Zero shot Learning 论文学习笔记(未完待续)
Zero shot Learning 论文学习笔记
- 前言
- zero-shot learning
-
- Learning To Detect Unseen Object Classes by Between-Class Attribute Transfer
- Label-Embedding for Attribute-Based Classification
- An embarrassingly simple approach to zero-shot learning
- Transductive Multi-View Zero-Shot Learning
- Zero-shot recognition using dual visualsemantic mapping paths
- Predicting visual exemplars of unseen classes for zero-shot learning
- Semantic AutoEncoder for Zero-Shot Learning
- Zero-Shot Learning - A Comprehensive Evaluation of the Good, the Bad and the Ugly
- Zero-Shot Learning via Class-Conditioned Deep Generative Models
- Preserving Semantic Relations for Zero-Shot Learning
- Recent Advances in Zero-shot Recognition
前言
我跨过山河大海,也穿过人山人海…然而前面还是高山大海,人山人海。初入机器学习的大门,爬上DEEPLEARNING的高山,发现前面还是高山,更多,更高,更难爬…ZST就是一座待爬的高山,很显然,“不学习就会ZST”,“或者一学就会OST”的愿景是美好的,正如小时候看的武侠小说和电影里讲的回梦心经等等神奇武功,但现实却告诉你,要想达成这样的本领,你要学的就更多了,学多了就可以触类旁通,事半功倍,机器学习也是这个道理。知乎专栏里的前辈分享了一篇博文零次学习(Zero-Shot Learning)入门,给我们准备了爬山的攻略,我就跟着前人的脚步,试读一下这十篇ZST的论文,跟着前辈啃paper,顺便做个读书笔记,看看能不能对这个问题收获一知半解,找到解决我困境的钥匙,再次突破自我。
zero-shot learning
ZSL在人类世界中是存在的,比如今早在地铁上看到一位姑娘,虽然她带着口罩,以前从未见过,我也断定这是个美女,为什么呢?因为在我的脑海里,美女都有白皙的皮肤,苗条的身段,还有一双清澈透明,会说话的眼睛…其实讲到这里,zero-shot的思想也就有了眉目,正如经典的斑马问题,虽然大多数人没有见过斑马,但是拥有马的外形和黑白相间的线条两个显著的特征,人类就可以推断出这是斑马,机器只要在学习特征和未训练标签再做一次决策树之类的分类,就能得出这样的推论。故事还没有讲完,其实你刚才看到的美女是不是真的美女还要看她摘到口罩的样子,也许口罩下面的朝天鼻,大板牙或者其他缺陷顿时让你的大跌眼镜,也就是说,zst这种由此及彼的推断肯定会有误差。
Learning To Detect Unseen Object Classes by Between-Class Attribute Transfer
这是2009年(人工智能boost次世代前夕)的文章,学习网络用的还是SVM,所以文章也没有大篇幅的吹嘘神经网络的神奇,而是很朴素的提出了自己的基于属性学习的分类观点:Attribute-Based Classification。文中提到了人类能至少识别出30000个相关目标的类别,然后用斑马的例子引出了他的观点,其主要的工作和贡献就在下图里讲述了,即DAP-直接特征学习和IAP-间接特征学习。DAP是比较直观的,各种特征被平等对待。而IAP对特征做了一层中间层,可以理解为对特征做了加权处理,很像DP中的预训练,冻结层之后做转移学习的场景,这显然像一个全连接层。
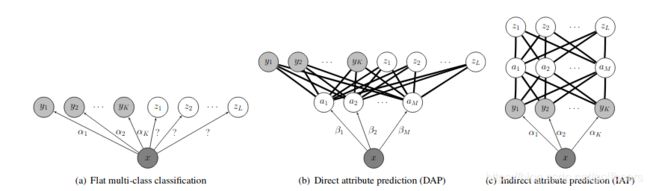 英文中关于attribute和feature在文中分的比较清,但6级英语水平的我很显然对此有些困惑。翻遍了baidu和谷歌也是见仁见智,嗨。最后找一篇stanford大学网站机器学习术语表关于两者的阐述:
英文中关于attribute和feature在文中分的比较清,但6级英语水平的我很显然对此有些困惑。翻遍了baidu和谷歌也是见仁见智,嗨。最后找一篇stanford大学网站机器学习术语表关于两者的阐述:
An attribute has a domain defined by the attribute type, which denotes the values that can be taken by an attribute.
A feature is the specification of an attribute and its value.
For example, color is an attribute. ``Color is blue'' is a feature of an example.
差强人意的理解一下,但feature, attribute两个概念将贯穿整个系列论文的学习中,慢慢领悟吧。
Label-Embedding for Attribute-Based Classification
这篇论文诞生于2013年,算是比较早期的文章,作者对属性Attributes在机器学习领域有个很具体的定义,属性Attributes是机器学习的中间表示,这个表示允许参数(我理解为feature特征)在不同的类别之间分享。基于此,论文将基于属性的图像分类当做了一种标签嵌入(向量)问题,每一个类别被嵌入到一个属性向量空间。我觉得这个Abstract写的非常好,原文如下:
Attributes are an intermediate representation, which en-ables parameter sharing between classes, a must when training
data is scarce. We propose to view attribute-basedimage classification as a label-embedding problem: each class is embedded
in the space of attribute vectors. Weintroduce a function which measures the compatibility be-tween an image and a label
embedding. The parameters ofthis function are learned on a training set of labeled sam-ples to ensure that, given an image,
thecorrect classes rankhigher than the incorrect ones. Results on the Animals WithAttributes and Caltech-UCSD-Birds datasets
show that theproposed framework outperforms the standard Direct At-tribute Prediction baseline in a zero-shot learning
scenario.The label embedding framework offers other advantagessuch as the ability to leverage alternative sources
of infor-mation in addition to attributes (e.g. class hierarchies) orto transition smoothly from zero-shot learning to learningwith large
quantities of data.
本文提出了Label embedding,就是利用Attributes作为参考信息(side information),将标签embedding到欧拉空间,然后定义函数F,做一个训练集和label embedding的分类映射。
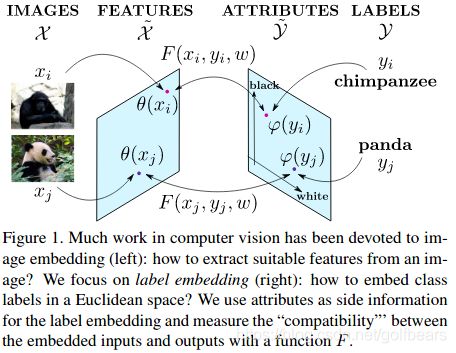 Attributes和classes之间的相关性应该是ZST永恒的主题,所以此文也再次强调了一下,另外也提到了直推式学习(transductive learning)以及当时一些方法的限制和问题,然后推出了自己的嵌入分类系统(a taxonomy of embeddings),也就是上图所示的 φ \varphi φ,输出系统的嵌入。作者提出了三种嵌入方式:
Attributes和classes之间的相关性应该是ZST永恒的主题,所以此文也再次强调了一下,另外也提到了直推式学习(transductive learning)以及当时一些方法的限制和问题,然后推出了自己的嵌入分类系统(a taxonomy of embeddings),也就是上图所示的 φ \varphi φ,输出系统的嵌入。作者提出了三种嵌入方式:
Data-independent embeddings
learned embeddings
Embeddings derived from side information
上面三种方法不展开分析了,作者是讲重点放在第三种的side information上。初步读下来这是一篇基于之前DAP的传统机器学习方法,联系当前的主流end2end学习方法,没看到有太多可以借鉴的地方。
An embarrassingly simple approach to zero-shot learning
这篇文章成文与2015年,文章的作者认为Attributes是中间语义层(intermediate semantic layer),而ZSL就是一种设计用来学习中间语义层的方法。文中还用signature来特指一个类别的属性描述,我认为这个signature是一些列feature的组合。很清晰的提出可以分训练阶段和预测阶段提高zero shot能力。这篇论文的Related Work还是对zero shot做了很多的篇幅的介绍,还强化了Attributes learnings的定义。这篇论文其实是对上一篇文章(不在之前推荐的10篇)改良,很大篇幅介绍了一下上篇文章做了两层映射,而本文主要是在此基础上,对于正则化方法(regularizer)的选择,或者说采用了不同的loss函数和regularizer,结果就是令学习能力得到了很大的提高。
文中的基础阐述部分总结了ZSL的方法是建立在转移学习和域自适应基础上的,与转移学习和直推式学习类似,ZSL也是提取源数据的通用属性,利用属性的特征来推断新的目标,差别则是ZSL没有目标的训练数据,而转移学习通常有完整的标注数据集合做训练。而域自适应的目标是从一个域学习一个函数,能够在不同的域中实现功能(分类)。具体loss函数和正则化方法暂不做深入研究。
Transductive Multi-View Zero-Shot Learning
这个文章讲到了域漂移(shift、bias)的问题(projection domain shift),提出了用转移直推(transductive)多视角的ZSL去避免。还提到原型稀疏性(prototype sparsity),以及对付它的多层次多视角超图标签扩展方法(eterogeneousmulti-view hypergraph label propagation method),听起来就高大上。
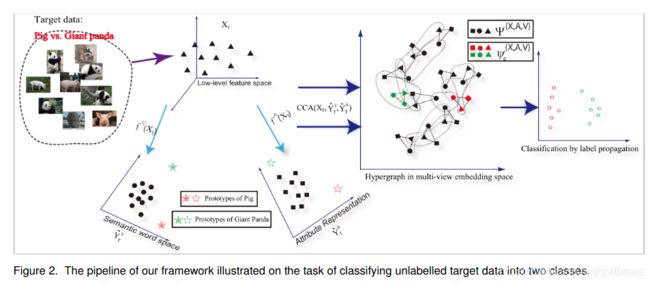
Zero-shot recognition using dual visualsemantic mapping paths
Predicting visual exemplars of unseen classes for zero-shot learning
Semantic AutoEncoder for Zero-Shot Learning
这个自动编解码器(SAE)结构是为了解决空间投射域漂移的问题,编码投射可视化的特征向量进入语音空间,这点与其他的zsl模型类似,而增加的解码器是从语义空间重建出原始的可视化特征空间,这有点像经典的“充分-必要条件”问题,通过这种对称映射,对目标域(语义空间)做出了一个强烈的限制,而实验也给出了这个方法是有效的结论。这种方法的范式基础是新增加的解码器限定条件是的目标(语义)空间能够不损失原来可视化特征空间的信息(重建可视化空间)
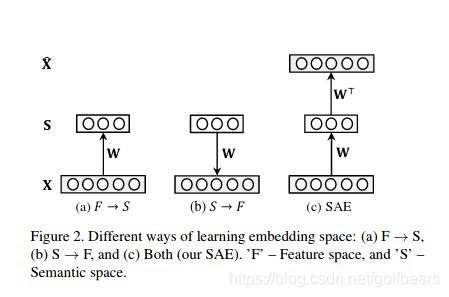 如图S空间为投射空间,W则是从特征空间到投射空间的线性变换矩阵,即 W X = S WX=S WX=S这样待优化的目标函数为:
如图S空间为投射空间,W则是从特征空间到投射空间的线性变换矩阵,即 W X = S WX=S WX=S这样待优化的目标函数为:
m i n W , W ∗ ∣ ∣ X − W ∗ W X ∣ ∣ F 2 min_{W,W^*}||X-W^*WX||^2_F minW,W∗∣∣X−W∗WX∣∣F2
作者用tied weight技巧,令 W ∗ = W T W^*=W^T W∗=WT,从而所谓的编解码器避免了训练两个网络,但tied weight技巧需要时间来理解,姑且用之。目标函数
m i n W , W ∗ ∣ ∣ X − W T W X ∣ ∣ F 2 min_{W,W^*}||X-W^TWX||^2_F minW,W∗∣∣X−WTWX∣∣F2
这样就是获得W令目标函数最小的优化问题了,具体又加了以及编码损失优化,最后的出如下公式
m i n W , W ∗ ∣ ∣ X − W T S ∣ ∣ F 2 + λ ∣ ∣ W X − S ∣ ∣ F 2 min_{W,W^*}||X-W^TS||^2_F+\lambda||WX-S||^2_F minW,W∗∣∣X−WTS∣∣F2+λ∣∣WX−S∣∣F2
西尔维斯特方程(Sylvester equation)求解等问题暂略去。该文章为域漂移问题解决提供了好的思路和实践。
Zero-Shot Learning - A Comprehensive Evaluation of the Good, the Bad and the Ugly
Zero-Shot Learning via Class-Conditioned Deep Generative Models
Preserving Semantic Relations for Zero-Shot Learning
这篇08年发表的文章已经采用了流行的encoder-decoder结构了。此文Introduction介绍了几种主流的zsl方法:
- bilinear compatibility frameworks:双线性兼容框架,比如(图像)特征和分类嵌入向量评分法,用一个固定的margin来评定分类是否正确,用度量学习离得contrastive loss类比一下。这个方法显然有点不那么灵光。
- 嵌入空前岭回归法,即嵌入图像特征or属性向量进入预定义的嵌入空间,然后构造岭回归或者均方差损失函数。这个方法对于嵌入空间的选择要求很高。通俗的将如果语法空间(semantic space)用作嵌入空间,因为其被属性所贯穿(spanned),所以这些语法结构被保留,引起了枢纽点问题;可以利用映射分类嵌入到图像特征(视觉空间)所贯穿的空间方法来缓解【特征、属性再一次傻傻分不清了】,但特征空间有没有了语法属性,逃不出类别的圈子(只是类别中的一个)。
- 流形学习(manifold learning)以及转移学习方法。
作者觉得区分类别的能力和继承语法空间属性是鱼和熊掌,当前的办法只能选择其一,而利用此文的办法是利用an encoder-decoder multilayer perceptron framework保证了二者得兼,好腻害啊。那么是如何实现的呢?语法空间的架构与嵌入空间的纽带是通过identical、semntically similar和seman-tically dissimilar实现的,(到这里我越来越觉得像triplets了)看看下图,大致感受一下,因为还有一些正则方法,所以想看懂图,还得结合文章一起看。
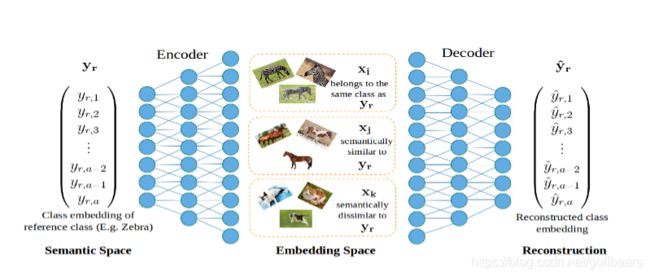 首先将visual space定义为embedding空间(就是将每个图像变换为一组带标签的向量),编码器生成semantic space向量(嵌入),如图所示,定义斑马的语法空间向量是 y r y_r yr,斑马 x i x_i xi,其他马 x j x_j xj和其他动物 x k x_k xk编码到语法空间为 y i y_i yi, y j y_j yj和 y k y_k yk,这样 y r y_r yr, y i y_i yi, y j y_j yj和 y k y_k yk构成了四元组,模仿quadruplets方法设计loss函数,就完成了基本的语义空间映射。具体实现的时候增加了decoder,将 y r y_r yr重建后作为一种正则化方法(还要品品)。在选择采样方法的时候还有很多mining策略,不一一细说了。
首先将visual space定义为embedding空间(就是将每个图像变换为一组带标签的向量),编码器生成semantic space向量(嵌入),如图所示,定义斑马的语法空间向量是 y r y_r yr,斑马 x i x_i xi,其他马 x j x_j xj和其他动物 x k x_k xk编码到语法空间为 y i y_i yi, y j y_j yj和 y k y_k yk,这样 y r y_r yr, y i y_i yi, y j y_j yj和 y k y_k yk构成了四元组,模仿quadruplets方法设计loss函数,就完成了基本的语义空间映射。具体实现的时候增加了decoder,将 y r y_r yr重建后作为一种正则化方法(还要品品)。在选择采样方法的时候还有很多mining策略,不一一细说了。