纽约大学深度学习PyTorch课程笔记(自用)Week7
纽约大学深度学习PyTorch课程笔记Week7
- 7.1 能量模型(Energy-Based Models)
-
- 7.1.1 Overview
- 7.1.2 能量基础模型(EBM)方法
-
- 定义
- 解决方案:基于梯度的推理
- 7.1.3 有潜在变量的能量基础模型
-
- 推理
- 例子
- 7.1.4 能量基础模型和机率模型的对比
-
- 自由能(Free Energy)
- 7.2 自我监督学习(SSL)﹑能量基础模型(EBM)的细节和例子
-
- 7.2.1 自我监督学习(Self supervised learning)
-
- 用(潜在变量能量基础模型)来作为解决方法来预测出下一帧:
- 7.2.2 训练能量基础模型
- 7.2.3 潜在变量基础模型
- 7.2.4 潜在变量能量基础模型(EBM)例子: K均值
- 7.2.5 对比法
-
- 去噪自动编码器(Denoising autoencoder,简称 DAE)
- 伯特模型(BERT)
- 对比发散
7.1 能量模型(Energy-Based Models)
7.1.1 Overview
我们现在介绍一个新框架来定义模型。它提供了一个统一和系列性的方式来定义「监督模型」,「无监督模型」和「自我监督模型」。能量基础模型根据一组变量 x x x然后输出一组 y y y。对于feed-forward nets,有两个主要问题:
- 如果推理程序是比一层又一层的加权总和更复杂的计算?
- 如果这里有多个可能输出,而同时只有一个输入?比如预测的视频未来的部份。特别地是在分类型神经网路中,我们训练神经网路去输出一个分数表示是那一个类。但是,这是不可能在高维度域中这样用的(我们不能对图像使用归一化softmax!)。即使输出是离散的,样本空间也是十分巨大。比如文字是构成性组合的,那会导致大量不同的可能的组合。能量基础模型提供一个更好的框架来对这些模型建立模型。
7.1.2 能量基础模型(EBM)方法
现在我们不做把数个 x x x分类为数个 y y y,而是我们想去预测特定的配对( x , y x, y x,y)是否适合地放在一起。或转另一面来说,找出一个 y y y那是对应 x x x。我们也可以这样提出一个问题,找出一个 y y y那是能令一些 F ( x , y ) F(x,y) F(x,y)数值低下,比如:
- y y y是 x x x的高画质版图像吗?
- 文字A是B的良好翻译版吗?
定义
我们定义「能量函数」 F : X × Y → R F: \mathcal{X} \times \mathcal{Y} \rightarrow \mathcal{R} F:X×Y→R其中 F ( x , y ) F(x,y) F(x,y)描述了 ( x , y ) (x,y) (x,y)对中的依赖程度。 (注意这个能量是用在推理上,而不是学习上。)推理是以下这个方程: y ˇ = argmin y { F ( x , y ) } \check{y} = \displaystyle \text{argmin}_y \left \{ F(x,y)\right \} yˇ=argminy{F(x,y)}
解决方案:基于梯度的推理
我们想「能量函数」是畅滑而且是可微的,所以我们可以用它来进行一些基于梯度的推理方法。为了进行推理,我们用梯度下降法搜索这个函数,找到兼容的 y y y。有许多可以替代梯度法的方法来获得最小值。
同时: 图形化模型是「能量基础模型」的特例。 「能量函数」是所有能量项的和。每一个能量项都对应一个变量子集,而这些变量子集是我们正在处理的。如果它们以一种特定的形式组织起来,就会有有效的推理算法来寻找关于我们感兴趣的变量的项之和的最小值
7.1.3 有潜在变量的能量基础模型
输出 y y y是根据 x x x和另一个变量 z z z(潜在变量),但我们不知道它的值。这些潜在变量可以提供辅助信息。比如一个潜在变量可以根据一堆文字中各自的部份进行分区。这对于没有间隔的手写文字中十分有用。这是特别对十分难进行分区的语音中十分有用。除此之外,有些语言的词的边界非常模糊(比如法语)。所以在我们的模型中有这些潜在变量是在理解这类型输入时是十分有用的。
推理
去用「潜在变量EBM」做推理时,我们同时用能量函数找出最小值,能量函数相对于y和z。
y ˇ , z ˇ = argmin y , z E ( x , y , z ) \check{y}, \check{z} = \text{argmin}_{y,z} E(x,y,z) yˇ,zˇ=argminy,zE(x,y,z)
而且这是等于重新定义能量函数: F ∞ ( x , y ) = argmin z E ( x , y , z ) F_\infty(x,y) = \text{argmin}_{z}E(x,y,z) F∞(x,y)=argminzE(x,y,z), 也等于: F β ( x , y ) = − 1 β log ∫ z exp ( − β E ( x , y , z ) ) F_\beta(x,y) = -\frac{1}{\beta}\log\int_z \exp(-\beta E(x,y,z)) Fβ(x,y)=−β1log∫zexp(−βE(x,y,z))。 当 β → ∞ β → ∞ , 那 y ˇ = argmin y \beta \rightarrow \inftyβ→∞, 那 \check{y} = \text{argmin}_{y} β→∞β→∞,那yˇ=argminy).
另一个使用「潜在变量」的重大优点是改动一个集合中「潜在变量」的值,那样我们就能令输出 y y y随着多个不同可能性组成的流形影响着。(那个流形在下方的图显示着): F ( x , y ) = argmin z E ( x , y , z ) F(x,y) = \text{argmin}_{z} E(x,y,z) F(x,y)=argminzE(x,y,z).
这样一台机器就可以产生多个输出,而不仅仅是一个。
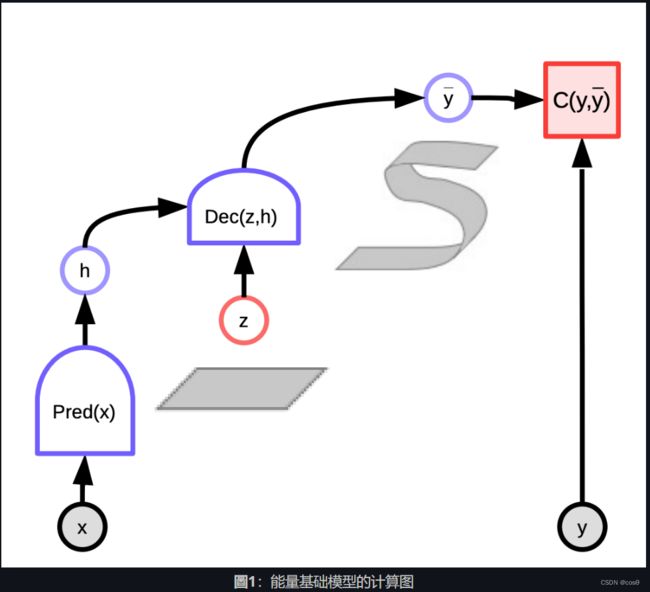
例子
一个例子是视频预测。事实上已经有很多应用领域让我们使用视频预测,一个例子是制作视频压缩系统。另一个是使用自动驾驶汽车的视频去预测别的车下一步是做什么。
另一个例子是翻译。语言翻译一直以来都是一个很困难的问题,因为从一种语言到另一种语言,没有单一的正确翻译。通常这里有很多不同的方式去表达同样的想法,人们很难说出为什么他们选这个方式,而不是另外一个。所以好一点的做法是参数化所有可能的翻译的方式,那系统就能根据输入的文字去表达对应的输出。比如我们说如果我们去翻译德文到英文,那就会有多种英文翻译方式都是对的,同时改变一些潜在变量,就会改变翻译结果。
7.1.4 能量基础模型和机率模型的对比
我们看到能量是非归一化的负对数机率(unnormalised negative log probabilities),同时在归一化(normalization)后使用波兹曼分布(Gibbs-Boltzmann distribution)将能量转换成概率是这样的公式:
P ( y ∣ x ) = exp ( − β F ( x , y ) ) ∫ y ′ exp ( − β F ( x , y ′ ) ) P(y \mid x) = \frac{\exp (-\beta F(x,y))}{\int_{y'}\exp(-\beta F(x,y'))} P(y∣x)=∫y′exp(−βF(x,y′))exp(−βF(x,y))
其中 β \beta β是正常数同时需要根据你的模型来量身定做。大一点的 β \beta β给剧烈一点的模型,而小一点的 β \beta β 给一点更畅滑的模型。 (在物理上,\betaβ是逆温度: β \beta β无限大,那温度就无限地接近零)。
P ( y , z ∣ x ) = exp ( − β F ( x , y , z ) ) ∫ y ∫ z exp ( − β F ( x , y , z ) ) P(y,z \mid x) = \frac{\exp(-\beta F(x,y,z))}{\int_{y}\int_{z}\exp(-\beta F(x,y,z))} P(y,z∣x)=∫y∫zexp(−βF(x,y,z))exp(−βF(x,y,z))
现在如果边缘化 y : P ( y ∣ x ) = ∫ z P ( y , z ∣ x ) y: P(y \mid x) = \int_z P(y,z \mid x) y:P(y∣x)=∫zP(y,z∣x)), 我们就有:
P ( y ∣ x ) = ∫ z exp ( − β E ( x , y , z ) ) ∫ y ∫ z exp ( − β E ( x , y , z ) ) = exp [ − β ( − 1 β log ∫ z exp ( − β E ( x , y , z ) ) ) ] ∫ y exp [ − β ( − 1 β log ∫ z exp ( − β E ( x , y , z ) ) ) ] = exp ( − β F β ( x , y ) ) ∫ y exp ( − β F β ( x , y ) ) \begin{aligned} P(y \mid x) & = \frac{\int_z \exp(-\beta E(x,y,z))}{\int_y\int_z \exp(-\beta E(x,y,z))} \\ & = \frac{\exp \left [ -\beta \left (-\frac{1}{\beta}\log \int_z \exp(-\beta E(x,y,z))\right ) \right ] }{\int_y \exp\left [ -\beta\left (-\frac{1}{\beta}\log \int_z \exp(-\beta E(x,y,z))\right )\right ]} \\ & = \frac{\exp (-\beta F_{\beta}(x,y))}{\int_y \exp (-\beta F_{\beta} (x,y))} \end{aligned} P(y∣x)=∫y∫zexp(−βE(x,y,z))∫zexp(−βE(x,y,z))=∫yexp[−β(−β1log∫zexp(−βE(x,y,z)))]exp[−β(−β1log∫zexp(−βE(x,y,z)))]=∫yexp(−βFβ(x,y))exp(−βFβ(x,y))
所以,如果我们有潜在变量模型,同时想概率论上的正确做法那样的去掉潜在变量zz的话,我们要重新定义能量函数 F β F_\beta Fβ (自由能Free Energy)
自由能(Free Energy)
F β ( x , y ) = − 1 β log ∫ z exp ( − β E ( x , y , z ) ) F_{\beta}(x,y) = - \frac{1}{\beta}\log \int_z \exp (-\beta E(x,y,z)) Fβ(x,y)=−β1log∫zexp(−βE(x,y,z))
计算这个是很难的…事实上,大部份例子中,更可能很棘手。所以如果你有一个潜在变量,而你想要在模型中最小化这个变量,或你有一个潜在变量要边缘化(重新定义能量函数F来逹成这个做法),和同时想对应着这个方程式中无限大 β \beta β的极限来最小少这个潜在变量,那你就计算得到。
在上方 F β ( x , y ) F_\beta(x, y) Fβ(x,y) 的定义, P ( y ∣ x ) P(y \mid x) P(y∣x) 只是是玻尔兹曼分布公式(Gibbs-Boltzmann formula)的一个应用 ,而zz 被边缘化同时隐含地在公式中。物理学家称为「自由能」。这就是为什么我们将其称为 F F F。 e e e是能量, F F F是自由能。
问题:你能阐述能量基础模型的优点吗?在基于概率的模型,你也可以有可以被边缘化的潜在变量。
基于概率的模型和能量基础模型的分别,就是基于机率的模型上你基本上在用来最少化的目标函数上是别无选择,你必须保留机率框架的观念,因为你操作的每个东西都必须被归一化分布(你可以使用变异方法(variational methods)﹑等等去估计﹑或其他方法)。这里,我们说最终你想要用这些模型做的是做决定。如果你建立一个系统去驾驶汽车,然后系统对你说:「我想转左,转左机率为0.8,或转右,转右机率为0.2。」那你就转左。事实上机率为0.2和0.8机率都没关系…你想做的是做最好的决定,因为你会被强行要求做决定。所以如果你想做决定,机率是没用的。你想要结合自动化系统的输出和另一个东西(比如:人,其他系统),而这些系统没有一起被训练,而是分开被训练,然后你想要的是校正这些分数,那样你就可以将两个系统的得分相结合,以便做出更好的决定。只有一条方法去校正这些分数,就是转换它们成机率,所有其他方式都是劣等或一样的,但是,如果您要端对端训练系统来做出决定,那你用什么计分函数都可以,只要它为最佳的決定提供最佳的分数即可。能量基础模型在对应模型时给你更多的选择,或可能可以选择更多不同的训练方式,和以及给你您更多选择选用什么目标函数。但你还是想坚持你的模型是概率化的话,那你必须要用最大似然,那你基本上要训练你的模型去给予一个你所看到过的「数据」有最大的可能性。问题即使这种模型能被证明可行的,但也只会是你的模型是「正确」–––而同时你的模型永远都不「正确」。有一位著名统计学家(乔治·鲍克斯Goerge Box)说过:「所有模型都是错的,但有些是有用。」所以概率模型,特别是那些高维度空间的,和那些组合空间的,比如文字,都是近似模型。它们都是在一些地方是错的,同时如果你尝试去归一化它们,你会令它们更错。所以你最好就不要归一化它们。
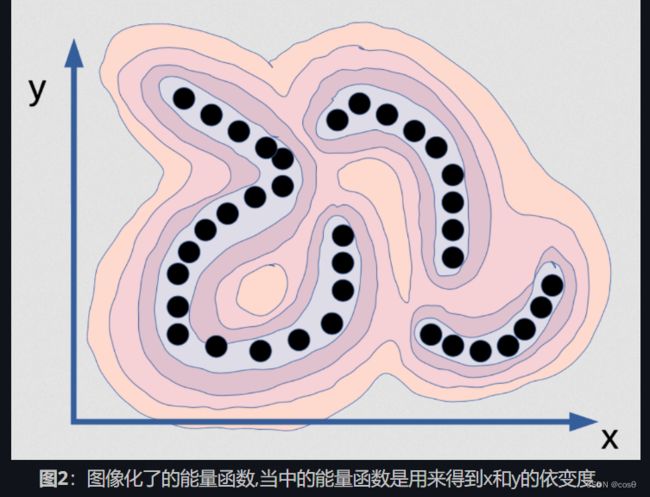
这就是能量函数,就是用来得到x和y的依变度。如果想像的话,就如山脉一样。黑点就是山谷的位置(这些点是数据点),和到处都是山。现在,你就用这个来训练概率模型,想像那些点是在十分薄的流形中。所以黑点的数据分布实际上是一条线,这里有三条,它们都没有任何宽度,所以你用这个来训练概率模型的话,当你的位置在流形上,你的密度模型应该就会说给你听一样的话。在这个流形,密度是无限的,而且\varepsilonε距离外面远离它的话,密度就是零的,那就是这种分布的正确模型。不单只密度是无限,而且在[X和Y]上的积分是1。这是十分难去在电脑上实行!不单只这样,也基本上没可能的。比如说你想用一些神经网来计算这个函数,那你的神经网就会有「无限权重」,而且它们会要被校正到积分在整个域上系统的输出为1。这是基本上没可能的。对于这种的数据例子,准确和正确的概率模型是不可能的。这就是最大似然想得到的,而且世界上没有任何电脑能计算出这个。事实上,这也不有趣。想像下你给这个例子有一个完美的密度模型,这模型就是在那片在(x,y)空间中的薄板…那你更无法做推理!如果我给你X的值,然后问你:「在y中最好的值是什么?」你不能找出来,因为对y来说,除了一些零可能性的集合外,可能有几个值的是有数量的。对于这些x值:

这里有三个Y的值是可能的,它们是无限地窄。所以你不能找到它们。这里没有推理算法能给你找出它们来的。唯一找出它们的方法是如果你令你的「对比函数(contrast function)」是畅滑同时可微分的,然后你就由任何一点开始去梯度找出一个不错和对应x值的y值,但如果是上方说过的第一种类数值分布,这不会给这种数值分布有一个好的概率模型。所以这里就是一个坚持想要好的概率模型例子,而下埸是十分糟糕。 「最大似然」很烂极了[在这个案例的话]!
所以如果你是一个真实的贝叶斯人(Bayesian)的话,你就会说:「喂!你可以用一个很强大的「先验概率(prior)」来修正这个问题,而把那个先验概率设定为说你的密度模型是畅滑的。」你可以想这个为先验概率(prior)。但你以贝叶斯术语来行事的话…在当中做对数,然后把忘归一化了吧…之后你就会得到能量基础模型。能量基础模型有自己的正则化部分,它是外加上去你的能量函数,这些有正则化的能量基础模型和那些用“似然(likelihood)”来作为能量的指数的贝叶斯模型是完全一样的,然后现在你得到的就是exp(能量)exp(正则化器regularizer),也得于exp(能量+正则化器regularizer)。而如果你去除自然底数,你有的就是能量基础模型外加一个正则化器。
因此,概率方法和贝叶斯方法之间存在着对应关系,但是对于坚持使用「最大似然」的你来说有时都只有坏的,特别地在高维度空间或组合空间中,你的概率模型就只是错得很离谱了。不是在离散分布中有错(没关系的),而是有「连续不断性」的用例中就会错得很离谱了,而且不论什么模型,都会是错的。
7.2 自我监督学习(SSL)﹑能量基础模型(EBM)的细节和例子
7.2.1 自我监督学习(Self supervised learning)
自我监督学习(英文简称SSL)同时包含着有监督学习和无监督学习。自我监督学习(SSL)的预训练的目标就是为了学到一个能很好地代表输入的「表示」,那样之后它就能被用在监督任务。在自我监督学习(SSL),模型是被训练到能只要给一部份数据,就能预测出另一部份的数据。比如,BERT是被训练为在使用自我监督学习(SSL)技巧和降噪自动编码器(Denoising Auto-Encoder (DAE) )来在自然语言处理(NLP)任务中达到出色的效果。
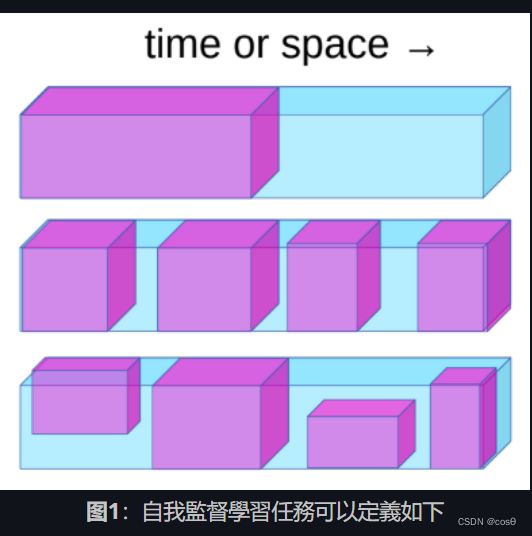
自我监督学习任务可以如以下定义:
- 用过去来预测未来。
- 从可见的部份预测蒙着的部份。
- 从所有提供了的部份中预测那些是被困在一个空间的。
例如,如果系统是被训练了当相机被移动时,然后预测下一帧,那系统就会明显地学到深浅和视差。这会强迫系统去学到物件是困在系统看到的空间中,而且物件没有消失,继续存在,而且学到区分那些东西是动或不动,最后也学到了那一个是背景,它也能学到直观中能学到的物理,比如引力。
能力出色的自然语言处理系统伯特(BERT)会预先在实行自我监督学习前训练一个巨大的神经网路。你会先在一个句子中移除一些文字,然后去给系统预测移除了的文字,而且在下面的图片中,你可以对一张图片,去掉图片的一部分,训练你的模型去预测去掉的部分。

虽然这些模型能补上图片中消失的部份,但他们没有如自然语言处理系统有相同的成功水平。如果你用这些模型生成的「内容表示」来作为的计算机视觉系统的输入,是没法去击败一个用了ImageNet以监督方式进行了训练的模型。
一个智能系统(人工智能代理AI agent)为了能做出智能的决定,它需要能够在周围环境中和自身中去预测自己行为所带来的结果。因为世界是活的,而不能死定起来的,而且对机器和人脑来说,也没有足够的计算能力去计算每一个可能性,所以我们需要要教人工智能系统去在一个高维度之中,在存在着不确定性之中,去进行预测,能量基础模在这方面是非常有用的。
神经网路是用了最小平方法来预测视频的下一帧的话,结果就是图像模糊,因为模型不能准确预测出未来,所以它从训练数据中学到了平均了下一帧的所有可能性来降低损失。
用(潜在变量能量基础模型)来作为解决方法来预测出下一帧:
这与线性回归不一样,潜在变量能量基础模型取了任何我们对世界所知的,包括向我们提供有关现实情况的潜在变量。当两个信息组合起来用来造预测时,那预测出来的就会发生的一分接近。
这些模型可以被想像成一个评估相应度的系统,就是当使用潜在变量来降低和最小化一些系统的能量来预测时,评估输入 x x x和实际输出 y y y的相应度。你就是观察输入 x x x,然后生成可能会发生的预测 y ˉ \bar{y} yˉ ,就是为了把输入x和潜在变量z组合成不同的组合,同时选择一个组合来在系统中来降低和最小化系统中的能量和系统预测误差。
根据我们绘制的潜在变量,我我们可以得出所有可能发生的预测。而潜在变量会被想成一些对输出 y y y来说是重要信息,同时是在输入x中没有。
标量值过的能量函数有两种版本:
- 有条件性 F(x, y)F(x,y) - 测量xx和yy之间的相应度
- 无条件性 F(y)F(y) - 测量yy的组件之间的相应度
7.2.2 训练能量基础模型
以下两类学习模型可以训练基于能量的模型来参数化 F ( x , y ) F(x, y) F(x,y).
- 对比法: 推低 F ( x [ i ] , y [ i ] ) F(x[i], y[i]) F(x[i],y[i])部份,推高其他点 F ( x [ i ] , y ’ ) F(x[i], y’) F(x[i],y’)
- 架构法: 在最小化中加入和使用 F ( x , y ) F(x, y) F(x,y) 函数,那低能量部份的容量就会在正则化过程中被限制或被最小化
其实是有七种类方法去塑造能量函数。对比法和其他方法不同之处是它找一个点来推高它,同时最小化法是限制编码的信息容量。
其中一个对比法的例子是「最大似然学习」,而能量可以被解释为非归一化负对数的密度(unnormalised negative log density)。波兹曼分布(Gibbs distribution)给我们这个,而如果我们给予特定 x x x的话,那波兹曼分布(Gibbs distribution)就会给予 y y y的似然。
P ( Y ∣ W ) = e − β E ( Y , W ) ∫ y e − β E ( y , W ) P(Y \mid W) = \frac{e^{-\beta E(Y,W)}}{\int_{y}e^{-\beta E(y,W)}} P(Y∣W)=∫ye−βE(y,W)e−βE(Y,W)
最大似然尝试令分子变大,而分母变细来最大化似然。这是跟最小化 − log ( P ( Y ∣ W ) ) -\log(P(Y \mid W)) −log(P(Y∣W)) 一样,也就是以下这样
L ( Y , W ) = E ( Y , W ) + 1 β log ∫ y e − β E ( y , W ) L(Y, W) = E(Y,W) + \frac{1}{\beta}\log\int_{y}e^{-\beta E(y,W)} L(Y,W)=E(Y,W)+β1log∫ye−βE(y,W)
对于一个样本 Y ,负对数似然损失的的梯度(Gradient of the negative log likelihood loss)是如下:
∂ L ( Y , W ) ∂ W = ∂ E ( Y , W ) ∂ W − ∫ y P ( y ∣ W ) ∂ E ( y , W ) ∂ W \frac{\partial L(Y, W)}{\partial W} = \frac{\partial E(Y, W)}{\partial W} - \int_{y} P(y\mid W) \frac{\partial E(y,W)}{\partial W} ∂W∂L(Y,W)=∂W∂E(Y,W)−∫yP(y∣W)∂W∂E(y,W)
在上方的梯度,在数据点Y的梯度的第一项和梯度的第二项,它们给我们一个在所有YY上「能量的梯度」的预期值。所以,当我们运行梯度下降时,第一项就会尝试在给予的那些YY点上去降低能量,而第二项就会尝试在其他给予的那些YY上去提高能量。
能量函数的梯度通常地是十分复杂,而所以对常常令人棘手的它来说,计算或估计﹑近似它的积分是十分有意思的。
7.2.3 潜在变量基础模型
潜在变量的主要优势是它们容许令用潜在变量来进行多个预测。如果zz在一个集合之中变化着,那yy也在一个预测可能发生的流形中变化着。一些例子包括:
- K均值(K-means)
- 稀疏建模(Sparse modelling)
- GLO
这些可以有两种类型:
-
条件性模型, y y y取决于 x x x的
- F ( x , y ) = min z E ( x , y , z ) F(x,y) = \text{min}_{z} E(x,y,z) F(x,y)=minzE(x,y,z)
- F β ( x , y ) = − 1 β log ∫ z e − β E ( x , y , z ) F_\beta(x,y) = -\frac{1}{\beta}\log\int_z e^{-\beta E(x,y,z)} Fβ(x,y)=−β1log∫ze−βE(x,y,z)
-
无条件模型,是有标量值能量函数的,而 F ( y ) F(y) F(y)测量 y y y的组成部分中各部分的相关性。
- F ( y ) = min z E ( y , z ) F(y) = \text{min}_{z} E(y,z) F(y)=minzE(y,z)
- F β ( y ) = − 1 β log ∫ z e − β E ( y , z ) F_\beta(y) = -\frac{1}{\beta}\log\int_z e^{-\beta E(y,z)} Fβ(y)=−β1log∫ze−βE(y,z)
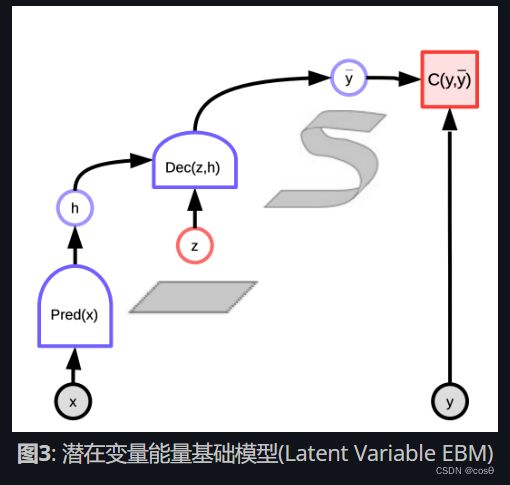
7.2.4 潜在变量能量基础模型(EBM)例子: K均值
K均值是一个简单的聚类算法,当我们去尝试去建造一个 y y y分布模型时,那能够被称为能量基础模型。能量函数是 E ( y , z ) = ∥ y − W z ∥ 2 E(y,z) = \Vert y-Wz \Vert^2 E(y,z)=∥y−Wz∥2 而 z z z 是一个1-hot的向量。
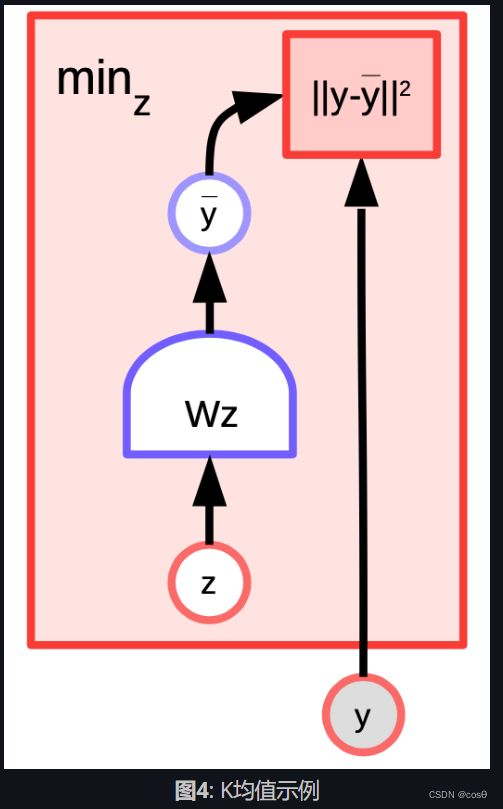
给予 y y y的值和 k k k的值,我们就能通过弄清楚 W W W中那 k k k个列有可能可以最小化「重建误差」或「能量函数」来推理。训练算法的做法是这样,我们可以采用一种方法,方法是找出 z z z,而这个 z z z能够选出 W W W中一那一列是最接近 y y y,然后在不断的重复中用梯度来找出更接近的那一列。相反地,坐标梯度下降实际上比这个更好更快。
在下面的图中,我们可以看到数据点沿着一个粉色螺旋形。黑色斑点围着这条线,同时对应于周围二次的井形状,周围是每一个 W W W的原型。
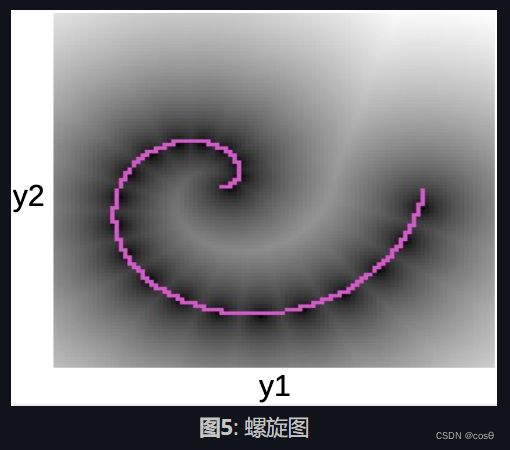
一旦我们学习了能量函数,我们可以开始解决以下问题:
- 给予 y 1 y_1 y1点, 我们能预测 y 2 y_2 y2么?
- 给予 y y y, 我们能找出最接近数据流型的点吗?
K均值属于最小化法(和对比法对立着)。所以我们不会推高能量,而我们做的只是在某些区域中推低能量。其中一个坏处是一但kk的值是被决定了,那就会限定只有kk个点是有00能量,而其他点就会有更高的能量,每向外走一步,就二次地升高。
7.2.5 对比法
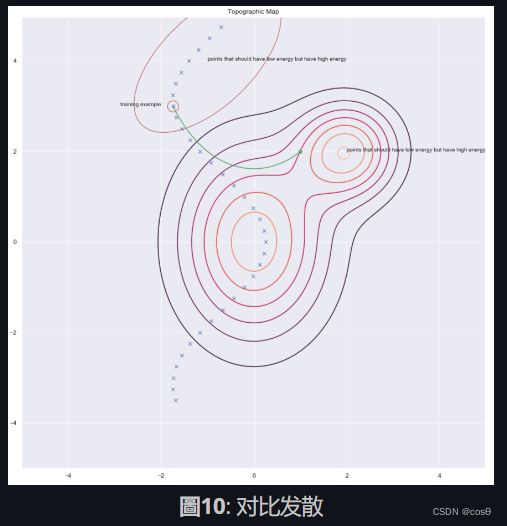
根据LeCun的说法,每个人都在某个时刻使用架构法,但在此刻,我们说适用于图像的对比法。看一下和想一下方的图像,它显示出数据点和能量表面的轮廓。理想的话,我们想在数据流形上的能量面(能量表面)有最低的能量。所以我们想做的是在训练例子附近降低能量(即 F ( x , y ) F(x,y) F(x,y)的值),但单单只是这样做是不足够的。因此,为了 y y y,我们也针对本应具有较高的能量但具有足够的能量的该地区的提升其能量。
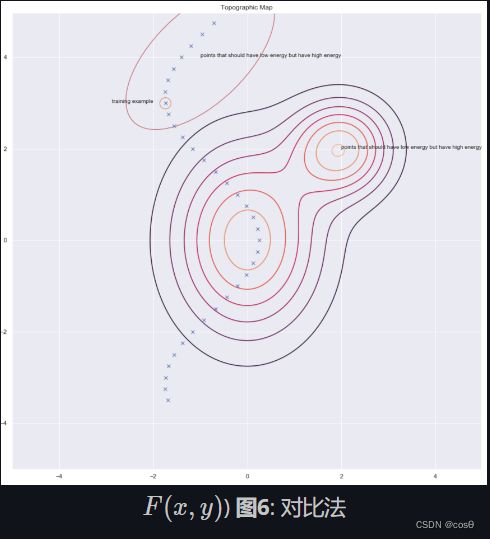
这里有数个方法去找出这些yy来令我们能提高我们想提高的能量。一些例子包括:
- 去噪自动编码器(Denoising Autoencoder)
- 对比发散(Contrastive Divergence)
- 蒙特卡洛(Monte Carlo)
- 马尔可夫链式蒙特卡洛 Markov Chain Monte Carlo
- 汉密尔顿式蒙特卡洛 Hamiltonian Monte Carlo
我们会简单地讨论一下去噪自动编码器和对比发散。
去噪自动编码器(Denoising autoencoder,简称 DAE)
其中一个找出这些 y y y来提高能量的方法,那是随机扰动训练例子,下方图像中的1绿色箭头就是说这个。
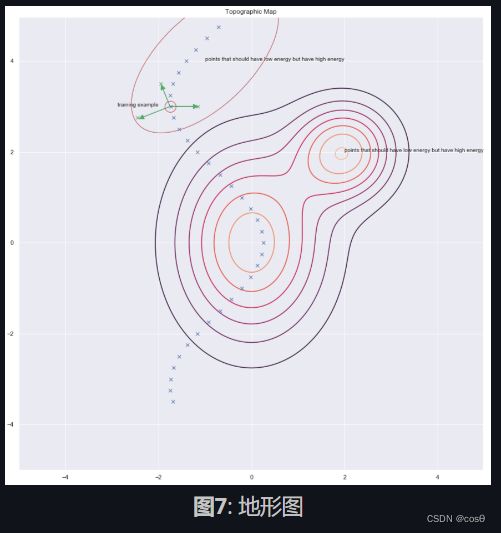
一旦我们有很多乱起来了的数据点,那我们能推这些能量上到这里来。如果我们对这些数据点推的次数是足够的话,那能量样本就会沿着训练例子卷起来。而下方的图就说明了训练是如何完成。
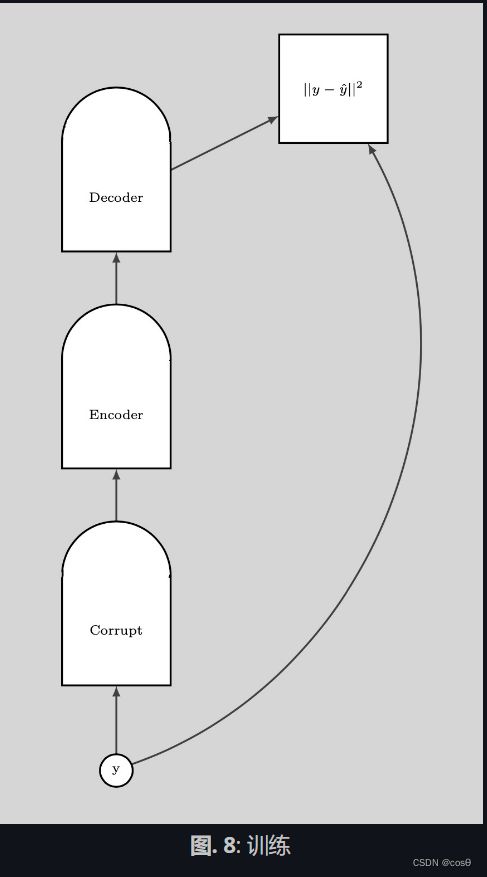
训练步骤:
- 选一个y点然后弄乱它
- 训练编码器和解码器来重建弄乱了的数据点到原来的数据点
如果去噪自动编码器(DAE)是训练得正确的话,那当我们离开数据流体时,能量就二次地升高。
下方的图说明了我们如果使用去噪自动编码器(DAE)
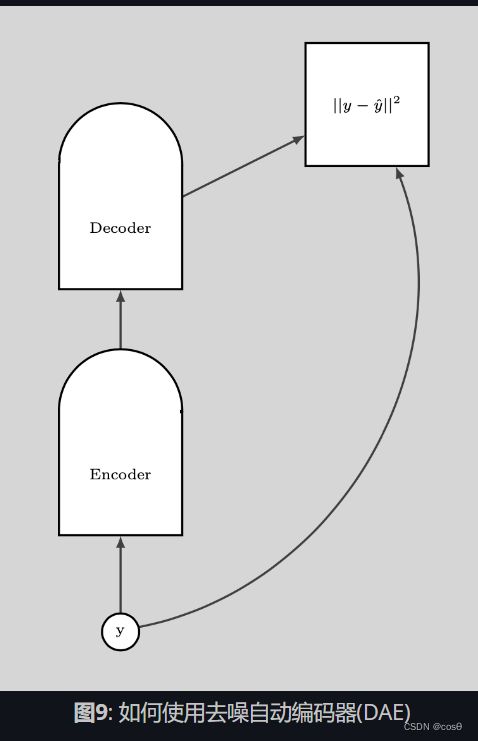
伯特模型(BERT)
跟训练伯特的方法是有点相似,除了当我们处理文字时,空间是离散的话,那就不太一样。 「弄乱」技巧是由掩盖一些文字做法组成的,而「重建」步骤是试图预测这些掩盖了的文字。因此,这也称为掩盖式自动编码器。
对比发散
对比发散向我们呈现了一个更聪明的方式去找出我们想要提高能量的y点。我们可以对训练点用「随机踢」,之后就会用梯度下降来令能量函数下移。在轨道最后的部份,我们对我们落在的点上提高能量。下图用绿线来说明了。
关于纽约大学深度学习课程准备先弃坑了,主要是每次学习完带着浓厚口音的英文课程后,我还要花大量的时间来找文章来理解课程中讲的不是很清楚的知识。后面准备学习李沐老师在B站的动手学深度学习 PyTorch版课程