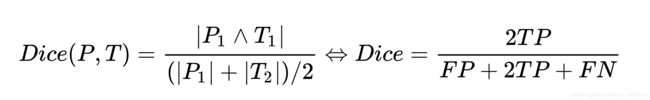U-Net图像分割知识整理
图像分割
什么是图像分割问题呢?简单的来讲就是给一张图像,检测是用框出框出物体,而图像分割分出一个物体的准确轮廓。可以这样考虑,给出一张图像L,这个问题就是求一个函数,从L映射到Mask。至于怎么求这个函数有多种方法。我们可以看到这个图,左边是给出图像,可以看到人和摩托车,右边是分割结果。

图像分割中几种定义:
语义分割(Semantic Segmentation):就是对一张图像上的所有像素点进行分类。(eg: FCN/Unet/Unet++/…)
实例分割(Instance Segmentation):可以理解为目标检测和语义分割的结合。(eg: Mask R-CNN/…) 相对目标检测的边界框,实例分割可精确到物体的边缘;相对语义分割,实例分割需要标注出图上同一物体的不同个体。
全景分割(Panoptic Segmentation):可以理解为语义分割和实例分割的结合。实例分割只对图像中的object进行检测,并对检测到的object进行分割;全景分割是对图中的所有物体包括背景都要进行检测和分割。
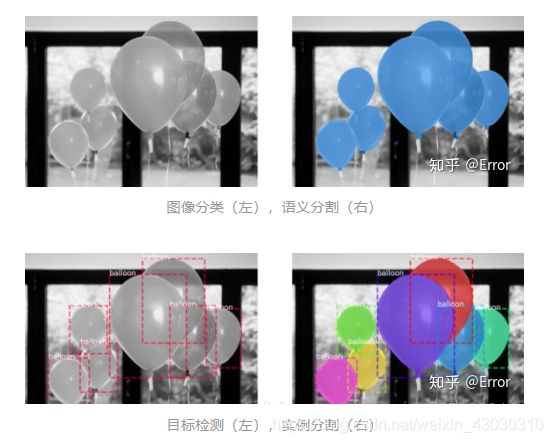
图像分类:图像中的气球是一个类别。
语义分割:分割出气球和背景。
目标检测:图像中有7个目标气球,并且检测出每个气球的坐标位置。
实例分割:图像中有7个不同的气球,在像素层面给出属于每个气球的像素。
FCN
求这个函数有很多方法,但是第一次将深度学习结合起来的是全卷积网络(FCN),利用深度学习求这个函数。在此之前深度学习一般用在分类和检测问题上。由于用到CNN,所以最后提取的特征的尺度是变小的。和我们要求的函数不一样,我们要求的函数是输入多大,输出有多大。为了让CNN提取出来的尺度能到原图大小,FCN网络利用上采样和反卷积到原图像大小。然后做像素级的分类。
可以看图,输入原图,经过VGG16网络,得到特征map,然后将特征map上采样回去。再将预测结果和ground truth的每个像素一一对应分类,做像素级别分类。也就是说将分割问题变成分类问题,而分类问题正好是深度学习的强项。如果只将特征map直接上采样或者反卷积,明显会丢失很多信息。
FCN采取解决方法是将pool4、pool3、和特征map融合起来,由于pool3、pool4、特征map大小尺寸是不一样的,所以融合应该前上采样到同一尺寸。这里的融合是拼接在一起,不是对应元素相加。
FCN是深度学习在图像分割的开山之作,FCN优点是实现端到端分割等,缺点是分割结果细节不够好,可以看到图四,FCN8s是上面讲的pool4、pool3和特征map融合,FCN16s是pool4和特征map融合,FCN32s是只有特征map,得出结果都是细节不够好,具体可以看自行车。由于网络中只有卷积没有全连接,所以这个网络又叫全卷积网络。
U-Net
U-Net主要用于医学图像分割(也可以用于自然图像生成)
医学图像特点:
- 语义简单,结构固定
- 数据量少,参数设置不能多
- 多模态,复杂度高
- 灰度大,边界不清晰
- 内部结构相对固定,同时分割目标在人体图像中分布很有规律
由于医学图像有边界不清晰的特点,就需要高分辨率信息来精准分割;由于它内部结构固定有规律,就只需要低分辨率信息就能够识别物体。
U-Net结合了低分辨率信息(提供物体识别依据)和高分辨率信息(提供精准分割定位依据),同时U-Net模型较小,参数也少,也很符合医学图像数据量少的特点。
U-Net网络结构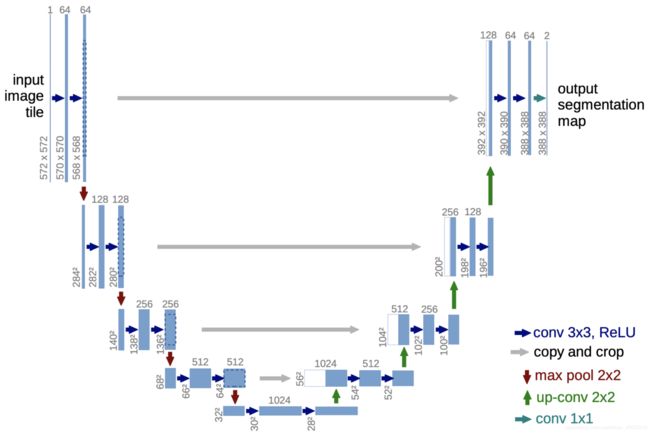
可以分为两个部分(左:特征提取部分,右:上采样部分)或三个部分(左:特征提取部分,中:skip connect,右:上采样部分)
左(特征提取部分):它是一个收缩网络,通过四次下采样,使图片尺寸减小,在这不断下采样的过程中,特征提取到的是浅层信息。具体过程是,输入图片然后经过两个卷积核(3x3后面紧跟着一个Relu)以论文原图为例:输入572x572,经过两个卷积核(大小为3x3)大小从572-570-568,然后经过一个Maxpool(2x2)图片尺寸变为284这即为一个完整的下采样,接下来三个也是如此。在下采样的过程中,图像大小-2-2再除2,通道数翻倍,例如图上的从64-128。通道数从1->64->64,是通过调整卷积核数量造成的。
中(skip connect):在论文中叫拼接copy and crop,在UNet有四个拼接操作。如上图所示:这一操作的目的是为了融合特征信息,使深层和浅层的信息融合起来。在拼接的时候要注意,不仅图片大小要一致(故要crop,是为了使图片大小一致)而且特征的维度(channels)也要才一样,才可以拼接。因为crop只保留中间的一部分,所以边缘信息会消失。
右(上采样部分):也叫扩张网络,图片尺寸变大,提取的是深层信息,使用了四个上采样,在上采样的过程中,图片的通道数是减半的,与左部分的特征提取通道数的变化相反。在上采样的过程融合了左边的浅层的信息即拼接了左边的特征。上采样的操作是反卷积Deconvolution,或者转置卷积(Transposed Convolution),它可以使输出图像尺寸大于输入图像的尺寸。转置卷积常常用于CNN中对特征图进行上采样,比如语义分割和超分辨率任务中。之所以叫转置卷积是因为,它其实是把我们平时所用普通卷积操作中的卷积核做一个转置,然后把普通卷积的输出作为转置卷积的输入,而转置卷积的输出,就是普通卷积的输入。
网络中的3×3卷积,valid,stride为1,图像大小-2, reLU
2×2max pooling,valid,stride为2,图像大小减半
最后一层1×1卷积,由2个1×1×64的卷积核,输出2个通道的图(背景和前景),然后通过softmax进行分类。卷积核的数量==输出特征图的数量(输出图像通道数)
浅层结构可以抓取图像的一些简单的特征,如边界、颜色。
深层结构感受野大,抓取到一些更高层的抽象的特征,如一段圆弧
U-Net是对称的结构,可以把它看成是Encoder-Decoder结构。图像会先经过Encoder处理,再经过Decoder处理,最终实现图像分割。它们分别的作用如下:
Encoder:使得模型理解了图像的内容,但是丢弃了图像的位置信息。
Decoder:使模型结合Encoder对图像内容的理解,恢复图像的位置信息。
Encoder的部分和传统的网络结构类似,可以选择图中的结构,也可以选择VGG,ResNet等。随着卷积层的加深,特征图的长宽减小,通道增加。虽然Encoder提取了图像的高级特征,但是丢弃了图像的位置信息。所以在图像识别问题中,模型只需要Encoder的部分。因为图像识别不需要位置信息,只需要提取图像的内容信息。
Decoder的部分是Unet的重点。Decoder中涉及upconvolution这个概念,简单来说就是convolution的反向运算。Decoder的每一层都通过upconvolution(图中绿色箭头),并且和Encoder相对应的初级特征结合(图中的灰色箭头),逐渐恢复图像的位置信息。在Decoder中,随着卷积层的加深,特征图的长宽增大,通道减少。
医学图像是一般相当大,但是分割时候不可能将原图太小输入网络,所以必须切成一张一张的小patch,在切成小patch的时候,Unet由于网络结构原因适合有overlap的切图,可以看图,黄框是要分割区域,但是在切图时要包含周围区域,overlap另一个重要原因是周围overlap部分可以为分割区域边缘部分提供文理等信息。可以看黄框的边缘,分割结果并没有受到切成小patch而造成分割情况不好。这张图代表了任意大图像的无缝分割的重叠拼贴策略,对黄色区域中的分割的patch预测需要蓝色区域内的图像数据作为输入。 丢失的输入数据通过镜像补充。
图像分割评价指标
Dice
对于分割过程中的评价标准主要采用Dice相似系数(Dice Similariy Coefficient,DSC),Dice系数是一种集合相似度度量指标,通常用于计算两个样本的相似度,值的范围0-1,分割结果最好时值为1 ,最差时值为0。