【Informer】超长序列时间序列预测的高效transformer
超长序列时间序列预测的高效Transformer

摘要:
许多实际应用需要长序列时间序列的预测,如电力消耗规划。长序列时间序列预测(LSTF)要求模型具有较高的预测能力,即能够有效地捕捉输出和输入之间精确的远程依赖耦合。最近的研究显示了Transformer在提高预测能力方面的潜力。然而,Transformer存在一些严重的问题,使其无法直接应用于LSTF,包括二次元时间复杂度、高内存使用量和编码器-解码器体系结构的固有限制。为了解决这些问题,我们设计了一个高效的基于transformer的LSTF模型,命名为Informer,该模型具有三个显著特征:(i) ProbSparse自注意机制,在时间复杂度和内存使用方面达到O(L log L),并在序列依赖对齐方面具有相当的性能。(ii)自我注意蒸馏通过将级联层输入减半来突出支配性注意,并有效地处理极长的输入序列。(iii)生成式译码器虽然概念简单,但对长时间序列序列进行一次正向预测,而不是一步一步的预测,大大提高了长序列预测的推理速度。在四个大规模数据集上的大量实验表明,Informer方法明显优于现有方法,为LSTF问题提供了一种新的解决方案。
引言:
时间序列预测是许多领域的关键组成部分,如传感器网络监测、能源和智能电网管理、经济和金融以及疾病传播分析。在这些场景中,我们可以利用大量关于过去行为的时间序列数据来进行长期预测,即长序列时间序列预测(LSTF)。然而,现有的方法大多是在短期问题设置下设计的,比如预测48点或更少。随着序列长度的不断增加,模型的预测能力受到了很大的压力,这一趋势正影响着LSTF的研究。作为一个经验例子,图(1)显示了在真实数据集上的预测结果,其中LSTM网络预测了一个电力变电站从短期(12点,0.5天)到长期(480点,20天)的小时温度。当预测长度大于48点(图(1b)中的实星)时,整体性能差距很大,此时MSE上升到性能不理想的程度,推理速度急剧下降,LSTM模型开始失效。
LSTF的主要挑战是提高预测能力,以满足日益增长的长序列需求,这需要(a)超长的远程对齐能力和(b)对长序列输入和输出的高效操作。最近,Transformer模型在捕获远程依赖关系方面表现出优于RNN模型的性能。自注意机制可以将网络信号传播路径的最大长度减少到理论最短O(1),避免了循环结构,因此Transformer在LSTF问题上表现出了巨大的潜力。然而,由于自注意机制的l -二次计算和l -长度输入/输出的内存消耗,它违反了要求(b)。一些大型Transformer模型投入了大量资源和在NLP任务上产生了令人印象深刻的结果,但这些模型需要在数十个gpu上进行训练,且部署成本昂贵,无法用于实际的LSTF问题。自注意机制和Transformer架构的效率成为将其应用于LSTF问题的瓶颈。因此,在本文中,我们试图回答这个问题:我们能否改进Transformer模型,使其计算、内存和体系结构更高效,同时保持更高的预测能力?
Vanilla Transformer在解决LSTF问题时有三个显著的局限性:
- 自我注意的二次计算。自注意机制的原子操作,即规范点积,使每层的时间复杂度和内存使用量为O(L2)
- 为长输入堆叠层时的内存瓶颈。J个编码器/解码器层的堆栈使得总内存使用量为O(J·L2),这限制了模型在接收长序列输入时的可扩展性。
- 预测长输出时的速度骤降。vanilla Transformer的动态解码使得逐步推理与基于rnn的模型一样慢。
之前有一些关于提高自我注意效率的研究。The Sparse Transformer、LogSparse Transformer 和Longformer 都使用启发式方法来解决限制1,并将自注意机制的复杂性降低到O(L log L),其效率增益是有限的。改革器也实现了O(LlogL)和局部敏感的哈希自注意,但它只适用于极长的序列。最近,Linformer 提出了一个线性复杂度O(L),但对于现实世界的长序列输入,项目矩阵无法固定,可能存在退化到O(L2)的风险。Transformer- xl和compression Transformer 使用辅助隐藏状态捕获远程依赖性,这可能放大限制1,不利于打破效率瓶颈。这些工作主要集中在限制1上,而限制2和3在LSTF问题中一直没有得到解决。为了提高预测能力,我们解决了所有这些限制,并在建议的信息提供者中实现了超越效率的改进。
为此,我们的工作明确地探讨了这三个问题。我们研究了自注意机制中的稀疏性,对网络组件进行了改进,并进行了大量的实验。本文的贡献总结如下:
1在LSTF问题中,我们提出了Informer来成功地提高预测能力,从而验证了the Transformer-like models在捕获长序列时间序列输出和输入之间的单个远程依赖性方面的潜在价值。
2我们提出ProbSparse自注意机制来有效地取代规范的自注意机制。它在依赖对齐上实现了O(Llog L)时间复杂度和O(LlogL)内存使用。
3我们提出了自我注意蒸馏操作,以特权占主导地位的注意评分j堆叠层和将总空间复杂度大幅降低为O((2−?)L log L),便于接收长序列输入。我们提出生成式译码器,以获取长序列输出,只需要一个向前的步骤,同时避免在推断阶段累积错误的扩散。

图2:通知器模型概述。左:编码器接收大量的长序列输入(绿色序列)。我们用提出的ProbSparse自我注意来取代规范的自我注意。蓝色梯形为自注意蒸馏操作,提取支配性注意,大幅缩小网络规模。层堆叠副本增加了鲁棒性。右:译码器接收长序列输入,将目标元素填充为零,测量特征图的加权注意组成,并以生成式的方式即时预测输出元素(橙色序列)。
我们首先给出了LSTF问题的定义。在固定窗口大小的滚动预测设置下,我们有输入Xt = {xt1,…, xtLx | xti∈Rdx}在t时刻,输出为预测对应序列Yt = {yt1,…, yly | yti∈Rdy}。LSTF问题鼓励的输出长度Ly比以前的工作,特征维不限于单变量情况(dy≥1)。
编码器-解码器体系结构许多流行的模型被设计成将输入表示X t“编码”为隐藏状态表示Ht,并将输出表示Yt从Ht = {ht1,…, htLh}。推理涉及一个名为“动态解码”的逐步过程,其中解码器从前一个状态htk计算一个新的隐藏状态htk+1,从第k步计算其他必要的输出,然后预测(k +1)-第(k +1)个序列ytk+1。
为了增强时间序列输入的全局位置上下文和局部时间上下文,提出了一种统一的输入表示。为了避免简化描述,我们将细节放在附录B中。
现有的时间序列预测方法大致可分为两类。经典时间序列模型是时间序列预测的可靠工具 ,深度学习技术主要通过使用RNN及其变体开发编码器-解码器预测范式。我们提出的Informer在针对LSTF问题的同时保持了编码器-解码器的架构。图(2)为概述,下文为详细内容。
高效Self-attention机制
中的规范自注意定义基于元组输入,即查询、键和值,其执行缩放点积为A(Q, K, V) = Softmax(QK>/√d)V,其中Q∈RLQ×d, K∈RLK×d, V∈RLV ×d, d为输入维数。为了进一步探讨自我注意机制,设qi、ki、vi分别代表Q、K、V中的第i行。按照中的公式,第i个查询的注意力被定义为概率形式的核平滑器:

其中p(kj|qi) = k(qi, kj)/ p l k(qi, kl), k(qi, kj)选择非对称指数核exp(qik>j /√d)。自我注意结合这些值,并根据计算概率p(kj|qi)获得输出。它需要二次乘点积计算和O(LQLK)内存使用,这是提高预测能力的主要缺点。
先前的一些尝试表明,自我注意概率的分布具有潜在的稀疏性,他们设计了对所有p(kj|qi)的“选择性”计数策略,而不显著影响性能。稀疏变压器(Child et al. 2019)合并了行输出和列输入,其中稀疏性来自分离的空间相关性。LogSparse Transformer (Li等人,2019)注意到自我注意中的循环模式,并迫使每个单元以指数步长关注前一个单元。Longformer (Beltagy, Peters和Cohan 2020)将之前的两个工作扩展到更复杂的稀疏配置。但是,它们都局限于从启发式的方法进行理论分析,用相同的策略来处理每一个多头的自我注意,这限制了它们的进一步改进。
为了激发我们的研究方法,我们首先对典型自我注意的习得性注意模式进行了定性评估。“稀疏性”自我注意评分形成长尾分布(详见附录C),即少数点积对贡献主要注意,其他点积对产生琐碎注意。那么,下一个问题是如何区分它们?
从式(1)中,第i个查询对所有键的注意被定义为概率p(kj|qi),输出是它与值v的组合。优势点积对促使相应查询的注意概率分布远离均匀分布。如果p(kj|qi)接近均匀分布q(kj|qi) = 1/LK,则自我注意变为V值的平凡和,对常驻输入是冗余的。自然,分布p和q之间的“相似性”可以用来区分“重要的”查询。我们通过Kullback-Leibler散度KL(q||p) = ln PLKl=1 eqik>l /√d−1 LK PLKj=1 qik>j /√d−ln LK来度量“相似度”。去掉常数,我们定义第i个查询的稀疏度量为
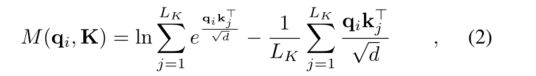 其中第一项是所有键上qi的Log-Sum-Exp (LSE),第二项是它们的算术平均值。如果第i个查询获得较大的M(qi, K),则其注意概率p更“多样化”,并且有很高的机会包含长尾自注意分布报头字段中的优势点积对。
其中第一项是所有键上qi的Log-Sum-Exp (LSE),第二项是它们的算术平均值。如果第i个查询获得较大的M(qi, K),则其注意概率p更“多样化”,并且有很高的机会包含长尾自注意分布报头字段中的优势点积对。
ProbSpare Self-attention 基于提出的度量,我们通过允许每个键只关注u个主要查询来获得ProbSparse自我注意:
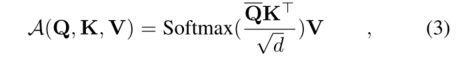 其中Q是一个与Q大小相同的稀疏矩阵,它只包含稀疏度量M(Q, K)下的Top-u查询。在恒定的采样因子c控制下,我们设u = c·ln LQ,这使得ProbSparse自注意每次查询键查找只需要计算O(ln LQ)点积,层内存使用保持O(LK ln LQ)。在多头透视图下,这种注意为每个头生成不同的稀疏查询键对,从而避免了严重的信息丢失
其中Q是一个与Q大小相同的稀疏矩阵,它只包含稀疏度量M(Q, K)下的Top-u查询。在恒定的采样因子c控制下,我们设u = c·ln LQ,这使得ProbSparse自注意每次查询键查找只需要计算O(ln LQ)点积,层内存使用保持O(LK ln LQ)。在多头透视图下,这种注意为每个头生成不同的稀疏查询键对,从而避免了严重的信息丢失
然而,遍历度量M(qi, K)的所有查询需要计算每个点积对,即二次O(LQLK),此外,LSE操作有潜在的数值稳定性问题。基于此,我们提出了一个有效获取查询稀疏性度量的经验近似。
**Lemma1:**F或键集K中的
根据引理1 我们提出最大均值测量为
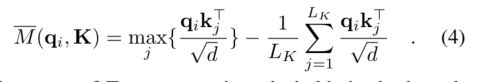
Top-u的取值范围近似保持在命题1的边界松弛。在长尾分布下,我们只需要对U = LK ln LQ点积对进行随机抽样,就可以计算M(qi, K),即用零填充其他点积对。然后从中选取稀疏Top-u作为q。M(qi, K)中的最大值算子对零值不太敏感,数值稳定。在实践中,在自注意计算中,查询和键的输入长度通常是等价的,即LQ = LK = L,使得ProbSparse自注意总时间复杂度和空间复杂度为O(L ln L)。

图3:inform编码器中的单个堆栈。水平堆栈表示图(2)中编码器副本中的单个一个。(2)给出的是接收整个输入序列的主栈。然后第二个堆栈接受输入的一半切片,随后的堆栈重复。(3)红色层为点积矩阵,通过对每层进行自注意蒸馏得到级联递减。(4)将所有栈的特征映射连接成编码器的输出。
编码器:允许在内存使用限制下处理较长的顺序输入
编码器的设计目的是提取长序列输入的健壮的远程依赖性。输入表示完成后,第t个序列输入Xt被塑造成矩阵Xten∈RLx×dmodel。为了清晰起见,我们在图(3)中给出了编码器的草图。
作为ProbSparse自注意机制的自然结果,编码器的特征映射具有v值的冗余组合。我们使用蒸馏操作,以支配特征优先于优势特征,在下一层生成一个集中的自注意特征映射。它大幅修剪了输入的时间维度,如图(3)所示,注意块的n个头权重矩阵(重叠的红色方块)。受扩张卷积的启发(Y u, Koltun,和Funkhouser 2017;Gupta和Rush 2017),我们的“蒸馏”过程从第j层向前推进到(j + 1)-第j层:
![]()
其中[·]AB表示注意块。它包含多头ProbSparse自注意和基本操作,其中Conv1d(·)使用ELU(·)激活函数(Clevert, Unterthiner, and Hochreiter 2016)在时间维度上执行一维卷积滤波器(核宽度=3)。我们在堆叠一层后,添加一个最大池化层,stride为2,向下采样Xt到它的半片,这将整个内存使用量减少到O((2−?)llogl),在哪里?是一个很小的数字。为了增强蒸馏操作的鲁棒性,我们构建了输入减半的主堆栈副本,并通过每次下降一层来逐步减少自我注意蒸馏层的数量,就像图(2)中的金字塔,这样它们的输出维度是对齐的。因此,我们将所有堆栈的输出连接起来,得到编码器的最终隐藏表示。
Decoder:Generating Long Sequential Outputs Through One Forward Procedure
我们使用图(2)中的标准解码器结构(V aswani et al. 2017),它由两个相同的多头注意层组成。而生成推理则是用来缓解长时间预测的速度骤降。
我们向解码器输入以下向量为
![]()
其中Xttoken∈RLtoken×dmodel是开始令牌,Xt0∈RLy×dmodel是目标序列的占位符(设标量为0)。通过将掩码点乘积设为−∞,在ProbSparse自注意计算中应用掩码多头注意。它可以防止每个位置指向下一个位置,从而避免自回归。一个完全连接的层获得最终的输出,它的外值dy取决于我们执行的是单变量预测还是多元预测。
Generation Inference生成推理开始标记有效地应用于NLP的“动态解码”(Devlin et al. 2018),并且我们将其扩展为生成的方式。我们没有选择特定的标志作为令牌,而是在输入序列中对Ltoken长的序列进行采样,例如在输出序列之前的早期片。以预测168点为例(实验部分7天温度预测),取目标序列前已知的5天作为“starttoken”,向生成式推理解码器输入Xde = {X5d, X0}。X0包含目标序列的时间戳,即目标周的上下文。然后,我们提出的解码器通过一个前向过程来预测输出,而不是传统编码器-解码器架构中耗时的“动态解码”。在计算效率部分给出了详细的性能比较。
Loss function我们在预测w.r.t目标序列上选择MSE损失函数,损失从解码器的输出传播回整个模型。

实验数据集我们在四个数据集上进行了广泛的实验,包括LSTF收集的2个真实世界数据集和2个公共基准数据集。
ETT(电力变压器温度)2:ETT是电力长期部署的一个重要指标。我们从中国两个不同的县收集了两年的数据。为了探究LSTF问题的粒度,我们创建了单独的数据集,如1小时级别的{ETTh1, ETTh2}和15分钟级别的etm1。每个数据点由目标值“油温”和6个电力负荷特征组成。培训/考试/测试是12月4日4个月。ECL(耗电负荷)3:收集321个客户端的耗电量(Kwh)。由于数据缺失(Li et al. 2019),我们将数据集转换为2年的小时消耗,并设置“MT 320”为目标值。培训/考试/测试是15/3/4个月。
天气4:该数据集包含2010年至2013年4年间美国近1600个地点的当地气候数据,每1小时收集一次数据点。每个数据点包括目标值“湿球”和11个气候特征。培训/考试/测试是28/10/10个月。
Experimental Details
我们简要总结了基础知识,附录E给出了更多关于网络组件和设置的信息。基线:我们选择了五种时间序列预测方法进行比较,包括ARIMA (Ariyo, Adewumi,和Ayo 2014)、Prophet (Taylor and Letham 2018)、LSTMa (Bahdanau, Cho,和Bengio 2015)、LSTnet (Lai et al. 2018)和DeepAR (Flunkert, Salinas,和Gasthaus 2017)。为了更好地探索ProbSparse自我注意在我们提出的Informer中的性能,我们在实验中纳入了规范自我注意变体(Informer)、Refomer(Kitaev, Kaiser,和Levskaya 2019)和最相关的LogSparse自我注意工作(Li等人2019)。网络组件的详细信息见附录E.1。超参数调优:我们对超参数进行网格搜索,详细范围在附录E.3中给出。在编码器中包含3层堆栈和1层堆栈(1/4输入),以及2层解码器。本文提出的方法采用Adam优化器进行优化,其学习速率从1e−4开始,每一个epoch衰减0.5倍。在适当的早期停止的情况下,总周期数为8。我们按照推荐的方法设置了比较方法,批大小为32。设置:每个数据集的输入都是零均值归一化的。在LSTF设置下,
我们逐步延长预测窗口大小Ly,即{ETTh, ECL, Weather}的{1d, 2d, 7d, 14d, 30d, 40d}, ETTm的{6h, 12h, 24h, 72h, 168h}。指标:我们使用两个评估指标,包括MSE =1 n Pn i=1(y−@ @)2和MAE =1 n Pn i=1 |y−@ @ |在每个预测窗口上(多元预测的平均值),并以stride =1滚动整个集合。平台:所有模型都在单个Nvidia V100 32GB GPU上进行训练/测试。源代码可在https://github.com/zhouhaoyi/Informer2020获得。
Results and Analysis
表1和表2汇总了4个数据集上所有方法的单因素/多因素评价结果。随着对预测能力的要求越来越高,我们逐渐延长了预测周期,其中每种方法的LSTF问题设置被精确地控制在单一GPU上可处理。最好的结果用黑体突出显示。
Unvariate Time-series Forecasting
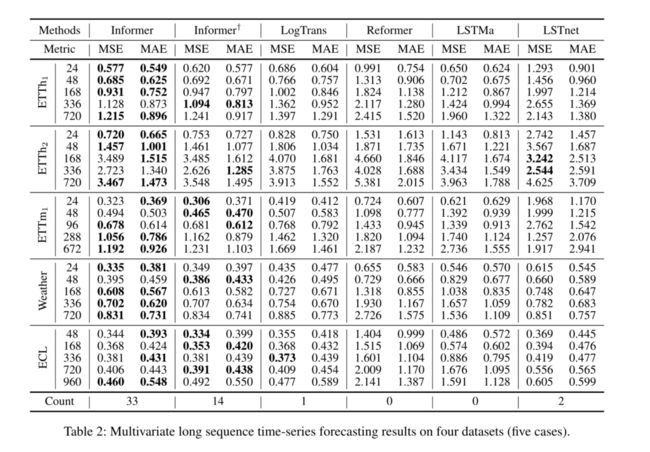
单变量时间序列预测在这种设置下,每种方法都可以在时间序列中实现单变量的预测。从表1可以看出:(1)所提模型Informer显著提高了所有数据集的推理性能(最后一列的获胜计数),其预测误差在不断增长的预测范围内平稳而缓慢地上升,证明了Informer在提高LSTF问题预测能力方面的成功。(2) Informer优于它的正则退化Informer†主要是获胜计数,即32>12,这支持提供的查询稀疏性假设一个比较的注意力特征图。我们提出的方法也比最相关的工作LogTrans和改革者。我们注意到,改革器保持动态解码,在LSTF中性能很差,而其他方法作为非自回归预测器从生成式解码器中受益。(3) inform模型的结果明显优于循环神经网络LSTMa。我们的方法MSE下降了26.8%(在168处),52.4%(在336处)和60.1%(在720处)。这表明,自注意机制中较短的网络路径比基于rnn的模型获得了更好的预测能力。(4)该方法在MSE上比DeepAR、ARIMA和Prophet平均下降49.3%(在168点)、61.1%(在336点)和65.1%(在720点)。在ECL数据集上,DeepAR在较短的视距上(≤336)表现更好,而我们的方法在较长的视距上表现更好。我们将其归因于一个具体的例子,在这个例子中,预测能力的有效性与问题的可伸缩性相关联。
Multivariate Time-series Forecasting
在这种情况下,一些单变量方法是不合适的,LSTnet是最先进的基线。相反,通过调整最终的FCN层,我们提出的Informer很容易从单变量预测变为多变量预测。从表2中,我们观察到:(1)所提出的模型inform大大优于其他方法,并且在单变量设置下的结果1和2对于多变量时间序列仍然成立。(2) Informer模型比基于rnn的LSTMa和基于cnn的LSTnet模型有更好的结果,MSE减小平均为26.6%(168名)、28.2%(336名)、34.3%(720名)。与单变量结果相比,压倒性性能下降,这可能是由于特征维预测能力的各向异性造成的。这超出了本文的讨论范围,我们将在以后的工作中对此进行探讨。

LSTF with Granularity Consideration
我们执行一个额外的比较,以探索不同粒度下的性能。etm1(分钟级)的序列{96,288,672}与ETTh1(小时级)的{24,48,168}对齐。即使序列在不同的粒度级别上,inform也优于其他基线。
Paraneter Sensitivity
在单变量设置下,我们对ETTh1上提出的inform模型进行了敏感性分析。输入长度:在图(4a)中,在预测短序列(如48)时,最初增加编码器/解码器的输入长度会降低性能,但进一步增加会导致MSE下降,因为它会带来重复的短期模式。然而,在预测长序列(如168)时,输入越长MSE越低。因为较长的编码器输入可能包含更多的依赖项,而较长的解码器令牌具有丰富的本地信息。采样因子:采样因子控制式(3)中ProbSparse自注意的信息带宽。我们从小事做起系数(=3)增大,总体性能略有提高,最后在图(4b)中趋于稳定。验证了我们的查询稀疏性假设,即在自注意机制中存在冗余点积对。在实践中,我们设样本因子c = 5(红线)。层叠加的组合:层的副本是自我注意蒸馏的互补,我们在图(4c)中研究了每个堆栈{L, L/2, L/4}的行为。较长的堆栈对输入更敏感,部分原因是接收更多的长期信息。我们的方法的选择(红线),即连接L和L/4,是最稳健的策略。
Ablation Study:How well Informer works?
我们还对ETTh1进行了额外的消融实验。
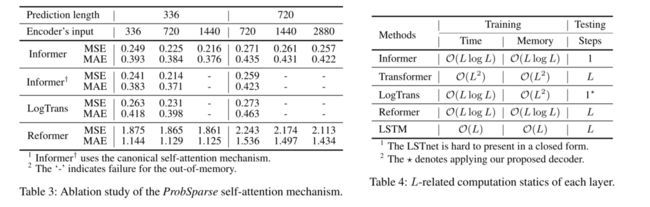
The performance of Probspare self-attention mechanism
在总体结果表1和表2中,我们限制了问题设置,以使规范自我注意的内存使用可行。在这项研究中,我们将我们的方法与LogTrans和改革者进行了比较,并彻底探索了它们的极限性能。为了隔离内存效率问题,我们首先减少设置为{batch size=8, heads=8, dim=64},并在单变量情况下保持其他设置。在表3中,ProbSparse自我注意的性能优于其他方法。LogTrans在极端情况下得到OOM,因为它的公共实现是完全注意的掩码,仍然有O(L2)的内存使用。我们提出的ProbSparse自注意避免了Eq.(4)中查询稀疏性假设带来的简单性,参考附录E.2中的伪代码,达到了更小的内存使用量。
The performance of self-attention distilling
在本研究中,我们使用informer†作为基准,以消除ProbSparse自我注意的额外影响。另一个实验设置与单变量时间序列设置一致。从表5可以看出,利用长序列输入后,informix†完成了所有的实验,并取得了更好的性能。Informer传统的比较方法去除了蒸馏操作,得到了输入较长的OOM(> 720)。关于长序列输入在LSTF问题中的好处,我们得出结论,自注意蒸馏是值得采用的,特别是当需要较长的预测时。
The performance of generative style decoder
在本研究中,我们证明了我们的解码器在获得“生成”结果方面的潜在价值。与现有方法不同的是在训练和推理中,标签和输出被强制对齐,我们提出的解码器的预测完全依赖于时间戳,它可以用偏移量进行预测。从表6可以看出,随着偏移量的增加,算法的一般预测性能有抵抗性,而对动态解码而言,算法失败。它证明了解码器能够捕获任意输出之间的独立远程依赖关系并避免错误积累。
Computation Efficiency
通过多元设置和所有方法当前的最佳实现,我们在图(5)中进行了严格的运行时比较。在训练阶段,基于transformer的方法中,Informer(红线)的训练效率最好。在测试阶段,我们的方法比使用生成式解码的其他方法快得多。理论时间复杂度和内存使用情况的比较如表4所示。informix的性能与运行时实验一致。注意,LogTrans专注于改进自我注意机制,我们在LogTrans中应用我们提出的解码器进行公平的比较(在表4)。
Conclusion
本文研究了长序列时间序列预测问题,提出了长序列预测的Informer方法。具体而言,我们设计了ProbSparse自注意机制和蒸馏操作,以应对vanilla Transformer二次时间复杂度和二次内存使用的挑战。此外,精心设计的生成式解码器减轻了传统编码器-解码器架构的局限性。在实际数据上的实验证明了该方法在提高LSTF问题预测能力方面的有效性。
Acknowledgment
国家自然科学基金项目(U20B2053、61872022、61421003)和软件开发环境国家重点实验室(sklde - 2020zx -12)资助。感谢北京大数据与脑计算先进创新中心提供的计算基础设施。该作品也得到了中国教育学会-华为思维孢子开放基金的资助。通讯作者:李建新
Ethics Statement
该方法能够处理长输入并进行高效的长序列推理,可用于具有挑战性的长序列时序预测(LSTF)问题。重要的现实应用包括传感器网络监测(Papadimitriou和Yu 2006)、能源和智能电网管理、疾病传播分析(Matsubara等人2014)、经济和金融预测(Zhu和Shasha 2002)、农业生态系统的演变、气候变化预测和空气污染的变化。作为一个具体的例子,网上卖家可以预测每月的产品供应量,这有助于优化长期库存管理。它与其他时间序列问题的显著区别是对预测能力的要求很高。我们的贡献不仅限于LSTF问题。除了获取长序列外,我们的方法还可以为其他领域带来实质性的好处,例如文本、音乐、图像和视频的长序列生成。
在伦理考虑下,任何从历史数据中学习的时间序列预测应用都有产生偏颇预测的风险。这可能会给财产/资产的真正所有者造成无法弥补的损失。我们的方法需要领域专家的指导,而长序列预测也可以为领域专家的工作提供帮助。以我们的方法应用于电力变压器温度预测为例,管理者将对结果进行检验,并决定未来的电力部署。如果有一个足够长的预测,它将有助于管理者在早期阶段防止不可逆转的失败。除了识别偏倚数据外,一种很有前途的方法是采用迁移学习。我们将收集到的数据(ETT数据集)捐赠给供水管理和5G网络部署等相关课题的进一步研究。另一个缺点是我们的方法需要高性能的GPU,这限制了它在欠发达地区的应用。