当CNN遇见Transformer!华为诺亚提出CMT:新视觉Backbone
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:AIWalker

Vision Transformers
论文:https://arxiv.org/abs/2107.06263
本文是华为诺亚与悉尼大学在Transformer+CNN架构混合方面的尝试,提出了一种同时具有Transformer长距离建模与CNN局部特征提取能力的CMT。相比之前的各种Transformer变种,本文更倾向于将Transformer的优势集成到CNN中。整体架构采用了ResNet的分阶段架构,Normalization方面采用CNN中常用的BN而非Transformer中的LN,在核心模块CMTBlock方面,内部设计了具有局部特征提取的LPU,在降低计算量方面对K与V进行了特征分辨率的下降,与此同时将MobileNetV2中的逆残差思想引入到FFN中得到了IRFFN。总而言之,CMT代表着CV中的Transformer架构趋势又回到了CNN原先研究路线:即CNN为主,其他领域思想为辅。
Abstract
由于其所具有的长距离依赖建模能力,Vision Transformers已被成功应用到图像识别任务中。然而,其性能与计算量距离优秀的CNN仍存在差距。
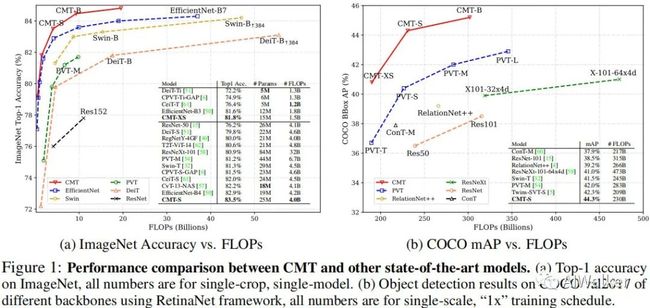
为解决上述问题,我们设计了一种新的网络CMT,它不仅由于Transformer,同时优于高性能CNN。所提CMT是一种混合CNN与Transformer的架构,它同时利用率Transformer的长距离建模与CNN的局部特征提取能力。具体来说,所提CMT-S取得了83.5%的top1精度,同时比现有的DeiT快14倍,比EfficientNet快2倍。所提CMT-S同样具有非常耗的繁华性能,比如CIFAR10取得了99.2%,CIFAR100上取得了91.7%,Flowers上取得了98.7%,COCO上取得了44.3%mAP。
Method
本文的初衷是构建一种混合网络,它同时利用CNN与Transformer的优势。下图给出了ResNet50、DeiT以及所提CMT的网络架构示意图。
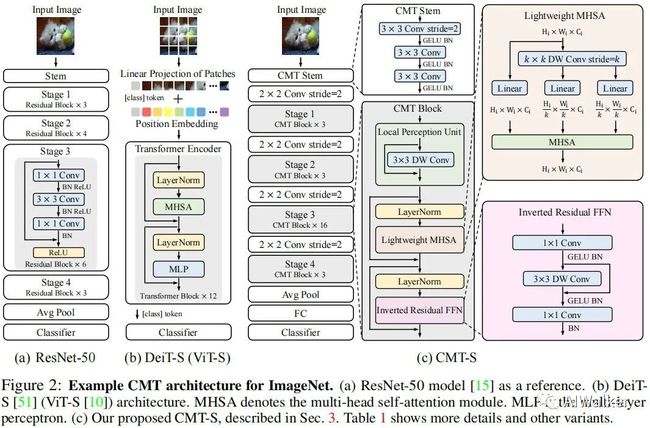
如上图所示,DeiT直接将输入图像拆分为非重叠图像块,图像块的结构信息则通过线性投影方式弱建模。为克服改据先洗个,我们采用类似ResNet的stem架构,它由三个 卷积构成,但激活函数采用了GELU,而非ResNet的ReLU。
类似经典CNN(如ResNet)架构设计,所提CMT包含四个阶段以生成多尺度特征(这对于稠密预测任务非常重要)。为生成分层表达,在每个阶段开始之前采用 卷积降低特征分辨率并提升通道维度。在每个阶段,堆叠多个CMT模块进行特征变换同时保持特征分辨率不变,每个CMT模块可以同时捕获局部与长距离依赖关系。在模型的尾部,我们采用GAP+FC方式进行分类。
给定输入图像,我们可以得到四个不同分辨率的分层特征,类似于经典的CNN(ResNet, EfficientNet)。所得四个不同分辨率的特征对应的stride分别为4、8、16、32,因此,CMT所得多尺度特征表达可以轻易应用到下游任务(比如检测与分割)中。
CMT Block
所提CMT模块包含一个局部感知单元(Loal Perception Unit, LPU)、一个轻量型多头自注意力模块(Lightweight Multi-Head Self-Attention, LMHSA)以及一个逆残差前馈网络(Inverted Residual Feed-Forward Network, IRFFN)。
Local Perception Unit 旋转与平移是视觉任务中两种常见数据增广方法,这些操作应当不能影响模型最终的结果。然而,Transformer中的绝对位置编码会破坏该不变性。此外,Transformer忽略了块内的局部相关性与结构信息。为缓解该限制,我们提出了局部感知单元以提升局部信息,定义如下:
Lightweight Multi-Head Self-Attention 在原始的自注意力模块中,输入X线性变换为Q、K以及V,然后通过如下方式执行自注意力操作:
为减少计算复杂度,我们采用 深度卷积降低K与V的空间尺寸,即。此外,类似Swin,我们在自注意力模块中添加了相对位置偏置B:
Inverted Residual Feed-forward Network 原始的FFN仅包含两个全连接层+GeLU,第一个FC用于扩展特征维度,第二个FC用于降低特征维度:
本文所提IRFFN采用了类似MobileNetV2的逆残差模块,包含一个扩展层、深度卷积以及投影层。具体来说,我们改变了短连接的位置以获得更好的性能:
注: 这里在推理阶段可以进行合并,即跳过连接可以移除掉。它的作用则是利用微小的代价提取局部解雇信息。
基于上述所提到的三个成分,CMT模块定义如下:
Complexity Analysis
接下来,我们对ViT与CMT的计算量复杂度进行分析。标准的Transformer模块包含MHSA与FFN,假设输入特征尺寸为 ,那么整体计算复杂度为:
因此,当 时,ViT中的Transformer计算复杂度表示如下:
采用类似ViT的配置,CMT的计算量复杂度表示如下:
相比ViT,CMT对计算复杂度更友好,可以处理更高分辨率的特征。
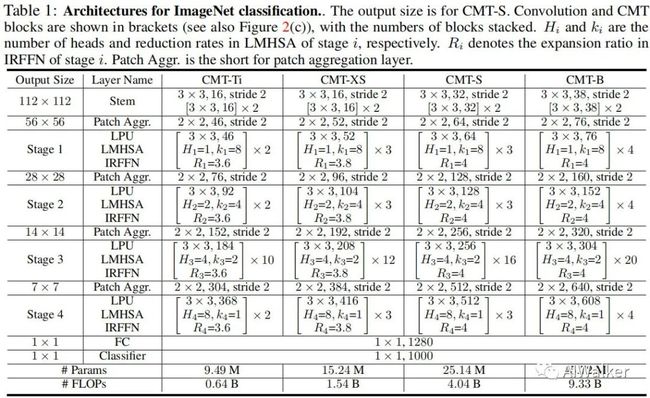
Scaling Strategy
受启发于EfficientNet,我们提出了一种适用于Transformer的复合缩放策略:它采用复合系数 均匀的调整深度、维度以及输入分辨率:
注:在实验中,我们设置 。下表给出了不同复杂度的CMT模型配置信息。
Experiments
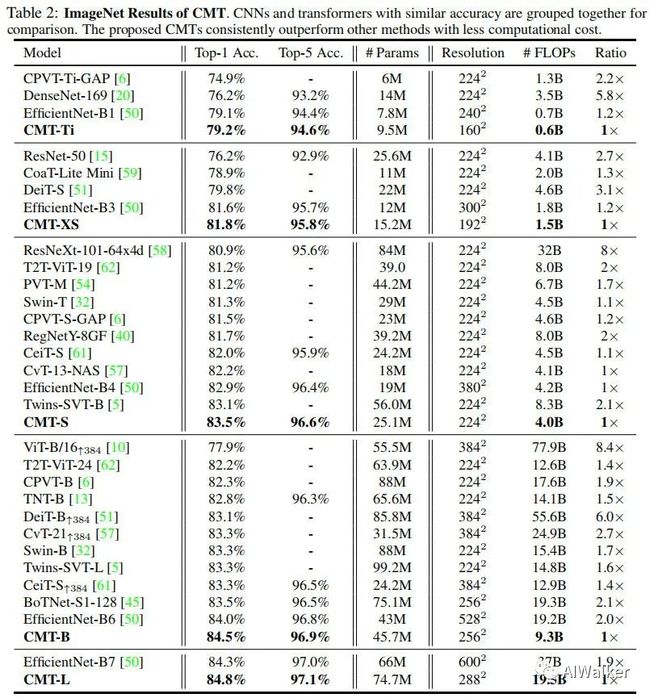
上表给出了所提方法与其他CNN、Transformer的性能对比,从中可以看到:
所提CMT取得了更佳的精度,同时具有更少的参数量、更少的计算复杂度;
所提CMT-S凭借4.0B FLOPs取得了83.5%的top1精度,这比DeiT-S高3.7%,比CPVT高2.0%;
所提CMT-S比EfficientNet-B4指标高0.6%,同时具有更低的计算复杂度。
Transfer Learning
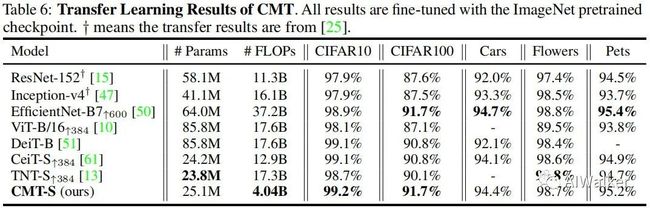
上表对比了所提方法在不同分类数据集上的迁移学习能力,从中可以看到:
在所有数据集上,CMT-S均优于其他Transformer模型,同时具有更少的FLOPs;
CMT-S取得了与EfficientNet-B7相当的性能,同时具有少9倍的FLOPs。
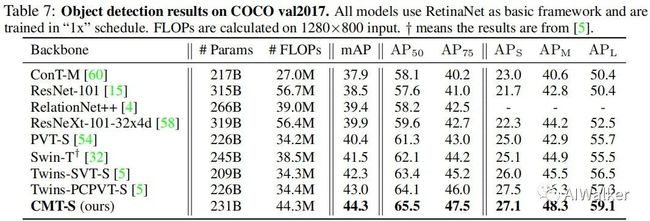
上表给出了所提方法在COCO检测数据集上的迁移学习性能对比,从中可以看到:以RetinaNet作为基础框架,CMT-S取得了比Twins-PCPVT-S高1.3%mAP,比Twins-SVT-S高2.0%mAP的性能。
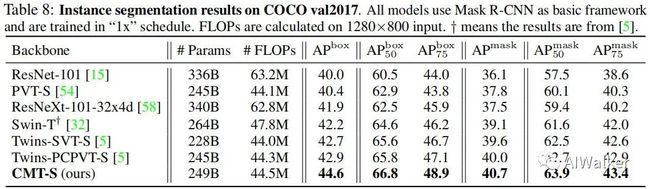
上表给出了所提方法在COCO实例分割任务上的性能对比,可以看到:以Mask R-CNN为基础框架,CMT-S取得了比Twins-PCPVT-S高1.7%AP,比Twins-SVT-S高1.9%AP的性能。
Inference Speed
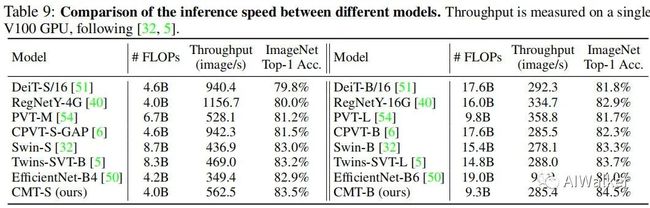
上表给出了所提CMT-S与CMT-B在ImageNet上的推理速度对比,从中有看到:所提CMT具有更佳的速度-精度均衡。速度最快的还是恺明大神等人提出的RegNetY。
Ablation Study
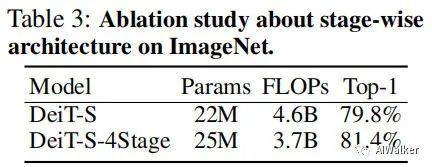
上表对比了分阶段架构的性能对比,可以看到:当为DeiT插上分阶段的思想后,其性能取得了1.6%的提升,同时具有更少的FLOPs。
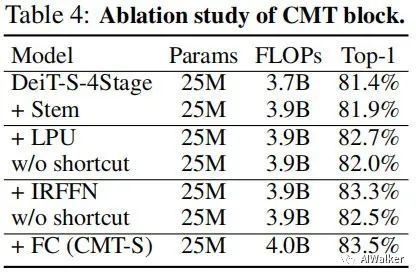
上表对比了所提CMT不同模块的作用,从中可以看到:
引入Stem可以带来0.5%的性能提升;
所提LPU与IRFFN可以分别进一步提升0.8%与0.6%;
LPU与IRFFN中的短连接对于最终的性能同样非常重要。
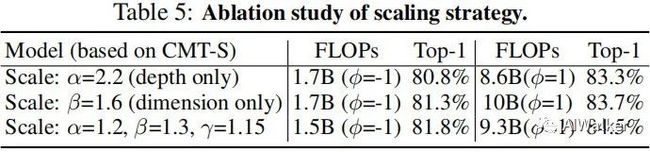
上表对比了不同缩放策略的性能对比,可以看到:单一缩放策略的性能不如符合缩放策略。
CVPR和Transformer资料下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的两篇Transformer综述PDF
CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer 微信交流群,方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲长按加小助手微信,进交流群▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看