Nhanes临床数据库挖掘教程2—基线表绘制(table1)
美国国家健康与营养调查( NHANES, National Health and Nutrition Examination Survey)是一项基于人群的横断面调查,旨在收集有关美国家庭人口健康和营养的信息。
地址为:https://wwwn.cdc.gov/nchs/nhanes/Default.aspx
上一章我们已经介绍了如何下载Nhanes临床数据库,本章来介绍一下如何绘制Nhanes临床数据库的基线表,也就是表一。

继续使用我们上次制作好的数据,我们先把数据导入,可以按上一章的方法提取,如果想偷懒一点的,直接想要我的数据的请公众号回复:代码。或者也可以在这里下载:https://download.csdn.net/download/dege857/86886630
library(tableone)
library(survey)
bc<-read.csv("E:/nhanes/nhanes.csv",sep=',',header=TRUE)
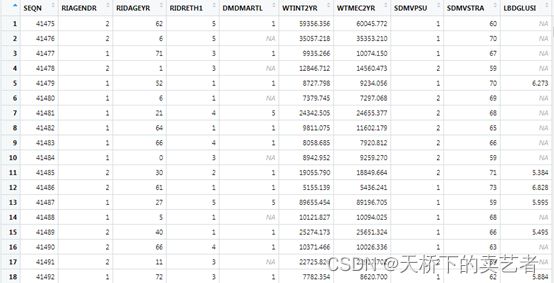
我介绍一下数据,SEQN:序列号,RIAGENDR, # 性别, RIDAGEYR, # 年龄,RIDRETH1, # 种族,DMDMARTL, # 婚姻状况,WTINT2YR,WTMEC2YR, # 权重,SDMVPSU, # psu,SDMVSTRA,# strata,LBDGLUSI, #血糖mmol表示,LBDINSI, #胰岛素( pmmol/L),PHAFSTHR #餐后血糖,LBXGH #糖化血红蛋白,SPXNFEV1, #FEV1:第一秒用力呼气量,SPXNFVC #FVC:用力肺活量,ml(估计肺容量),LBDGLTSI #餐后2小时血糖。
按照论文:Non-linear association between diabetes mellitus and pulmonary function: a population-based study的介绍

它的基线表是分为正常患者、糖尿病前期,糖尿病3个类型,
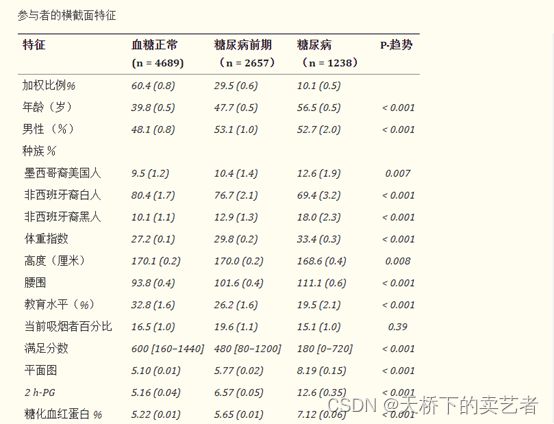
但是文中没有给出是怎么分类判断的,我就按照OGTT来随便分一下

OCTT小于7.8算是正常患者,7.8—11是糖尿病前期,大于11为糖尿病
bc$oGTT2<-ifelse(bc$LBDGLTSI<7.8,1,ifelse(bc$LBDGLTSI>=11,3,2))
上面代码的意思是把小于7.8的分类为1,大于11的分类为3,其余分类为2

下面开始建立抽样调查函数svydesign,ids表示集群的意思,这里填入抽样单元SDMVPSU(PSU),如果没有的话填入1,strata = ~ SDMVSTRA,strata这里是分层的意思,这里填入SDMVSTRA,weights是权重的意思,参照别的大佬的意思,如WTINT2YR,WTMEC2YR,这两个权重就填入WTMEC2YR,data填入你的数据就可以了
bcSvy2<- svydesign(ids = ~ SDMVPSU, strata = ~ SDMVSTRA, weights = ~ WTMEC2YR,
nest = TRUE, data = bc)
我们解析一下看看,可以看到分成16个层
summary(bcSvy2)

接下来就是绘制基线表,使用的是svyCreateTableOne函数,先要定义全部变量和分类变量
dput(names(bc))##输出变量名
allVars <-c("RIAGENDR", "RIDAGEYR", "RIDRETH1", "DMDMARTL",
"LBDGLUSI", "LBDINSI", "PHAFSTHR",
"LBXGH", "SPXNFEV1", "SPXNFVC", "LBDGLTSI", "oGTT2")###所有变量名
fvars<-c("RIAGENDR", "RIDRETH1","DMDMARTL")#分类变量定义为fvars
绘制表格,我们是使用正常患者、糖尿病前期、糖尿病来分成比较的,所以strata填入oGTT2
Svytab2<- svyCreateTableOne(vars = allVars,
strata = "oGTT2",
data =bcSvy2 ,
factorVars = fvars)
Svytab2

OK,表格已经绘制好了,这里有个问题,婚姻状态有个77不知道是什么东西,所以没有出P值,绘制表格前应提前处理好。
欢迎斧正。
下节聊聊怎么对NHANES数据进行插补。
参考文献:
- NHANES数据库手册
- Survey包说明
- https://mp.weixin.qq.com/s?__biz=MzkyNzI1NTM4Mw==&mid=2247484269&idx=1&sn=29ff5b11ffdea4a68598821b7b7b2d84&chksm=c22b9d55f55c1443f81e2f037a69dcfe11902764c77328b48aa116b32b1522a54bcd46b56225&scene=178&cur_album_id=2033051346194497537#rd
- https://blog.csdn.net/qq_42458954/article/details/121296053
- https://mp.weixin.qq.com/s/O2osOzwRteBQCedxSdhNpQ