CornerNet-Lite论文笔记与代码复现
CornerNet-Lite论文笔记与代码复现
(一)Title

(二)背景知识:Conernet
1、Idea
当今的目标检测算法大多都是基于深度学习模型的,大致可以分为两大门派,一个叫做One-Stage系列,另一个叫做Two-Stage系列。
- Two-Stage系列顾名思义就是两步走:是先由算法生成一系列作为样本的候选框(Region Proposal),再通过卷积神经网络对候选框进行分类回归,典型代表有R-CNN系列;
- One-Stage系列则不用产生候选框,直接将目标边框定位的问题转化为回归问题处理,所以他叫一步走,典型的代表有YOLO系列、SSD系列。正是由于两种方法的差异,在性能上也有不同,前者在检测准确率上占优,后者在算法速度上占优。
上述所讲的两个门派中的一些算法,都用到了anchor这个概念,但是本文的作者认为使用anchor来做目标检测有缺点:anchor的数量太大,参数太多,也就是anchor的设置太讲究了,所以作者就发出了质问,难道一定要用anchor来做目标检测吗??这是作者的第一个思路来源。第二个思路来源是来自一篇姿态估计的文章,这篇文章是基于CNN的2D多人姿态估计方法,通常有2个思路:Top-Down framework:就是先进行行人检测,得到边界框,然后在每一个边界框中检测人体关键点,连接成每个人的姿态,代表算法RMPE(alphapose);Bottom-Up framework:就是先对整个图片进行每个人体关键点的检测,再将检测到的人体部位拼接成每个人的姿态,代表方法就是openpose。
作者基于以上的两个思路,就诞生了:CornerNet: Detecting Objects as Paired Keypoints,重在Keypoints,作者把目标检测问题当作关键点检测问题来解决,检测目标的两个关键点——左上角(Top-left)和右下角(Bottom-right),有了两个点之后,就能确定框了。
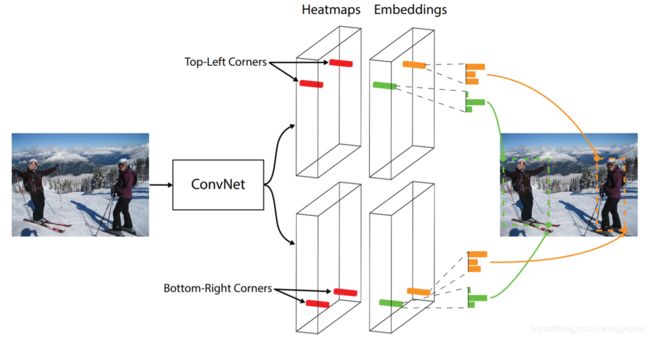
2、算法流程
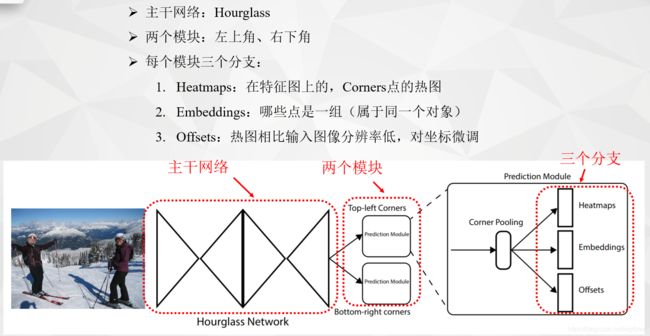
输入图片经过Hourglass主干网络后,得到特征图,然后将该特征图作为两个Prediction模块的输入,分别是Top-left corners和Bottom-right corners。在每个预测模块里面,先经过Corner Pooling,然后输出Heatmaps, Embeddings, Offsets三个分支。heatmaps预测哪些点最有可能是Corners点,embeddings的作用是分清哪些点是一组,最后的offsets用于对点的位置进行修正,因为原图到特征图分辨率已经降低了。
2.1 Backbone
Hourglass-104

原始图片的大小为511×511×3,但这并不是主干网络的输入,主干网络的输入是128×128×256,为什么呢?因为作者是先将512的原图进行缩小四倍,缩小四倍用的操作是先用7×7的卷积核卷积,并且步长为2,通道数为128,这样就缩小两倍了,还有两倍是用了一个残差块,并且步长为2,通道数为256。所以,主干网络真正的的输入是128×128×256,主干网络的输出是128×128×512,为什么分辨率没有变化呢?因为这个主干网络叫做沙漏网络,样子像沙漏,他是先下采样后又上采样,连续堆叠了两个这样的沙漏,过程中经过了特征融合等等,这里总共用了104层。
主干网络出来后,面对的就是两个Module,一个用于预测左上角点,一个用于预测右下角点。
2.2 Prediction Module
以左上角为例:

最后就能得到三个输出:
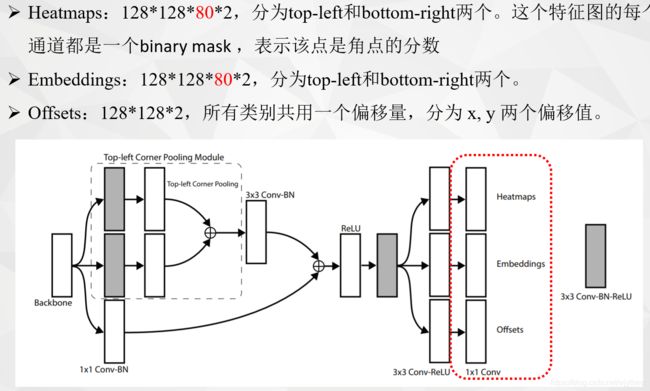
-
Heatmaps:128×128×80×2,128是特征图尺寸,80为coco数据集的类别,2代表top-left和bottom-right两个。
-
Embeddings:128×128×80×2,128是特征图尺寸,80为coco数据集的类别,2代表top-left和bottom-right两个。
-
Offsets:128×128×2,128是特征图尺寸,所有类别共用一个偏移量,2代表x, y 两个偏移值。
2.3 Corner Pooling
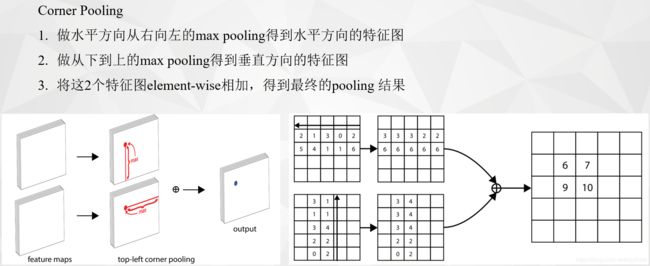
为什么要Corner Pooling?

因为CornerNet是预测左上角和右下角两个角点,但是这两个角点在不同目标上没有相同规律可循,如果采用普通池化操作,那么在训练预测角点支路时会比较困难。考虑到左上角角点的右边有目标顶端的特征信息(第一张图的头顶),左上角角点的下边有目标左侧的特征信息(第一张图的手),因此如果左上角角点经过池化操作后能有这两个信息,那么就有利于该点的预测,这就有了corner pooling。总之就是从左上角点的角度出发:左上角角点的右边有目标顶端的特征信息,左上角角点的下边有目标左侧的特征信息。
3、损失函数

3.1 Headmaps的损失
Heatmaps也就是预测角点的位置。整体上是对focal loss的改进,具体如下图:

几个参数的含义:pcij表示预测的heatmaps在第c个通道(类别c)的(i,j)位置的值,ycij表示对应位置的ground truth。N是图片中目标的总数。ycij=1时候的损失函数容易理解,就是focal loss,α参数用来控制难易分类样本的损失权重;ycij等于其他值时表示(i,j)点不是类别c的目标顶点,照理说此时ycij应该是0(大部分算法都是这样处理的),但是这里ycij不是0,而是用基于ground truth顶点的高斯分布计算得到,因此距离ground truth比较近的(i,j)点的ycij值接近1,这部分通过β参数控制权重,这是和focal loss的差别。
3.2 Embeddings的损失
Embeddings的作用就是配对,将左上角点和右下角点准确配对。简而言之就是基于不同角点的embedding vector之间的距离找到每个目标的一对角点,如果一个左上角角点和一个右下角角点属于同一个目标,那么二者的embedding vector之间的距离应该很小。公式如下图:

3.3 Offsets的损失
这个值和目标检测算法中预测的offset类似却完全不一样,说类似是因为都是偏置信息,说不一样是因为在目标检测算法中预测的offset是表示预测框和anchor之间的偏置,而**这里的offset是表示在取整计算时丢失的精度信息。**在卷积神经网络中存在着下采样层,这样从原始的图像输入到最后的heatmap产生的这个过程会累计误差,特别是在对一些小目标的物体进行检测的时候,这样的误差就无法接受了,因而文章才引入了偏移修正来修正它。也就是下图的公式:

(三)CornerNet-Lite
1、Abstract & Introduce
基于关键点的方法是目标检测中相对较新的范例,消除了对 anchor boxes 的需求并提供了简化的检测框架。基于Keypoint的CornerNet在单级(single-stage)检测器中实现了最先进的精度。
然而,这种准确性来自高处理代价。在这项工作中,解决了基于关键点的高效目标检测问题,并引入了CornerNet-Lite。
CornerNet-Lite是CornerNet的两种有效变体的组合:CornerNet-Saccade,它使用注意机制消除了对图像的所有像素进行彻底处理的需要,以及引入新的紧凑backbone架构的 CornerNet-Squeeze。
CornerNet-Saccade在不牺牲准确性的情况下提高效率,CornerNet-Squeeze在不牺牲效率的情况下提升精度。
本文的贡献:
- 提出CornerNet-Saccade和CornerNet-Squeeze两种提升效率的新网络
- COCO上,我们将最先进的基于关键点的检测效率提高了6倍,AP从42.2%提高到43.2%
- COCO上,实时目标检测的效率提升从(从39毫秒时的33.0%提高到30毫秒时的34.4%)
2、Research Objective
从在保证检测精度前提下,提升检测准确率角度出发,作者提出提升任何目标检测器的效率通常有两个方向:
- 减少处理的像素数量(eg. 降低图像分辨率)
- 减少处理每个像素处理的过程
因此提出本文的两种CornerNet的两种变体:CornerNet-Saccade以及CornerNet-Squeeze,统称为CornerNet-Lite。
CornerNet-Saccade通过减少要处理的像素数量来加速inference。它使用注意力机制,利用完整图像的下采样生成一个attention map,然后放大进行接下来的处理。这与最初的CornerNet不同,因为它是在多个尺度上进行全卷积应用的,通过对高分辨率图像进行裁剪用于检测,将检测结果融合来提升检测准确度,性能表现:每幅图像190毫秒时实现了43.2%的AP,相比于最初的CornerNet,AP提高了1%,速度提高了6倍。
CornerNet-Squeeze通过减少每个像素的处理量来加速推理,结合了 SqueezeNet以及 MobileNets 的观点,引入了一个改进后的hourglass backbone,广泛使用1×1 convolution, bottleneck layer, and depth-wise separable convolution。性能提升:在30ms速度下,AP值可以达到34.4% ,速度上要优于YOLOv3(33%,39ms)
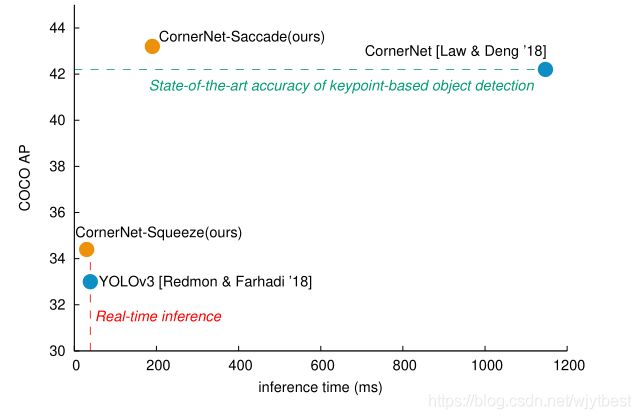
提出这个模型后,有一个很显然的问题就是:结合CornerNet-Saccade和CornerNet-Squeeze能不能实现比CornerNet-Saccade更高的速度,同时比CornerNet-Squeeze更优的准确率呢?
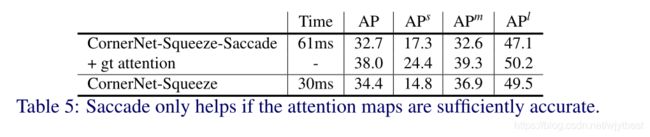
实验结果是:不能,因为CornerNet-Saccade需要生成足够精确的attention map,CornerNet-Squeeze的超紧凑架构没有这种额外的能力。
The results in Tab. 5 suggest that saccade can only help if the attention maps are sufficiently accurate.
3、Backbone
Hourglass-54:consists of 3 hourglass modules and has a depth of 54 layers, while Hourglass-104 in CornerNet consists of 2 hourglass modules and has a depth of 104。
4、Method
4.1 CornerNet-Saccade
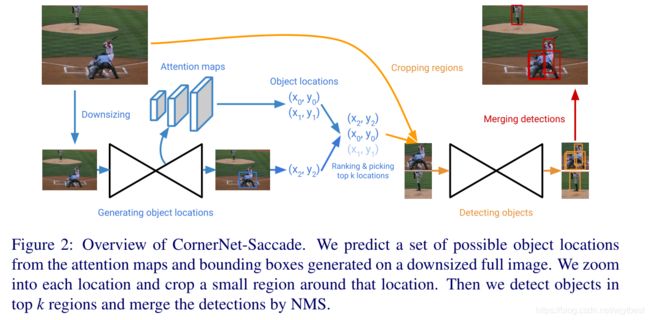
实现步骤:
- 将图像的长边resize到255和192,对于192像素的图像,我们将其零填充到255像素大小上,实现并行处理。
- 利用下采样后的图像在backbone的上采样阶段不同粒度的特征图上预测大、中、小三个尺度(如果一个目标物的较长边的像素小于32,则被视为小目标,32到96的视为中等目标,大于96的是大目标)的目标位置,对于不同大小的目标,可以更好地"针对性处理(放大)",对于不同尺度的目标采用不同的放大倍数,由于使用了下采样,对于一些小目标可能无法准确检测,因此,我们应该基于在第一步中获得的尺度(scale)信息在更高的分辨率上检查区域。
- 在生成attention map的同时,会在图像中给大目标预测boxes,但是这些boxes不是很准确,同样需要放大来获取更好的boxes。
- 在完成可能目标位置的目标检测之后,裁剪图像中的bounding boxes进行NMS,同时手动删除掉由于裁剪而导致的只有一部分的目标的boxes。

当我们对区域进行裁剪的时候,这个区域可能包含包含一部分物体在裁剪边界,或者当物体靠的很近时,产生的region重叠程度很高,处理两个区域是不可取的,因为处理其中一个区域可能会检测到另一个区域中的目标。
4.2 CornerNet-Squeeze
CornerNet-Saccade通过关注子区域的像素来减少处理量。CornerNet-Squeeze减少每个像素处理过程中的计算量。CornerNet中,计算量主要消耗在Hourglass-104上,虽然Hourglass-104的性能好,但是,其参数量大,而且inference时间长。本文借鉴了SqueezeNet及MobileNet的思想来设计一个轻量级的Hourglass结构。
使用SqueezeNet中的fire module代替残差模块,并借助MobileNet的思想利用深度可分离卷积代替标准卷积。
网络的其他变动:
- Hourglass Module之前增加一个下采样层来降低Hourglass Module特征图的最大分辨率
- 移除每个hourglass模型中的一个下采样层
- CornerNet-Squeeze在hourglass 模型之前下采样3次,而CornerNet只下采样两次。
- 将CornerNet预测模块中的3x3卷积替换为1x1的卷积
- 将hourglass网络中最相邻的上采样层替换为4x4的转置卷积。
5、Experiments
5.1 GPU memory

5.2 Hourglass Network-54 vs Hourglass Network-104 (+ attention map)
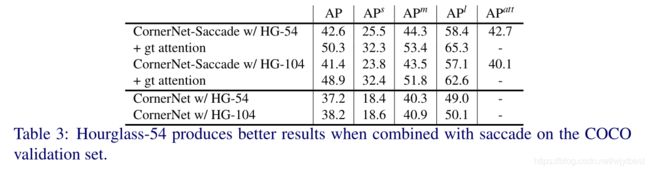
疑惑:在CornerNet-Saccade中,为什么54会比104的AP值高?
5.3 CornerNet–>CornerNet-Squeeze
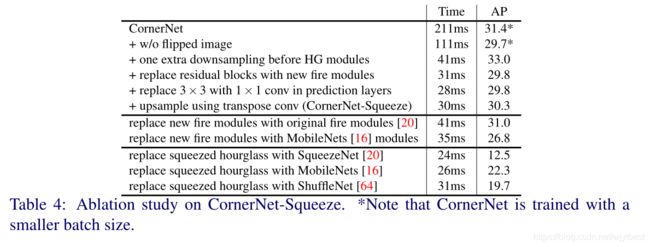
5.4 CornerNet、CornerNet-Lite vs YOLOv3
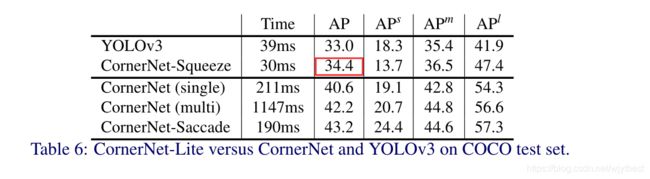
小目标差了点,其他都比YOLOv3好。
(四)代码复现
1、环境:
windows 10, python 3.7, CUDA 10.0+cudnn 7.6.2, pytorch 1.0、vs2019
2、安装minGW、用于windows下的make:
下载地址:
https://sourceforge.net/projects/mingw/files/latest/download?source=files
下载完后安装,全勾选,进入程序页面如下:
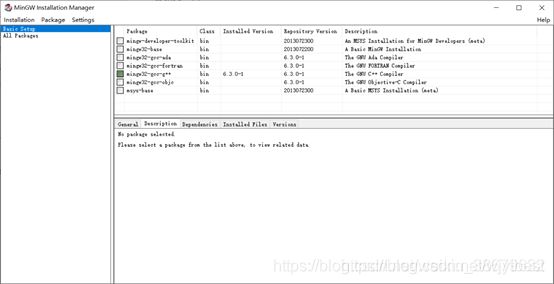
点左边的all packages,安装mingw32-gcc-g++和mingw32-make,class都为bin。
安装方法是勾选,然后左上角installation点apply。
安装需耐心等待。
进入mingw的安装目录,例如我的是C:\MinGW,进入bin文件夹,找到mingw-make.exe,将其名字改为make.exe。
将make加入系统变量path。
3、编译程序依赖项
进入<你的程序文件夹>/core/models/py_utils/_cpools/src 下,会有四个cpp文件,用记事本打开,将第一行#include
改成:
#include
四个文件都要改。
完成之后打开anaconda prompt
cd <你的程序文件夹>/core/models/py_utils/_cpools/
python setup.py install --user
打开<你的程序文件夹>/core/external
打开setup.py,注释掉两句话如下:
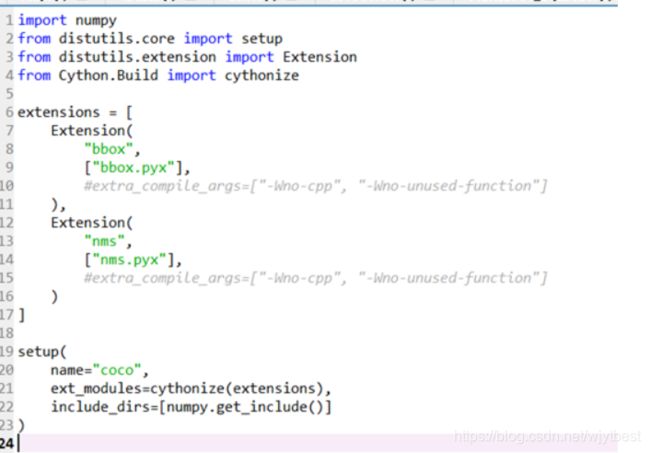
保存。
用cmd命令行进入这个文件夹,执行如下命令:
make
如果缺少相关.dll文件,网上搜索之并下载放到该文件即可。
4、下载权重
下载完成后放到<你的程序文件夹>/cache/nnet/CornerNet_Saccade/下,注意这里需要你手动新建文件夹。
5、运行
运行demo.py,如果成功应该在文件夹下出现demo_out.jpg。

6、对比



(五)Questions
1、在密集物体或遮挡物体检测上,Connernet-Lite的效果并不好,为什么?
2、有没有比hourglass效果更好的网络可以替换?
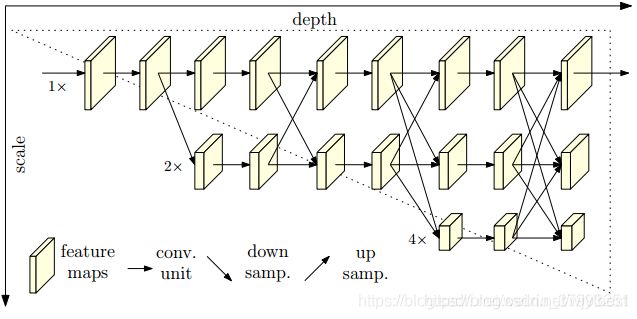
高分辨率网络(HRNet)
HRNet通过并行连接高分辨率到低分辨率卷积来保持高分辨率表示,并通过重复跨并行卷积执行多尺度融合来增强高分辨率表示。据说比Hourglass好,没试过。