FCN的代码解读
目录
模型初始化
VGG初始化
FCN初始化
图片的预处理
图片处理
图片编码
计算相关参数
模型训练
一个小问题
完整代码
参考
最近浅研究了一下关于图像领域的图像分割的相关知识,发现水还是挺深的,因为FCN差不多也是领域的开山鼻祖,所以就先从这个方面入手。理论就不多讲很多了,网上一搜一大堆,主要就是解析一下代码部分。
模型初始化
众所周知,FCN的后半段是新的,前半段一般移植自其他模型,这里我选择了Vgg16的模型结构。所以模型初始化分为两步,首先是对Vgg网络的初始化,然后是对Fcn网络的初始化。
VGG初始化
这里为了方便Vgg的选择将几个不同的Vgg封装在了列表中,以数字代表卷积后的输出通道数,卷积的输入通道数也就是前一个的输出通道数,M代表池化层,Vgg采用的都是卷积核为3的卷积层和大小为2的池化层核,所以这两个参数为已知无需标注。
还需要注意的是因为Fcn是全卷积网络,所以是不需要最后的全连接层的,所以去掉。
# Vgg网络结构配置(数字代表经过卷积后的channel数,‘M’代表池化层)
cfg = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
# 由cfg构建vgg-Net的卷积层和池化层(block1-block5)
def make_layers(cfg, batch_norm=False):
layers = []
in_channels = 3 # RGB初始值
for v in cfg:
if v == 'M': # 池化层
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm: # 是否需要归一化
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v # 这一层输出的通道数就是下一层输入的通道数
return nn.Sequential(*layers)
# 下面开始构建VGGnet
class VGGNet(VGG):
def __init__(self, pretrained=True, model='vgg16', requires_grad=True, remove_fc=True, show_params=False):
super().__init__(make_layers(cfg[model]))
self.ranges = ranges[model] # ranges是一个字典,键是model名字,后面的是池化层的信息
# 获取VGG模型训练好的参数,并加载(第一次执行需要下载一段时间)
if pretrained:
exec("self.load_state_dict(models.%s(pretrained=True).state_dict())" % model)
# 屏蔽预训练模型的权重,只训练最后一层的全连接的权重,因为fcn模型是建立在vgg16基础上训练的,所以前面训练好的VGG网络不修改
if not requires_grad:
for param in super().parameters():
param.requires_grad = False
# 去掉vgg最后的全连接层(classifier)
if remove_fc:
del self.classifier
# 打印网络的结构
if show_params == True:
for name, param in self.named_parameters():
print(name, param.size())
def forward(self, x):
output = {}
# 利用之前定义的ranges获取每个max-pooling层输出的特征图,这个主要是FCN32的上采样要用到
for idx, (begin, end) in enumerate(self.ranges): # enumerate用于枚举,同时给出元素和下标
# self.ranges = ((0, 5), (5, 10), (10, 17), (17, 24), (24, 31)) (vgg16 examples)
for layer in range(begin, end):
x = self.features[layer](x)
# 相当于把x矩阵放进layer层,然后得到输出,0-5代表第一个max-pool需要经过的层数,所以x1实际上就是第一个max-pool层输出
output["x%d" % (idx + 1)] = x
# x数字越大越深
# output 为一个字典键x1d对应第一个max-pooling输出的特征图,x2...x5类推
return outputFcn8s是需要融合前面3个池化层信息的,所以需要将Vgg模型的池化层信息记录下来,这也是foward在做的事情,可以看到这串代码实际上就是取出一串卷积层加上最后的池化层,做完之后把结果存储到字典中,最后output中存储的就是几个池化层的信息(因为每次都是以池化层为结束)。
FCN初始化
然后是关于FCN网络的初始化。FCN下有FCN32s,FCN16s,FCN8s,如下图:
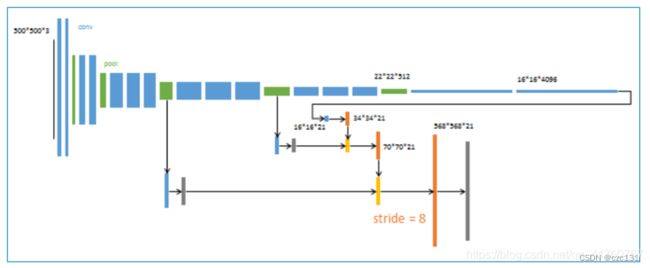
这是FCN8s,因为融合了不同深度的池化层的信息,因而相比直接输出对边缘处理会更加丝滑,因为浅的抽象层次往往对细节有着更好理解。但是作者也说了,并不是融合的越多越多好,Fcn4s相比并没有很大的精度提高,因此也是适可而止,因此下面就直接做Fcn8s。
# 下面由VGG构建FCN8s
class FCN8s(nn.Module):
def __init__(self, pretrained_net, n_class):
super().__init__()
# 定义可能会用到的东西
self.n_class = n_class
self.pretrained_net = pretrained_net
self.conv6 = nn.Conv2d(512, 512, kernel_size=1, stride=1, padding=0, dilation=1)
self.conv7 = nn.Conv2d(512, 512, kernel_size=1, stride=1, padding=0, dilation=1) # 卷积核大小是1,本质上是全连接层
# 这里写两个一样的可能是为了写出前后关系的感觉?
self.relu = nn.ReLU(inplace=True)
self.deconv1 = nn.ConvTranspose2d(512, 512, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn1 = nn.BatchNorm2d(512)
self.deconv2 = nn.ConvTranspose2d(512, 256, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn2 = nn.BatchNorm2d(256)
self.deconv3 = nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.deconv4 = nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn4 = nn.BatchNorm2d(64)
self.deconv5 = nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn5 = nn.BatchNorm2d(32)
self.classifier = nn.Conv2d(32, n_class, kernel_size=1)
def forward(self, x):
output = self.pretrained_net(x)
# 这个已经在前面的forward中初始化了,里面已经存储了相关特征图
x5 = output['x5'] # max-pooling5的feature map (1/32) 5*5,160/32
# print(x5.size())
x4 = output['x4'] # max-pooling4的feature map (1/16)
x3 = output['x3'] # max-pooling3的feature map (1/8)
# 所以总结一下FCN里面的几个合成的步骤也就是反卷积->激活->标准化->加上前面的pool层继续
score = self.relu(self.conv6(x5)) # conv6 size不变 (1/32)
# score = self.relu(self.conv7(score)) # conv7 size不变 (1/32)
# 这里我尝试把右边括号里的x5改成了score
score = self.relu(self.deconv1(score)) # out_size = 2*in_size (1/16)
# print(score.size()) # 反卷积之后变为两倍
score = self.bn1(score + x4) # bn是标准化,表示加x4第二池化层的结果一同进行计算
score = self.relu(self.deconv2(score)) # out_size = 2*in_size (1/8)
score = self.bn2(score + x3)
# 到这里为止就是全部的FCN步骤,接下来是反卷积到原尺寸
# 此时是1/8,然后继续反卷积,每次扩大两倍边长直到最后和原图一样
score = self.bn3(self.relu(self.deconv3(score))) # out_size = 2*in_size (1/4),反卷积后标准化
score = self.bn4(self.relu(self.deconv4(score))) # out_size = 2*in_size (1/2)
score = self.bn5(self.relu(self.deconv5(score))) # out_size = 2*in_size (1)
score = self.classifier(score) # size不变,使输出的channel等于类别数,相当于对每个点分类
return score因为代码是取自其他博主,因而在阅读过程中也遇到了一些问题,原代码对于score的处理如下,但是可以看到第一句和第二句对score处理了之后在第三句又对score重新赋值,这就代表了什么,前两句是无效的,这也是我疑惑的地方,后来我也去参考了一下这位博主参考的githug源码,猜想应该是要把处理后的score放进去继续处理,也就成为了上面的样子。
score = self.relu(self.conv6(x5)) # conv6 size不变 (1/32)
score = self.relu(self.conv7(score)) # conv7 size不变 (1/32)
score = self.relu(self.deconv1(x5)) # out_size = 2*in_size (1/16)
score = self.bn1(score + x4)
score = self.relu(self.deconv2(score)) # out_size = 2*in_size (1/8)
score = self.bn2(score + x3)
score = self.bn3(self.relu(self.deconv3(score))) # out_size = 2*in_size (1/4)
score = self.bn4(self.relu(self.deconv4(score))) # out_size = 2*in_size (1/2)
score = self.bn5(self.relu(self.deconv5(score))) # out_size = 2*in_size (1)
score = self.classifier(score) # size不变,使输出的channel等于类别数每一次池化尺寸会减半,而后面每次反卷积就意味着尺寸会变为两倍,因此处理到最后也就成为了原来的尺寸。
图片的预处理
接下来就是对于训练图片的预处理,包括图片处理和图片编码部分。
图片处理
对图片本身的处理主要是尺寸变换还有标准化和打包这些,基本是通过库函数来完成,就不多说。
图片编码
编码相对麻烦,需要用到独热编码,因为损失函数计算可能会用到。
独热编码就是开辟n个位置,在对应的那个维度为1,剩下为0。比如性别可以是男/女,男是第一个,女是第二个,那么对于一个个体他的性别可以是男,编码10,或者女,编码01;再假设国籍可以是中国/美国/日本,那么一个人的国籍编码可以是100,010,001(中国,美国,日本),也就是永远一个为1,其他为0,为1的就对应他自己所属的。这里的类别也类似,假设有两个像素点,每个像素点要么01,属于第一类,要么10,属于第二类。
独热编码如下:
def onehot(data, n):
buf = np.zeros(data.shape + (n,)) # 相当于给每一个像素开辟一个维度,除了他其他都是其他
nmsk = np.arange(data.size) * n + data.ravel() # revel表示展平多维数组,就是flatten
# 前面的data.size是从第一个元素到最后一个元素(所有),下标0--n-1,表示的是行,乘一行个数n就是在在一维数组中一行的开始位置
buf.ravel()[nmsk] = 1 # 这个就是表示把对应的是1的(根据上面nmsk找到的索引值)值给buf
return buf
解释一下这个函数是干什么的,传入的参数就是一张图片,比如是160*160的一张图,本质当然是一个数字矩阵,现在要为每个像素点编码,因为有两个类别,所以每个像素点需要两个位置,因此加上一个维度n,全部置0,这个就是没编码前的矩阵,大小160*160*2。nmsk存储的是每一个像素点所对应类别在展平的未编码矩阵中的位置。
举个栗子,现在的图片是二维矩阵([[0,1,0],[1,1,0],[0,0,1]]),那么开辟buf是3*3*2的矩阵,全是0,第一个像素点是0,也就是类别为第一个,所以这个像素点编码[1,0],第二个是1,编码[0,1],后面同理,最后只要把一开始的矩阵中的每个元素换成编码后的就可以了,最终就是[[[1,0],[0,1]......]],但是这样不好写,因此我们可以先把为1的位置记录下来,最后直接替换。展平的编码后的矩阵前四个为1001,我们来讨论怎么来的,第一个像素编码10,而这个1所在最终展平的矩阵中的位置就是0=0*2+0,第二个1所在位置是3=1*2+1,所以可以发现算法:
WZ(1的最终位置)=WZ(像素点索引)*类别数+像素点所属类别
因此就用nmsk将这些1的位置记录下来,然后最后把对应位置的0替换为1,这样就完成了对图像像素的编码。
这样编码后的图片怎么恢复为原来的图,很简单,只要找到1所在的位置是不是就可以了,那是不是就是找最大值在这个维度的位置,也就是argmax()函数,下面是一个简单演示:
imgB = np.array([1, 0, 1, 1, 0, 1, 1, 0, 0]).reshape(3, 3)
print('编码前:\n', imgB)
imgB = onehot(imgB, 2)
# print('2:', imgB)
print('恢复:\n', np.argmax(imgB, 2))效果如下

这在下面的训练代码中有所体现。
计算相关参数
这里的相关参数指的是精度acc还有iou这些,其他我还没有仔细推算过,主要讲一下精度这个吧。
代码如下:
# 在训练网络前定义函数用于计算Acc 和 mIou
# 计算混淆矩阵
def _fast_hist(label_true, label_pred, n_class):
mask = (label_true >= 0) & (label_true < n_class) # 查找有效类别,mask是个bool类型向量
# 计算匹配个数
hist = np.bincount( # bincount输出每个元素的数量,np.bincount([1,1,2]) 输 出 : [0,2,1]代表0有0个,1有2个,2有1个
n_class * label_true[mask].astype(int) + # astype代表把bool转为int
label_pred[mask], minlength=n_class ** 2).reshape(n_class, n_class) # minlength=4表示最少计算到class*2,为0也计算,不然个数都不够
'''
混淆矩阵 n_class = 2,矩阵2*2
0 1 标答
0 0*2+0 0*2+1
1 1*2+0 1*2+1
预测
一维向量的输出是 0,1,2,3,对应到矩阵中
'''
return hist
# 根据混淆矩阵计算Acc和mIou
def label_accuracy_score(label_trues, label_preds, n_class):
"""
Returns accuracy score evaluation result.
- overall accuracy
- mean accuracy
- mean IU
"""
hist = np.zeros((n_class, n_class))
for lt, lp in zip(label_trues, label_preds): # zip(a,b)就是一一对应打包起来
hist += _fast_hist(lt.flatten(), lp.flatten(), n_class) # 展平送进去计算,也就是向量计算
acc = np.diag(hist).sum() / hist.sum() # 计算主对角线的,也就是正确的数量
with np.errstate(divide='ignore', invalid='ignore'):
acc_cls = np.diag(hist) / hist.sum(axis=1)
acc_cls = np.nanmean(acc_cls)
with np.errstate(divide='ignore', invalid='ignore'):
iu = np.diag(hist) / (
hist.sum(axis=1) + hist.sum(axis=0) - np.diag(hist)
)
mean_iu = np.nanmean(iu)
freq = hist.sum(axis=1) / hist.sum()
return acc, acc_cls, mean_iu这里涉及到一个计算混淆矩阵的问题,混淆矩阵本身非常简单,也就是计算00,01,10,11匹配的个数,01代表标注是0,但是预测为1,其他同理。
传入参数就是标答矩阵,预测矩阵和类别数,从注释中可以看出,展开的四个位置0,1,2,3分别是0*2+0,0*2+1,1*2+0,1*2+1,所以这时候将预测值看做行标,标答作为列标就可以很轻松算出0-1匹配情况在四个位置的数量。一开始的musk我猜想是为了剔除无效的坐标,比如预测为3,但实际上没有这个类别也就没有计算的必要了。
至于acc的计算,一定是预测和标答一致才算正确,所以就是对于主对角线求和除以总的像素点个数。
模型训练
以上就是所有相关的轮子,最后开始组装,也就是开始模型训练。
模型训练实际上大同小异,设定优化器,损失函数,然后设定训练轮数,开始训练。
def train(epo_num=50, show_vgg_params=False):
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
if torch.cuda.is_available():
print('使用GPU')
else:
print('使用CPU')
vgg_model = VGGNet(requires_grad=True, show_params=show_vgg_params)
fcn_model = FCN8s(pretrained_net=vgg_model, n_class=2) # 把训练好的几个maxpool层的集合传给fcn
fcn_model = fcn_model.to(device) # 载入模型
# 这里只有两类,采用二分类常用的损失函数BCE
criterion = nn.BCELoss().to(device)
# 随机梯度下降优化,学习率0.001,惯性分数0.7
optimizer = optim.SGD(fcn_model.parameters(), lr=1e-3, momentum=0.7)
# 记录训练过程相关指标
all_train_iter_loss = []
all_test_iter_loss = []
test_Acc = []
test_mIou = []
# start timing
prev_time = datetime.now()
for epo in range(1, epo_num + 1):
pbar = tqdm(train_dataloader) # 要先把训练集转进进度条里面
# 训练
train_loss = 0 # 一轮的总误差,全部图片的
fcn_model.train()
for index, (bag, bag_msk) in enumerate(pbar):
bag = bag.to(device)
bag_msk = bag_msk.to(device)
optimizer.zero_grad() # 梯度清零
output = fcn_model(bag) # 输出
# print(output.shape)
output = torch.sigmoid(output) # output.shape is torch.Size([4, 2, 160, 160])
loss = criterion(output, bag_msk) # 计算和标答的误差
# print('loss=',loss)
loss.backward() # 需要计算导数,则调用backward()
# print('grad_loss=',loss)
iter_loss = loss.item() # .item()返回一个具体的值,一般用于loss和acc,这一张的误差
all_train_iter_loss.append(iter_loss) # 把误差放进误差列表,方便最后画图
train_loss += iter_loss # 加到一轮总的误差里
optimizer.step() # 根据求导得到的进行更新
output_np = output.cpu().detach().numpy().copy()
bag_msk_np = bag_msk.cpu().detach().numpy().copy()
bag_msk_np = np.argmax(bag_msk_np, axis=1)
info = 'epoch {}, {}/{},train loss is {}'.format(epo, index, len(train_dataloader), iter_loss)
pbar.set_description(info)
# 验证
test_loss = 0
fcn_model.eval()
with torch.no_grad():
for index, (bag, bag_msk) in enumerate(test_dataloader):
bag = bag.to(device)
bag_msk = bag_msk.to(device)
optimizer.zero_grad()
output = fcn_model(bag)
output = torch.sigmoid(output) # output.shape is torch.Size([4, 2, 160, 160])
loss = criterion(output, bag_msk)
iter_loss = loss.item()
all_test_iter_loss.append(iter_loss)
test_loss += iter_loss # 计算并记录误差
output_np = output.cpu().detach().numpy().copy()
output_np = np.argmax(output_np, axis=1)
bag_msk_np = bag_msk.cpu().detach().numpy().copy()
# 计算时间
cur_time = datetime.now()
# divmod(x,y)返回一个元组,第一个参数是整除的结果,第二个是取模的结果
h, remainder = divmod((cur_time - prev_time).seconds, 3600)
m, s = divmod(remainder, 60)
time_str = "Time %02d:%02d:%02d" % (h, m, s) # 时分秒
prev_time = cur_time # 更新时间
info = 'epoch: %d, epoch train loss = %f, epoch test loss = %f, %s' \
% (epo, train_loss / len(train_dataloader), test_loss / len(test_dataloader), time_str)
print(info)
acc, acc_cls, mean_iu = label_accuracy_score(bag_msk_np, output_np, 2)
test_Acc.append(acc)
test_mIou.append(mean_iu)
print('Acc = %f, mIou = %f' % (acc, mean_iu))
# 每2个epoch存储一次模型
if np.mod(epo, 2) == 0:
# 只存储模型参数
torch.save(fcn_model.state_dict(), './pths/fcn_model_{}.pth'.format(epo))
print('成功存储模型:fcn_model_{}.pth'.format(epo))一个小问题
正文在上面就结束了,但是我还是有一个疑问,除了上面FCN模型那里有点小问题,还有一个地方就是关于onehot()中nmsk的计算,原作者的代码如下:
def onehot(data, n):
buf = np.zeros(data.shape + (n,)) # 相当于给每一个像素开辟一个维度,除了他其他都是其他
nmsk = np.arange(data.size) * n + data.ravel() # revel表示展平多维数组,就是flatten
buf.ravel()[nmsk-1] = 1 # 这个就是表示把对应的是1的(根据上面nmsk找到的索引值)值给buf
return buf区别就是这里的nmsk有一个-1,并且在恢复矩阵时选择了argmin()而非argmax()函数,但是实际上我用这样的一套去编码一个3*3矩阵在还原时,矩阵已经变样。

可以看到无法恢复,但是奇怪的是我用这样的规则去看了恢复的图(下图中中间是标注,左边是用了nmsk-1和argmin()的组合,右边是nmsk和argmax()的组合)

竟然毫无违和恢复了。嗯???还有这种操作?好像也没什么问题。众所周知,为什么可以比为什么不可以更加离奇。我百思不得其解,后来想了想这也许和图片本身一些特殊的性质也有关系,大致如下。
这种图片首先是二分类,非1即0,所以这也就给了找最大1变为找最小也就是找0,使用argmin()的机会,那么按说这时候的输出应该是黑白颠倒,但是实际上并没有,为什么?因为nmsk-1。
假设编码对象是111000,那么正常编码后展平就应该是01 01 01 10 10 10,但是由于nmsk-1了,所以所有1的位置都要前移,第一个变成-1,到了最后,最后编码结果为10 10 11 01 01 00,然后这时候两个相邻之间的最小值索引发现是1,1,0,0,0,0,可以发现两点:
一是大部分正常恢复了,为什么,因为0101..前移之后变成1010...然后找最小,0代替了原来的1,所以现在的找最小等同于原来的找最大。
二是第三个1恢复出错了,为什么,这是由于移动导致两个01编码后本来是0110,然后11都移动到了1所对应的位置,然后argmin()对于相同的参数输出第一个索引下标,就成为了0,恢复出错,从上面的程序结果来看也是如此,对于每一个10的交界处,1都被恢复为了0,导致出错。
那么为什么上图恢复出来看上去没有什么问题呢?答案就是一张图片10交界太少了,大部分都是000....111....000....111...,导致这种错误发生的那几个像素点几乎不影响最终结果。
完整代码
import os
import torch
import torch.nn as nn
from torch.utils.data import DataLoader, Dataset, random_split
from torchvision import transforms
from torchvision.models.vgg import VGG
import cv2
import numpy as np
from tqdm import tqdm
# 将标记图(每个像素值代该位置像素点的类别)转换为onehot编码
def onehot(data, n):
buf = np.zeros(data.shape + (n,)) # 相当于给每一个像素开辟一个维度,除了他其他都是其他
nmsk = np.arange(data.size) * n + data.ravel() # revel表示展平多维数组,就是flatten
# 前面的data.size是从第一个元素到最后一个元素(所有),下标0--n-1,表示的是行,乘一行个数n就是在在一维数组中一行的开始位置
# 后面的是0--n-1表示的是类别,表示第几个
# 索引nmsk存储了在一维数组中应该是1的位置,也就是正确答案
buf.ravel()[nmsk-1] = 1 # 这个就是表示把对应的是1的(根据上面nmsk找到的索引值)值给buf
return buf
# 利用torchvision提供的transform,定义原始图片的预处理步骤(转换为tensor和标准化处理)
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])
# 利用torch提供的Dataset类,定义我们自己的数据集
base_img = './data/bag_data/' # 训练集地址
base_img_msk = './data/bag_data_msk/' # 标注地址
class BagDataset(Dataset):
def __init__(self, transform=None):
self.transform = transform
def __len__(self):
return len(os.listdir(base_img))
def __getitem__(self, idx):
img_name = os.listdir(base_img)[idx] # index是随机数,是图片的索引值
imgA = cv2.imread(base_img + img_name)
imgA = cv2.resize(imgA, (160, 160))
# img_name = '1.jpg'
imgB = cv2.imread(base_img_msk + img_name, 0)
imgB = cv2.resize(imgB, (160, 160))
# 下面是对标注的一些处理
imgB = imgB / 255 # 归一化
imgB = imgB.astype('uint8') # 转化成整数
imgB = onehot(imgB, 2)
imgB = imgB.transpose(2, 0, 1) # 转置 0 1 2 -> 2 0 1 相当于几个维度的位置关系变化,就是把一开始加到最后的提到最前面,效果就是把两列的每一列变成一张图
imgB = torch.FloatTensor(imgB)
if self.transform:
imgA = self.transform(imgA)
return imgA, imgB
# 实例化数据集
bag = BagDataset(transform)
train_size = int(0.9 * len(bag))
test_size = len(bag) - train_size
train_dataset, test_dataset = random_split(bag, [train_size, test_size]) # 划分数据集
# 利用DataLoader生成一个分batch获取数据的可迭代对象
train_dataloader = DataLoader(train_dataset, batch_size=4, shuffle=True, num_workers=4)
test_dataloader = DataLoader(test_dataset, batch_size=4, shuffle=True, num_workers=4)
# <-------------------------------------------------------->#
# 下面开始定义网络模型
# 先定义VGG结构
# ranges 是用于方便获取和记录每个池化层得到的特征图
# 例如vgg16,需要(0, 5)的原因是为方便记录第一个pooling层得到的输出(详见下午、稳VGG定义)
ranges = {
'vgg11': ((0, 3), (3, 6), (6, 11), (11, 16), (16, 21)),
'vgg13': ((0, 5), (5, 10), (10, 15), (15, 20), (20, 25)),
'vgg16': ((0, 5), (5, 10), (10, 17), (17, 24), (24, 31)),
'vgg19': ((0, 5), (5, 10), (10, 19), (19, 28), (28, 37))
}
# Vgg网络结构配置(数字代表经过卷积后的channel数,‘M’代表池化层)
cfg = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
# 由cfg构建vgg-Net的卷积层和池化层(block1-block5)
def make_layers(cfg, batch_norm=False):
layers = []
in_channels = 3 # RGB初始值
for v in cfg:
if v == 'M': # 池化层
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm: # 是否需要归一化
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v # 这一层输出的通道数就是下一层输入的通道数
return nn.Sequential(*layers)
# 下面开始构建VGGnet
class VGGNet(VGG):
def __init__(self, pretrained=True, model='vgg16', requires_grad=True, remove_fc=True, show_params=False):
super().__init__(make_layers(cfg[model]))
self.ranges = ranges[model] # ranges是一个字典,键是model名字,后面的是池化层的信息
# 获取VGG模型训练好的参数,并加载(第一次执行需要下载一段时间)
if pretrained:
exec("self.load_state_dict(models.%s(pretrained=True).state_dict())" % model)
# 屏蔽预训练模型的权重,只训练最后一层的全连接的权重,因为fcn模型是建立在vgg16基础上训练的,所以前面训练好的VGG网络不修改
if not requires_grad:
for param in super().parameters():
param.requires_grad = False
# 去掉vgg最后的全连接层(classifier)
if remove_fc:
del self.classifier
# 打印网络的结构
if show_params == True:
for name, param in self.named_parameters():
print(name, param.size())
def forward(self, x):
output = {}
# 利用之前定义的ranges获取每个max-pooling层输出的特征图,这个主要是FCN32的上采样要用到
for idx, (begin, end) in enumerate(self.ranges): # enumerate用于枚举,同时给出元素和下标
# self.ranges = ((0, 5), (5, 10), (10, 17), (17, 24), (24, 31)) (vgg16 examples)
for layer in range(begin, end):
x = self.features[layer](x)
# 相当于把x矩阵放进layer层,然后得到输出,0-5代表第一个max-pool需要经过的层数,所以x1实际上就是第一个max-pool层输出
output["x%d" % (idx + 1)] = x
# x数字越大越深
# output 为一个字典键x1d对应第一个max-pooling输出的特征图,x2...x5类推
return output
# 下面由VGG构建FCN8s
class FCN8s(nn.Module):
def __init__(self, pretrained_net, n_class):
super().__init__()
# 定义可能会用到的东西
self.n_class = n_class
self.pretrained_net = pretrained_net
self.conv6 = nn.Conv2d(512, 512, kernel_size=1, stride=1, padding=0, dilation=1)
self.conv7 = nn.Conv2d(512, 512, kernel_size=1, stride=1, padding=0, dilation=1) # 卷积核大小是1,本质上是全连接层
# 这里写两个一样的可能是为了写出前后关系的感觉?
self.relu = nn.ReLU(inplace=True)
self.deconv1 = nn.ConvTranspose2d(512, 512, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn1 = nn.BatchNorm2d(512)
self.deconv2 = nn.ConvTranspose2d(512, 256, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn2 = nn.BatchNorm2d(256)
self.deconv3 = nn.ConvTranspose2d(256, 128, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.deconv4 = nn.ConvTranspose2d(128, 64, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn4 = nn.BatchNorm2d(64)
self.deconv5 = nn.ConvTranspose2d(64, 32, kernel_size=3, stride=2, padding=1, dilation=1, output_padding=1)
self.bn5 = nn.BatchNorm2d(32)
self.classifier = nn.Conv2d(32, n_class, kernel_size=1)
def forward(self, x):
output = self.pretrained_net(x)
# 这个已经在前面的forward中初始化了,里面已经存储了相关特征图
x5 = output['x5'] # max-pooling5的feature map (1/32) 5*5,160/32
x4 = output['x4'] # max-pooling4的feature map (1/16)
x3 = output['x3'] # max-pooling3的feature map (1/8)
# 所以总结一下FCN里面的几个合成的步骤也就是反卷积->激活->标准化->加上前面的pool层继续
# 这两句没用,或者说用错了
score = self.relu(self.conv6(x5)) # conv6 size不变 (1/32)
# 1/32可能没有融合进去?
# 这里我尝试把右边括号里的x5改成了score
score = self.relu(self.deconv1(score)) # out_size = 2*in_size (1/16)
score = self.bn1(score + x4) # bn是标准化,表示加x4第二池化层的结果一同进行计算
score = self.relu(self.deconv2(score)) # out_size = 2*in_size (1/8)
score = self.bn2(score + x3)
# 到这里为止就是全部的FCN步骤,接下来是反卷积到原尺寸
# 此时是1/8,然后继续反卷积,每次扩大两倍边长直到最后和原图一样
score = self.bn3(self.relu(self.deconv3(score))) # out_size = 2*in_size (1/4),反卷积后标准化
score = self.bn4(self.relu(self.deconv4(score))) # out_size = 2*in_size (1/2)
score = self.bn5(self.relu(self.deconv5(score))) # out_size = 2*in_size (1)
score = self.classifier(score) # size不变,使输出的channel等于类别数,相当于对每个点分类
# print(score.shape)
# time.sleep(1000)
return score
# <---------------------------------------------->
# 下面开始训练网络
# 在训练网络前定义函数用于计算Acc 和 mIou
# 计算混淆矩阵
def _fast_hist(label_true, label_pred, n_class):
mask = (label_true >= 0) & (label_true < n_class) # 查找有效类别,mask是个bool类型向量
# 计算匹配个数
hist = np.bincount( # bincount输出每个元素的数量,np.bincount([1,1,2]) 输 出 : [0,2,1]代表0有0个,1有2个,2有1个
n_class * label_true[mask].astype(int) + # astype代表把bool转为int
label_pred[mask], minlength=n_class ** 2).reshape(n_class, n_class) # minlength=4表示最少计算到class*2,为0也计算,不然个数都不够
'''
混淆矩阵 n_class = 2,矩阵2*2
0 1 标答
0 0*2+0 0*2+1
1 1*2+0 1*2+1
预测
一维向量的输出是 0,1,2,3,对应到矩阵中
'''
return hist
# 根据混淆矩阵计算Acc和mIou
def label_accuracy_score(label_trues, label_preds, n_class):
"""
Returns accuracy score evaluation result.
- overall accuracy
- mean accuracy
- mean IU
"""
hist = np.zeros((n_class, n_class))
for lt, lp in zip(label_trues, label_preds): # zip(a,b)就是一一对应打包起来
hist += _fast_hist(lt.flatten(), lp.flatten(), n_class) # 展平送进去计算,也就是向量计算
acc = np.diag(hist).sum() / hist.sum() # 计算主对角线的,也就是正确的数量
with np.errstate(divide='ignore', invalid='ignore'):
acc_cls = np.diag(hist) / hist.sum(axis=1)
acc_cls = np.nanmean(acc_cls)
with np.errstate(divide='ignore', invalid='ignore'):
iu = np.diag(hist) / (
hist.sum(axis=1) + hist.sum(axis=0) - np.diag(hist)
)
mean_iu = np.nanmean(iu)
freq = hist.sum(axis=1) / hist.sum()
return acc, acc_cls, mean_iu
from datetime import datetime
import torch.optim as optim
import matplotlib.pyplot as plt
def train(epo_num=50, show_vgg_params=False):
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
if torch.cuda.is_available():
print('使用GPU')
else:
print('使用CPU')
vgg_model = VGGNet(requires_grad=True, show_params=show_vgg_params)
fcn_model = FCN8s(pretrained_net=vgg_model, n_class=2) # 把训练好的几个maxpool层的集合传给fcn
fcn_model = fcn_model.to(device) # 载入模型
# 这里只有两类,采用二分类常用的损失函数BCE
criterion = nn.BCELoss().to(device)
# 随机梯度下降优化,学习率0.001,惯性分数0.7
optimizer = optim.SGD(fcn_model.parameters(), lr=1e-3, momentum=0.7)
# 记录训练过程相关指标
all_train_iter_loss = []
all_test_iter_loss = []
test_Acc = []
test_mIou = []
# start timing
prev_time = datetime.now()
for epo in range(1, epo_num + 1):
pbar = tqdm(train_dataloader) # 要先把训练集转进进度条里面
# 训练
train_loss = 0 # 一轮的总误差,全部图片的
fcn_model.train()
for index, (bag, bag_msk) in enumerate(pbar):
bag = bag.to(device)
bag_msk = bag_msk.to(device)
optimizer.zero_grad() # 梯度清零
output = fcn_model(bag) # 输出
# print(output.shape)
# time.sleep(1000)
output = torch.sigmoid(output) # output.shape is torch.Size([4, 2, 160, 160])
loss = criterion(output, bag_msk) # 计算和标答的误差
# print('loss=',loss)
loss.backward() # 需要计算导数,则调用backward()
# print('grad_loss=',loss)
iter_loss = loss.item() # .item()返回一个具体的值,一般用于loss和acc,这一张的误差
all_train_iter_loss.append(iter_loss) # 把误差放进误差列表,方便最后画图
train_loss += iter_loss # 加到一轮总的误差里
optimizer.step() # 根据求导得到的进行更新
output_np = output.cpu().detach().numpy().copy()
output_np = np.argmax(output_np, axis=1) # 找出所有通道里面的最小值
# 相当于就是把两个维度的最小值的找到作为输出,也就是找的是0在两个索引中的位置,本质也是在找1的位置
bag_msk_np = bag_msk.cpu().detach().numpy().copy()
bag_msk_np = np.argmax(bag_msk_np, axis=1)
info = 'epoch {}, {}/{},train loss is {}'.format(epo, index, len(train_dataloader), iter_loss)
pbar.set_description(info)
# 验证
test_loss = 0
fcn_model.eval()
with torch.no_grad():
for index, (bag, bag_msk) in enumerate(test_dataloader):
bag = bag.to(device)
bag_msk = bag_msk.to(device)
optimizer.zero_grad()
output = fcn_model(bag)
output = torch.sigmoid(output) # output.shape is torch.Size([4, 2, 160, 160])
loss = criterion(output, bag_msk)
iter_loss = loss.item()
all_test_iter_loss.append(iter_loss)
test_loss += iter_loss # 计算并记录误差
output_np = output.cpu().detach().numpy().copy()
output_np = np.argmax(output_np, axis=1)
bag_msk_np = bag_msk.cpu().detach().numpy().copy()
# 解释一下为什么这里的0和1一样多,因为按照onehot,这里一开始实际上每个像素点对应onehot变化是[0,1]或者[1,0],所以10的总和是一样,因为每个像素点对应了一组[1,0]
# 之后经过一个维度变换,160,160,2-->2,160,160也就是被分成了两张图片,找两个维度0所在的索引
bag_msk_np = np.argmax(bag_msk_np, axis=1)
# 计算时间
cur_time = datetime.now()
# divmod(x,y)返回一个元组,第一个参数是整除的结果,第二个是取模的结果
h, remainder = divmod((cur_time - prev_time).seconds, 3600)
m, s = divmod(remainder, 60)
time_str = "Time %02d:%02d:%02d" % (h, m, s) # 时分秒
prev_time = cur_time # 更新时间
# print()
info = 'epoch: %d, epoch train loss = %f, epoch test loss = %f, %s' \
% (epo, train_loss / len(train_dataloader), test_loss / len(test_dataloader), time_str)
print(info)
acc, acc_cls, mean_iu = label_accuracy_score(bag_msk_np, output_np, 2)
test_Acc.append(acc)
test_mIou.append(mean_iu)
print('Acc = %f, mIou = %f' % (acc, mean_iu))
# 每2个epoch存储一次模型
if np.mod(epo, 2) == 0:
# 只存储模型参数
torch.save(fcn_model.state_dict(), './pths/fcn_model_{}.pth'.format(epo))
print('成功存储模型:fcn_model_{}.pth'.format(epo))
# 绘制训练过程数据
plt.figure()
plt.subplot(221)
plt.title('train_loss')
plt.plot(all_train_iter_loss)
plt.xlabel('batch')
plt.subplot(222)
plt.title('test_loss')
plt.plot(all_test_iter_loss)
plt.xlabel('batch')
plt.subplot(223)
plt.title('test_Acc')
plt.plot(test_Acc)
plt.xlabel('epoch')
plt.subplot(224)
plt.title('test_mIou')
plt.plot(test_mIou)
plt.xlabel('epoch')
plt.show()
if __name__ == "__main__":
# 主程序
train(epo_num=20, show_vgg_params=False) # 参数是设置是否打印网络结构
参考
代码来源
FCN详解与pytorch简单实现(附详细代码解读)_zinc_abc的博客-CSDN博客
数据集和代码
mirrors / bat67 / pytorch-FCN-easiest-demo · GitCode