERT_DIM,1)
#矩阵
self.obj_head_linear=nn.Linear(BERT_DIM,REL_SIZE)
self.obj_tail_linear=nn.Linear(BERT_DIM,REL_SIZE)在初始化函数里,我们首先继承(super)
其次将我们在huggingface下好的bert模型定义为bert
再其次冻结bert参数,经过这一步我们发现模型收敛得更快了
定义头实体得全连接线性层为序列
定义尾实体以及关系的全连接线性层为矩阵
2.get_encoded_text函数
def get_encoded_text(self,input_ids,mask):
"根据掩码转换为词向量"
return self.bert(input_ids,attention_mask=mask)[0]3.预测头实体起始位置的get_subs函数
def get_subs(self,encoded_text):
"得到头实体预测的起始位置"
pred_sub_head=torch.sigmoid(self.sub_head_linear(encoded_text))
pred_sub_tail=torch.sigmoid(self.sub_tail_linear(encoded_text))
return pred_sub_head,pred_sub_tail经过全连接以及sigmoid层得到预测位置
其中encoded_text在forward函数中
4.预测尾实体以及关系的get_objs_for_specific_sub函数:
def get_objs_for_specific_sub(self,encoded_text,sub_head_seq,sub_tail_seq):
#sub_head_seq.shape(b,c)->(b,1,c)扩充一个维度是为了让矩阵相乘,b为batch_size,c为句子长度
sub_head_seq=sub_head_seq.unsqueeze(1).float()
sub_tail_seq=sub_tail_seq.unsqueeze(1).float()
#encoded_text.shape(b,c,768)
#(b,1,c) matmul(b,c,768)就是把第一维提出来后两维做矩阵乘法即可即(b,1,768)
#这里的sub_head/tail_seq是0 1 序列1表示起始位置与encoded_text相乘相当于只保留了1对应的词编码
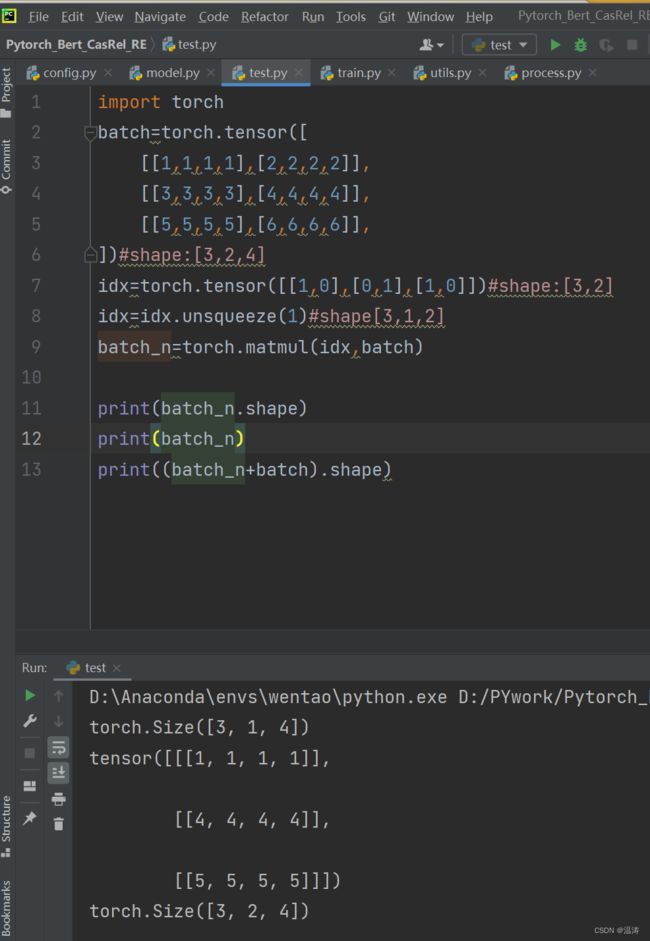
#例子在matual例子png中
sub_head=torch.matmul(sub_head_seq,encoded_text)
sub_tail=torch.matmul(sub_tail_seq,encoded_text)
encoded_text=encoded_text+(sub_head+sub_tail)/2
#encoded_text.shape(b,c,768)
pred_obj_head=torch.sigmoid(self.obj_head_linear(encoded_text))
pred_obj_tail=torch.sigmoid(self.obj_tail_linear(encoded_text))
#shape(b,c,REL_SIZE)
return pred_obj_head,pred_obj_tail对于matual函数的用法我想贴个图解释一下:
5.forward函数
def forward(self,input,mask):
input_ids,sub_head_seq,sub_tail_seq=input
#input_ids.shape(batch_size,句子长度)
encoded_text=self.get_encoded_text(input_ids,mask)#这一步是将id转换为向量
#encoded_text.shape(batch_size,句子长度,bert维度768)
#预测subject首尾序列
pred_sub_head,pred_sub_tail=self.get_subs(encoded_text)
#print(pred_sub_head.shape)#(batch_size,句子长度,1)只需要一行判断0或者1
#print(pred_sub_tail.shape)
#预测relation—object矩阵
pred_obj_head,pred_obj_tail=self.get_objs_for_specific_sub(encoded_text,sub_head_seq,sub_tail_seq)
return encoded_text,(pred_sub_head,pred_sub_tail,pred_obj_head,pred_obj_tail)对于pred_obj_head.shape应该是(batch_size,句子长度,48也就是关系数)