LeViT: a Vision Transformer in ConvNet‘s Clothing for Faster Inference
文章目录
- 前言
- 1. 模型
-
- 1.1 设计原则
- 1.2 模型组件
-
- patch embedding
- no classitication token
- normalization layers and activations
- Multi-resolution pyramid
- Downsampling
- Attention bias instead of a positional embedding
- Smaller keys
- Attention activation
- Reducing the MLP blocks
- 1.3 网络结构图
- 2. 代码
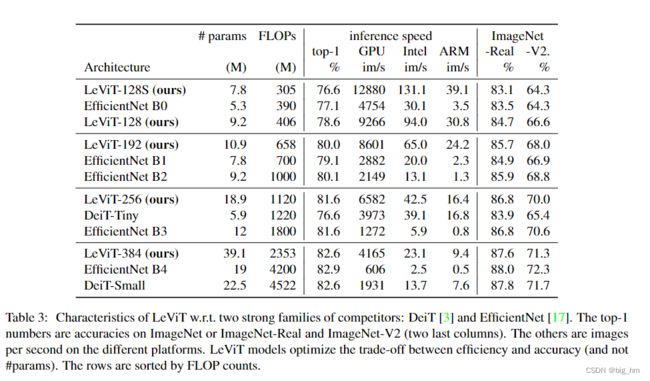
- 3. 实验结果
前言
论文链接:https://arxiv.org/abs/2104.01136
代码链接:https://github.com/facebookresearch/LeViT
ViT -> DeiT -> LeViT
DeiT不改变ViT的架构,用好的超参和加入了一个distillation token提高了性能,减少了计算量。
LeViT在transformer中引入卷积,使模型更小(width and spatial resolution),推理更快。还引入了注意偏差attention bias,一种在视觉transformer中整合位置信息的新方法。
本文主要贡献:
- 一个将注意力作为下采样机制的multi-stage transformer
- 一种计算效率高的patch descriptor,可减少第一层中的特征数量。
- 一种学习到的、per-head translation-invariant 的attention bias,取代了ViT的position embedding
- 重新设计的attention-MLP block,在给定计算时间内提高了网络容量。

1. 模型
1.1 设计原则
第一步:获得一个可共用的representation。
将classification embedding的作用打折扣,ViT是一个处理activation maps的stack of layers. 实际上中间的token embeddings可以认为是FCN中的传统 C C Cx H H Hx W W Wactivation maps. 因此,那些给activation maps的操作,如池化,卷积,可以用在DeiT的中间representation上。
1.2 模型组件
patch embedding
作者实验证明在transformer stack的输入前加一个小的卷积网络可以提高精度。
no classitication token
为了使用BCHW张量格式,本文删除了分类token。
与卷积网络类似,在最后一个activation map上将其替换为平均池化,从而生成用于分类器的embedding。
对于训练期间的蒸馏,本文为分类和蒸馏任务训练单独的head。
在测试时,本文平均两个head的输出。实际上,LeViT可以使用BNC或BCHW张量格式实现,以更有效的为准。
normalization layers and activations
ViT中的FC层,等价于1x1卷积,ViT在每个attention和MLP之前用layer normalization. 对于LeViT,会在每个卷积后面跟一个batch normalization,每个batch normalization权重参数都会加入一个被初始化为0的残差连接,batch normalization可以与前面的卷积合并进行推理,对于layer normalization有运行时间上的优势。虽然DeiT使用GELU函数,但LeViT的所有非线性激活都是Hardswish(Searching for MobileNetV3)
Multi-resolution pyramid
类似金字塔结构,activation map的分辨率会越来越低,本文将这种方式与transformer架构结合。
Downsampling
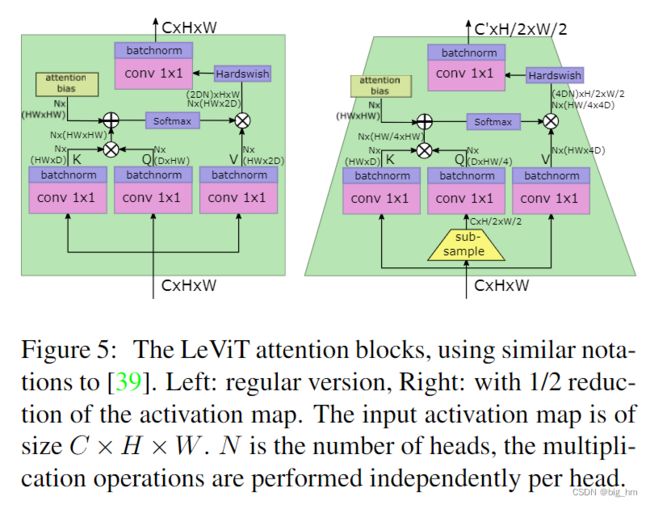
在stage之间,本文用了一个shrinking attention block来减小activation map的大小:
在Q transformation之前应用子采样subsampling,然后传播到软激活的输出。这将大小为(C, H, W)的输入张量映射为大小为(C′,H/2,W/2)且C′>C的输出张量。
由于比例的变化,使用此注意块时没有残差连接。为了防止信息丢失,本文将注意头的数量设为C/D
Attention bias instead of a positional embedding
作者做了消融实验认为transformer中的positional embedding导致了分类精度的急剧下降。
但是positional embedding对于更高的层很重要,于是可以将其保留在中间representation 中,并且不必使用representation 能力。
因此,本文的目标是在每个注意块中提供位置信息,并在注意机制中明确注入相对位置信息:只需在attention map中添加attention bias.
Smaller keys
bias项减少了对keys编码位置信息的压力,因此作者减少了keys矩阵相对于V矩阵的大小。如果keys尺寸为 D ∈ { 16 , 32 } D∈ \{16,32\} D∈{16,32},V将有2D通道。限制keys的大小减少了计算 Q K T QK^T QKT所需的时间。
对于没有残差连接的下采样层,作者将V的尺寸设置为4D,以防止信息丢失。
Attention activation
在使用规则线性投影组合不同head的输出之前,作者对 A h V A^hV AhV应用了Hardwish激活。
这类似于ResNet bottleneck残差块,因为V是1×1卷积的输出, A h V A^hV AhV 对应空间卷积,投影层是另一个1×1卷积。
Reducing the MLP blocks
ViT中的MLP residual block是一个线性层,它将embedding dimension增加了4倍,它应用了一个非线性,并以另一个非线性将其减少到原始embedding dimension。
对于视觉体系结构,MLP在运行时间和参数方面通常比attention block花得更多。
对于LeViT,“MLP”是1×1卷积,后面跟着一个常见的BN。
为了减少该阶段的计算量,作者将卷积的expansion factor从4减少到2。
一个设计目标是注意块和MLP块消耗大约相同数量的FLOPs.
1.3 网络结构图
attention block 与带有下采样功能的attention block
2. 代码
//具有下采样功能的attention block
class Subsample(torch.nn.Module):
def __init__(self, stride, resolution):
super().__init__()
self.stride = stride
self.resolution = resolution
def forward(self, x):
B, N, C = x.shape
x = x.view(B, self.resolution, self.resolution, C)[:,::self.stride,::self.stride].reshape(B,-1,C)
return x
3. 实验结果