【论文笔记】Towards Universal Sequence Representation Learning for Recommender Systems
论文详细信息
题目:Towards Universal Sequence Representation Learning for Recommender Systems
作者:Yupeng Hou and Shanlei Mu and Wayne Xin Zhao and Yaliang Li and Bolin Ding and Ji-Rong Wen
期刊/会议:Proceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD '22)
时间:2022
领域:Recommendation System
关键词:Sequential, Recommender, Pre-train
代码
背景与动机
目前已有工作存在的问题及原因?
现有的序列推荐的核心方法:
- 将用户行为表示为按时间顺序排列的交互物品序列,然后构建模型捕捉用户偏好的变化特征。这种方法本质上依赖于用户的历史行为数据,用物品ID表示整个物品的特征,且模型的序列长度直接影响推荐性能。
现有的序列表示学习(SRL)方法都依赖于将物品ID显式建模来开发序列模型,这样会导致:
- 即使数据类型一样,模型很难迁移到新的推荐场景(数据集)中,因为物品的ID在不同的推荐场景肯定是不一致的;
- 不同的场景重新训练模型会受到数据量的限制;
- 基于ID的序列推荐会受到冷启动问题的困扰。
已经有一些工作:
- 语义映射(p.s. 将不同推荐场景下的物品表示映射到同一个空间来对齐)
- 可移植组件(p.s. 没太懂具体是什么)
一些工作利用自然语言来将连接不同的领域或任务,如零次推荐。
[1] Hao Ding, Yifei Ma, Anoop Deoras, Yuyang Wang, and Hao Wang. 2021. Zero-Shot Recommender Systems. arXiv preprint arXiv:2105.08318 (2021).
[2] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In NAACL.
切入点和难点?
利用物品的相关文本描述来作为可迁移的物品表示,因为文本语义在不同的推荐场景中是不会有太大变化的(e.g. 淘宝上的”内存条“和京东上的”内存条“指的是同一种物品)。
- 但对于文本来说,文本所在的语义空间并不适合直接进行推荐(p.s. 直接根据文本没有办法进行推荐,因为文本和用户不在一个层面上,且文本不一定直接对应某些物品,例如直接把”red“推荐给用户显然是不可行的)。
It is not clear how to model and utilize item texts for improving the recommendation performance, since directly introducing raw textual representations as additional features may lead to suboptimal results.
按理说将文本表示和ID嵌入拼接或相加都能在一定程度上提升性能,可能作者意思是没有好的模型“直接用文本进行推荐 ”,也就是说还是需要ID才好推荐。
- 如果利用很多个不同领域的数据来改进目标领域(即用不同的数据集来对目标数据集进行数据增强)会导致跷跷板效应,因为有些数据集可能存在冲突。
同时,文中提到越来越多的工作证明自然语言可以作为一种通用的数据形式来连接不同的任务和不同域之间的语义差异。
解决方案的关键是什么?
提出了一个基于预训练的学习物品的“ID不可知(ID-agnostic)表示” 的通用序列表示学习方法,特别关注学习通用物品表示和通用序列表示(universal item representation and universal sequence representations)。两种任务:
- For learning universal item representations, we design a lightweight architecture based on parametric whitening and mixture-of-experts enhanced adaptor, which can derive more isotropic (各向同性的,等方向性的) semantic representations as well as enhance the domain fusion and adaptation.
- For learning universal sequence representations, we introduce two kinds of contrastive learning tasks, namely sequence-item and sequence-sequence contrastive tasks, by sampling multi-domain negatives.
各向同性和各向异性
各向异性(anisotropy)是一个几何性质,在向量空间上的含义就是分布与方向有关系,语义向量挤在了一个狭窄的锥形空间内,这样向量彼此的余弦相似度都很高,并不是很好的表示,而各向同性(isotropy)就是各个方向都一样,分布均匀。各向异性被认为是导致 PLM 在各下游任务中只能达到次优性能(表示退化问题)的一个重要因素,不过各向同性技术可以用来调整嵌入向量空间,而且使模型在众多任务上的性能都获得了极大的提升。
方法及实验
输入
方法输入通用序列s
s = { i 1 , i 2 , . . . , i n } ; i = { I D i , t e x t i } ; t e x t i = { w 1 , w 2 , . . . , w c } ; w h e r e w j ∈ { v o c a b u l a r y } ; s=\{i_1,i_2,...,i_n\};i=\{ID_i,text_i\};text_i=\{w_1,w_2,...,w_c\}; \\where \\w_j\in\{vocabulary\}; s={i1,i2,...,in};i={IDi,texti};texti={w1,w2,...,wc};wherewj∈{vocabulary};
每个序列表示一名用户在某一个特定域中的所有交互行为,因为不同域(数据集)的语义存在差异,因此对于同一名用户在不同的域中的交互行为用不同的序列表示,而且这些序列不明确标注用户ID。而且此处的物品ID只是辅助信息,除非指定需要,否则不作为输入的一部分。
为了学习跨域可迁移表示,论文提出了两个关键问题,即学习通用物品表示和通用序列表示,因为物品和序列是序列推荐中的基本数据形式。
对于学习物品通用表示在原文的Section2.2,而学习通用序列表示在Section2.3,在此基础上使预训练模型能够通过一种参数高效(parameter-efficient)的方式转移到一个新的推荐场景中,either inductive or transductive。
Inductive:训练集与测试集之间是相斥的,即测试集中的任何信息是没有在训练集中出现过的。即模型本身具备一定的通用性和泛化能力。
Transductive:相比Inductive learning, Transductive learning拥有着更广的视角,在模型训练之初,就已经窥得训练集(带标签)和测试集(不带标签),尽管在训练之时我们不知道测试集的真实标签,但可以从其特征分布中学到些额外的信息(如分布聚集性),从而带来模型效果上的增益。但这也就意味着,只要有新的样本进来,模型就得重新训练。
- 文中的transductive的意思是物品的ID已经给出了,而只需要通过物品预先给出ID学习embeddding就行。但是这样就限制了模型的迁移性,因为在不同数据集中物品ID肯定是不同的。
具体模型和算法
- PLM学习通用文本嵌入
- CL学习通用序列表示
- 固定参数仅微调MoE参数
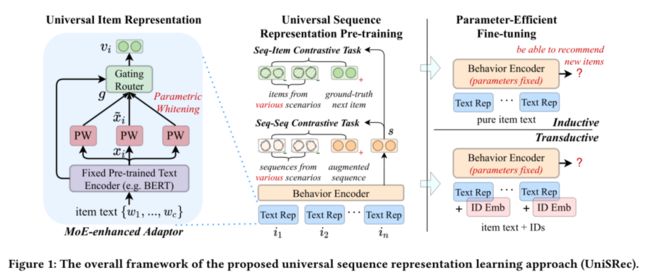
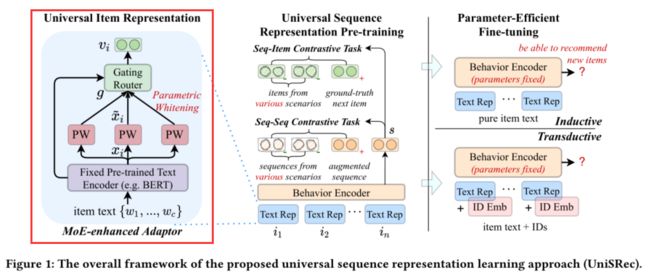
学习通用文本嵌入Universal Textual Item Representation
-
BERT的输入:对于每个物品 i t e m : i item:i item:i,将 [ C L S ] [CLS] [CLS]其对应的文本 c o r r e s p o n d i n g _ t e x t : t i corresponding\_text:t_i corresponding_text:ti拼接之后输入BERT,在[CLS]对应的输出位置得到文本嵌入
x i = B E R T ( [ [ C L S ] ; w 1 , . . . , w c ] ) , x_i=BERT([[CLS];w_1,...,w_c]), xi=BERT([[CLS];w1,...,wc]), -
Semantic Transformation via Parametric Whitening
Existing studies [3] have found that BERT induces a non-smooth anisotropic semantic space for general texts. The case will become more severe when we mix item texts from multiple domains with a large semantic gap.
因为BERT会导致各向异性,将本身就存在语义鸿沟的不同域文本混合时会加剧这种各向异性,根据已有工作,基于白化的方法可以缓解这种问题,于是文中提出了一种与现有方法不一样的白化方法(p.s. 就是简单的线性映射,文中无证明地说是为了在未见域上有更好地泛化性):
x i ˜ = ( x i − b ) ⋅ W 1 \~{x_i}=(x_i-b)\cdot W_1 xi˜=(xi−b)⋅W1
白化
在一些算法中还需要一个与之相关的预处理步骤,这个预处理过程称为白化(一些文献中也叫 sphering)。
举例来说,假设训练数据是图像,由于图像中相邻像素之间具有很强的相关性,所以用于训练时输入是冗余的。白化的目的就是降低输入的冗余性;更正式的说,我们希望通过白化过程使得模型的输入:
(1)特征之间相关性较低(协方差为0)
(2)所有特征具有相同的方差
[3] Bohan Li, Hao Zhou, Junxian He, Mingxuan Wang, Yiming Yang, and Lei Li. 2020. On the Sentence Embeddings from Pre-trained Language Models. In EMNLP.
- Domain Fusion and Adaptation via MoE-enhanced Adaptor
即使是通过同一个BERT得到的文本嵌入,不同的域得到的文本表示还是可能不在一个语义空间中(因为不同的数据集中的文本语料不一致,e.g., natural, sweet, fresh for food domain and war, love, story for movies domain)。
而各个语义空间存在语义鸿沟,所以需要融合不同域的信息。直接将所有文本映射到一个公共空间会限制表达能力,因为各个域的特点会被抹除掉(原文:However, it will lead to limited representation capacity for migrating the domain bias.)。
因此文中提出对每个商品学习多个参数白化表示,并自适应融合成通用的商品表示。具体来说,使用G个白化模块作为expert,然后加权求和。:
v i = ∑ k = 1 G g k ⋅ x i ˜ ( k ) w h e r e g = S o f t m a x ( x i ⋅ W 2 + δ ) , δ = N o r m ( ) . S o f t p l u s ( x i ⋅ W 3 ) , S o f t p l u s ( x ) = log ( 1 + e x ) v_i=\sum_{k=1}^{G}g_k\cdot \~{x_i}^{(k)}\\ where\\ g=Softmax(x_i\cdot W_2+\delta),\\ \delta=Norm().Softplus(x_i\cdot W_3),\\ Softplus(x)=\log(1+e^x) vi=k=1∑Ggk⋅xi˜(k)whereg=Softmax(xi⋅W2+δ),δ=Norm().Softplus(xi⋅W3),Softplus(x)=log(1+ex)
注意到,在g的计算公式中用到的是BERT的原始输出 x x x而不是白化后的输出 x ˜ \~{x} x˜,因为其携带着领域相关的语义偏置,为了 experts 间的负载均衡,使用 N o r m ( ) Norm() Norm()来生成随机高斯噪声。
MoE-enhanced Adaptor有如下三个优点:
(1)单个商品的表示可以由学习多个参数白化网络而增强;
(2)无需在域之间进行直接的语义映射,而是使用一个可学习的门控单元来自适应地建立语义联系,从而可以更好地进行领域融合与适配;
(3)这个轻量化的适配器模块便于后续进行参数高效的微调。
The merits of the MoE-enhanced adaptor are threefold.
Firstly, the representation of a single item is enhanced by learning multiple whitening transformations.
Second, we no longer require a direct semantic mapping across domains, but instead utilize a learnable gating mechanism to adaptively establish the semantic relatedness for domain fusion and adaptation.
Third, the lightweight adaptor endows the flexibility of parameter-efficient fine-tuning when adapting to new domains
通用序列嵌入Universal Sequence Representation
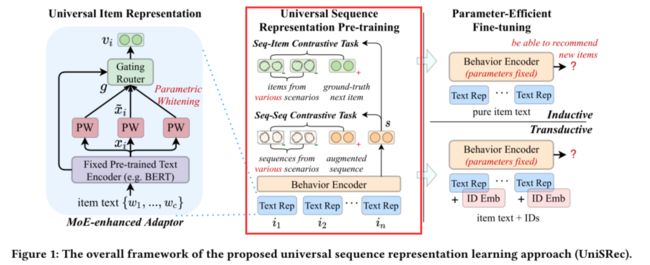
在设计了这种通用商品表示方法后,在架构层面已经可以使用同一个序列模型建模不同推荐场景的商品了。
但是由于不同的域通常对应着不同的用户行为模式,简单地把这些不同领域的序列混合起来使用并不会取得很好的效果。这可能会导致跷跷板效应,即从多个域学到的行为模式可能会是互相冲突的。
为此文中提出了两种基于对比学习的任务用于预训练,希望可以进一步促进不同域之间的融合与适配。
-
Self-attentive Sequence Encoding
通过自注意力机制(Transformer)编码用户行为的物品序列(p.s. 就是传统的,先加入位置编码,然后多头注意力+多层感知机):
f j 0 = v i + p j , F l + 1 = F F N ( M H A t t ( F l ) ) , w h e r e F l = [ f 0 l ; . . . ; f n l ] f_j^0=v_i+p_j,\\ F_{l+1}=FFN(MHAtt(F^l)),\\ where\\ F^l=[f^l_0;...;f^l_n] fj0=vi+pj,Fl+1=FFN(MHAtt(Fl)),whereFl=[f0l;...;fnl]
F l F^l Fl就是第 l l l层的各个位置的表示拼接起来,最后取最后一层的最后一个位置的向量 f n L f^L_{n} fnL作为序列的表示。 -
Multi-domain Sequential Representation Pre-training
两个对比任务:Sequence-Item & Sequence-Sequence
对于Sequence-Item对比而言,就是将序列下一时刻物品的真实值作为正样本,将其它域中的物品作为负样本(而不是当前域的其他物品):
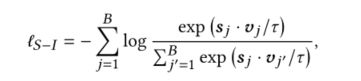
对于Sequence-Sequence对比,先对原序列进行增强,即随机丢到序列中的物品或物品文本中的单词。
We consider two kinds of augmentation strategies: (1) Item drop refers to randomly dropping a fixed ratio of items in the original sequence, and (2) Word drop refers to randomly dropping words in item text.
然后将增强的序列作为正样本,其他多个域序列作为负样本:
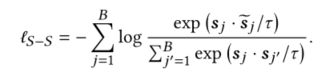
Multi-task Learning
将两种对比学习以多任务学习的方式进行联合优化:
L P T = ℓ S − I + λ ⋅ ℓ S − S \mathcal{L}_{PT}=\ell_{S-I}+\lambda\cdot\ell_{S-S} LPT=ℓS−I+λ⋅ℓS−S
Parameter-Efficient Fine-tuning
为了让模型更好地适应新的域,文中提出固定主要架构的参数,仅微调MoE的一小部分参数,而不是像现有的推训练模型微调整个网络。同时文中考虑了两种微调设置,inductive setting和transductive setting。
-
Inductive setting,即对新的域进行推荐,这时候基于ID的推荐模型就无法解决迁移问题,因此只用通用文本表示来进行微调训练,首先将序列和候选物品编码到通用表示 s , i i + 1 s,i_{i+1} s,ii+1,然后预测候选集中的物品是下一个物品的概率:
P I ( i t + 1 ∣ s ) = S o f t m a x ( s ⋅ v i t + 1 ) P_I(i_{t+1}|s)=Softmax(s\cdot v_{i_{t+1}}) PI(it+1∣s)=Softmax(s⋅vit+1)
然后根据这个预测仅仅调整参数白化中的可学习参数(原文中的等式2的b和W) -
Transductive setting,即近乎所有物品都在训练集出现的场景。这个时候可以加入物品的ID表示来进行预测:
P T ( i t + 1 ∣ s ) = S o f t m a x ( s ˜ ⋅ ( v i t + 1 + e i t + 1 ) ) P_T(i_{t+1}|s)=Softmax(\~{s}\cdot(v_{i_{t+1}}+e_{i_{t+1}})) PT(it+1∣s)=Softmax(s˜⋅(vit+1+eit+1))
其中 s ˜ \~{s} s˜表示加入了ID表示的物品序列(也就是原文中的等式7加入ID表示),即物品由文本和ID相加得到。
在两种设置中都通过交叉熵损失来微调,且序列编码器的参数固定,仅更新MoE的参数
实验结果
为了验证 UniSRec 的迁移性,文中采用了跨域和跨平台两种实验设置。具体来说,将 Amazon 2018 数据集的 5 个 域(Food, Home, CDs, Kindle, Movies)用于预训练,并将这一个预训练的 UniSRec 模型在各个下游数据集上微调。注意预训练数据与下游的六个数据集均可以看作没有用户 / 物品重叠。
下游数据集分为两类:
- 跨域数据集:Amazon的另五个较小的数据集作为跨域数据集
Pantry, Scientific, Instruments, Arts, Office - 跨平台数据集:英国电商数据集 Online Retail 作为新平台数据集
整体性能比较

预训练数据集对微调数据集的性能影响
Figure2
各个模块的消融实验
Figure3
对长尾物品的性能提升
Figure4
提供了哪些思路?
论文提出一种新的序列表示学习方法 UniSRec,希望打破显示建模物品 ID 带来的限制,编码物品文本并生成迁移性强的通用物品表示,并进一步在多个域上预训练来学习到通用序列表示。