1月13号学习笔记 逻辑回归
1:逻辑回归
机器学习有回归与分类
我们可以按照任务的种类,将任务分为回归任务和分类任务.按照较官方些的说法,
输入变量与输出变量均为连续变量的预测问题是回归问题。输出变量为有限个离散变量的预测问题成为分类问题。
不同的人对应不同的身高与体重,我们显然可以看作一个连续的模型,但如果医学上的检测一个人是否患有肿瘤,这个显然只有两种可能,有或者没有,这是一个离散的模型。
简单的来说它是线性回归的一种,事实上它是一-个被logistic方程归一化后的线性回归。在许多实际问题中,比如流行病学常研究的二分类因变量(患病与未患病、阳性与阴性等)与一(X1X2*.*. Xn))自变量的关系这类问题时,我们需要回归产生一个类似概率值(0-1)之间的数值来进行预测。这种情况下这个数值必须是0^ 1之间,而线性回归就显得无能为力了,因此人们引入了Logistic方程来做归一化。使得因变量的取值框定在了0^ 1之间。这种变换方法我们就称之为逻辑回归。
逻辑回归又称Logistic回归分析,是一种广义的线性回归分析模型,常用于数据挖掘、疾病自动诊断、经济预测等领域。逻辑回归从本质来说属于二分类问题。(通过控制一定的阈值把问题分为两类结果)例如一个患肿瘤的概率为0.01我们通常则可认为它没患肿瘤,但如果一个人患肿瘤的概率为0.99我们则通常认为它患肿瘤。
逻辑回归的原理是用逻辑函数把线性回归的结果(-∞,∞)映射到(0,1)
这是一个线性函数,我们需要处理把它的结果控制在(0,1)
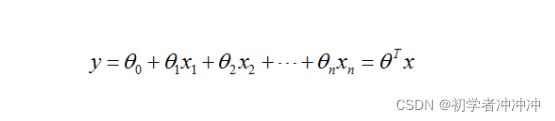
我们需要借助sigmoid函数
sigmoid函数 (又称逻辑回归函数)
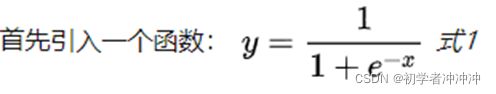
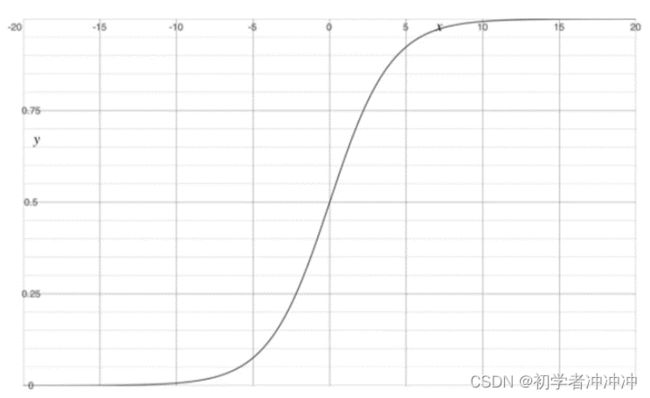
该函数有一个很好的特性就是在实轴域上y的取值在(0,1),且有很好的对称性,对极大值和极小值不敏感(因为在取向无论是正无穷还是负无穷的时候函数的y几乎很稳定)
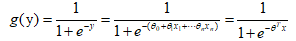
把线性回归函数的结果y,放到sigmod函数中去,就构造了逻辑回归函数。由y的值域和sigmod函数的值域知,在逻辑回归函数中用sigmod函数把线性回归的结果(-∞,∞)映射到(0,1),得到的这个结果类似一个概率值。
二分类问题,要判断一个来借款的人是否会逾期。如果会逾期给这个人的标记为1,不会逾期给这个人标记为0。由于线性回归模型对于分类问题往往效果不好,所以我们想构建一个广义线性模型回归,来对该问题进行求解,而广义线性模型的因变量要服从指数分布,现在要挑选一个服从指数分布的分布函数。这时我们很自然就会想到我们常见的0-1分布,伯努利分布。它的分布形式如下:
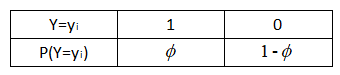
它的概率分布可以数学定义为:
![]()
逻辑回归的因变量g(y)就是伯努利分布中样本为1的概率(也可以理解为事件为1出现的概率),1-g(y)就是样本为0的概率,(也可以理解为事件为0出现的概率),我们把这两个概率整合到一起就构成了事件取1或者取0的概率。
举一个简单例子,我们把银行违约的客户定义为事件1,那么客户不违约的客户定义事件0,如果我们手中有大量的客户信息,我们就可以通过模型,求的一个模型参数,来预测一个用户违约与不违约的概率
这篇文章对概率的定义有更深入的讲解((3条消息) 逻辑回归三部曲——逻辑回归和sigmod函数的由来_阿黎逸阳的博客-CSDN博客)

通过Logistic函数归一化到(0,1)间,y的取值有特殊的含义,它表示结果取准确的概率,如果分类为1,h(x)==1表示预测100%准确,分类为0,h(x)==0表示预测100%准确。
我们有了逻辑回归函数我们需要想办法的到这个函数取最大值时的参数。
我们有两种方法去求得
首先我们要讲函数转化为对数的形式(这样可以将连乘运算,转化为连加运算,有利于求导)
1 梯度下降法
2 最大似然估计法
我们先看看梯度下降法:
我们首先要构造损失函数
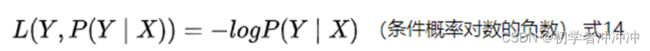
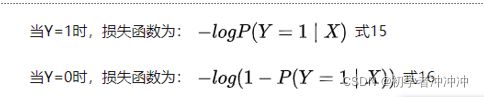
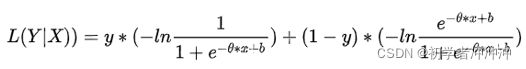
这是一个样本点,N个样本点求和就行了。
我们想要知道逻辑函数的最大值的点参数,我们这里把上述的逻辑函数先去对数,在加上负号(我们要取最大值那么加上负号不就是取最小值了吗)
看看手工的推导过程

2 再来看看最大似然估计法 (这里要用到概率论的知识)
找到使样本点成立的最大值点参数

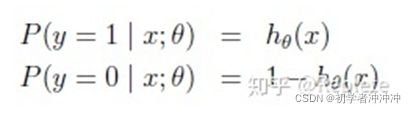
•对上面的表达式合并一下就是:



这里需要最大值,就采用梯度上升的方法(与梯度下降求最小值的参数相反)。
通过训练方法得到这些模型参数我们就可以得到预测为1或预测为0的概率,通过合适的界限(不同问题模型有不同的界限)就可以把问题分为两类
代码部分
下面看看代码部分
一般python可以调用(sklearn库)
我们先来看看不调用库的主要函数(这里借鉴这位博主的代码)
博客地址(•原文链接:https://blog.csdn.net/ArrogantT/article/details/108933531)ji
##估价函数
def sigmoid(z):
return(1 / (1.0 + math.exp(-z)))
def hypothesis(x, theta, feature_number):
h = 0.0
for i in range(feature_number+1):
h += x[i] * theta[i]
return(sigmoid(h))
##计算偏导数
def compute_gradient(x, y, theta, feature_number, feature_pos, sample_number):
sum = 0.0
for i in range(sample_number):
h = hypothesis(x[i], theta, feature_number)
sum += (h - y[i]) * x[i][feature_pos]
return(sum / sample_number)
##代价
def compute_cost(x, y, theta, feature_number, sample_number):
sum = 0.0
for i in range(sample_number):
h = hypothesis(x[i], theta, feature_number)
sum += -y[i] * math.log(h) - (1 - y[i]) * math.log(1 - h)
return(sum / sample_number)
##梯度下降
def gradient_descent(x, y, theta, feature_number, sample_number, alpha, count):
for i in range(count):
tmp = []
for j in range(MAX_FEATURE_DIMENSION):
tmp.append(0)
for j in range(feature_number + 1):
tmp[j] = theta[j] - alpha * compute_gradient(x, y ,theta, feature_number, j, sample_number)
for j in range(feature_number + 1):
theta[j] = tmp[j]
print(compute_cost(x, y, theta, feature_number, sample_number))接下来看看调用库的实例(鸢尾花实例)(随着继续深入学习自己会不断补充,这里借鉴这位博主的代码,这里有些知识自己还没完全学到或学会)
这位博主地址((3条消息) 实验一:鸢尾花数据集分类_巧喵的博客-CSDN博客_鸢尾花数据集分类实验报告)
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
iris_data = load_iris()
# 该函数返回一个Bunch对象,它直接继承自Dict类,与字典类似,由键值对组成。
# 可以使用bunch.keys(),bunch.values(),bunch.items()等方法。
print(type(iris_data))
# data里面是花萼长度、花萼宽度、花瓣长度、花瓣宽度的测量数据,格式为 NumPy数组
print(iris_data['data']) # 花的样本数据
print("花的样本数量:{}".format(iris_data['data'].shape))
print("花的前5个样本数据:{}".format(iris_data['data'][:5]))
# 0 代表 setosa, 1 代表 versicolor,2 代表 virginica
print(iris_data['target']) # 类别
print(iris_data['target_names']) # 花的品种
# 构造训练数据和测试数据
X_train,X_test,y_train,y_test = train_test_split(\
iris_data['data'],iris_data['target'],random_state=0)
print("训练样本数据的大小:{}".format(X_train.shape))
print("训练样本标签的大小:{}".format(y_train.shape))
print("测试样本数据的大小:{}".format(X_test.shape))
print("测试样本标签的大小:{}".format(y_test.shape))
# 构造KNN模型
knn = KNeighborsClassifier(n_neighbors=1)
# knn = KNeighborsClassifier(n_neighbors=3)
# 训练模型
knn.fit(X_train,y_train)
y_pred = knn.predict(X_test)
# 评估模型
print("模型精度:{:.2f}".format(np.mean(y_pred==y_test)))
print("模型精度:{:.2f}".format(knn.score(X_test,y_test)))
# 做出预测
X_new = np.array([[1.1,5.9,1.4,2.2]])
prediction = knn.predict(X_new)
print("预测的目标类别是:{}".format(prediction))
print("预测的目标类别花名是:{}".format(iris_data['target_names'][prediction]))