你的YOLO V4该换了 | YOLO V4原班人马改进Scaled YOLO V4,已开源(附论文+源码)
点击上方“码农的后花园”,选择“星标” 公众号
精选文章,第一时间送达

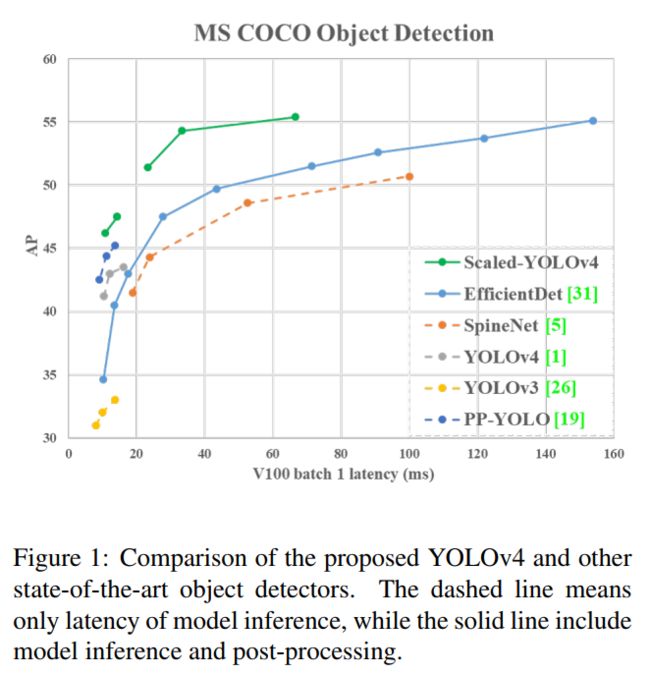
YOLOv4-large在COCO上最高可达55.8 AP!速度也高达15 FPS!YOLOv4-tiny的模型实现了1774 FPS!(在RTX 2080Ti上测试)
作者单位:YOLOv4原班人马
1、简介
基于CSP方法的YOLOv4目标检测方法,可以上下缩放,并且适用于小型和大型网络,同时保持速度和准确性。基于此本文提出了一种网络缩放方法,该方法不仅可以修改深度、宽度、分辨率,还可以修改网络的结构。YOLOv4-Large模型达到了最先进的结果:在Tesla V100上以15FPS/s的速度,MS COCO数据集的AP为55.8% AP(73.3%AP50)。这是目前所有已发表文章中COCO数据集的最高准确性。YOLOv4-tiny模型在RTX 2080Ti上以443FPS/s的速度实现了22.0%的AP(42.0%AP50),而使用TensorRT,batchsize=4和FP16精度,YOLOv4-tiny的模型实现了1774FPS/s。
2、Scaled YOLO V4
首先对YOLOv4进行了重新设计,提出了YOLOv4-CSP,然后在YOLOv4-CSP的基础上开发了Scaled-YOLOv4。在提出的Scaled-yolov4中讨论了线性缩放模型的上界和下界,并分析了小模型和大模型缩放时需要注意的问题。因此,能够系统地开发YOLOv4-Large和YOLOv4-Tiny模型。
Scaled-YOLOv4能够在速度和精度之间实现最好的平衡,能够在15fps、30fps和60fps的视频以及嵌入式系统上进行实时对象检测。
2.1、动机分析
在对所提出的对象检测器进行模型缩放后,下一步是处理将发生变化的定量因素,包括带有定性因素的参数的数量。这些因素包括模型推理时间、平均精度等。根据使用的设备或数据库,不同的定性因素会有不同的增益效果。
具体对定量因素的分析和设计,以及在低端设备和高端GPU上的微型对象检测器的定性因素。可以参见原论文。
2.2、Scaled-YOLOv4设计
在本节中将重点放在为一般gpu、低端gpu和高端gpu设计缩放YOLOv4上。
2.2.1、CSP-ized YOLOv4
1、Backbone
在Residual Block中下采样卷积计算中不包括跨级过程。因此,可以推断CSPDarknet每个阶段的计算量为 。
由前式可知,CSPDarknet stage只有在k>1时。CSPDarknet53中每个阶段拥有的Residual Layer层数分别为1-2-8-8-4。为了获得更好的速度/精度折中,这里将第一个CSP阶段转换为Original Darknet Residual Layer。具体结构如下图:

2、Neck
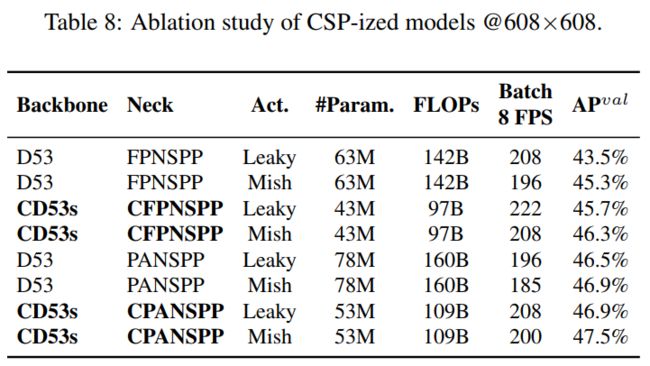
为了有效地减少计算量,文中对YOLOv4中的PAN体系结构进行了CSP-ize。PAN结构的计算列表如图2(a)所示。它主要整合来自不同特征金字塔的特征,然后通过两组反向的Original Darknet Residual Layer,没有shortcut连接。经过CSP-ize,新的计算列表的架构如图2(b)所示。这个设计有效地减少了40%的计算量。
3、SPP
SPP模块最初是插入在neck第一个计算列表组的中间位置。因此,作者也将SPP模块插入到CSP-PAN的第一个计算列表组的中间位置。
class CrossConv(nn.Module):
# Cross Convolution Downsample
def __init__(self, c1, c2, k=3, s=1, g=1, e=1.0, shortcut=False):
# ch_in, ch_out, kernel, stride, groups, expansion, shortcut
super(CrossConv, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, (1, k), (1, s))
self.cv2 = Conv(c_, c2, (k, 1), (s, 1), g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class C3(nn.Module):
# Cross Convolution CSP
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(C3, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)
self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)
self.cv4 = Conv(2 * c_, c2, 1, 1)
self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
self.act = nn.LeakyReLU(0.1, inplace=True)
self.m = nn.Sequential(*[CrossConv(c_, c_, 3, 1, g, 1.0, shortcut) for _ in range(n)])
def forward(self, x):
y1 = self.cv3(self.m(self.cv1(x)))
y2 = self.cv2(x)
return self.cv4(self.act(self.bn(torch.cat((y1, y2), dim=1))))
class Sum(nn.Module):
# Weighted sum of 2 or more layers https://arxiv.org/abs/1911.09070
def __init__(self, n, weight=False): # n: number of inputs
super(Sum, self).__init__()
self.weight = weight # apply weights boolean
self.iter = range(n - 1) # iter object
if weight:
self.w = nn.Parameter(-torch.arange(1., n) / 2, requires_grad=True) # layer weights
def forward(self, x):
y = x[0] # no weight
if self.weight:
w = torch.sigmoid(self.w) * 2
for i in self.iter:
y = y + x[i + 1] * w[i]
else:
for i in self.iter:
y = y + x[i + 1]
return y
2.3、YOLOv4-tiny
YOLOv4-tiny是专为低端GPU设备设计的:

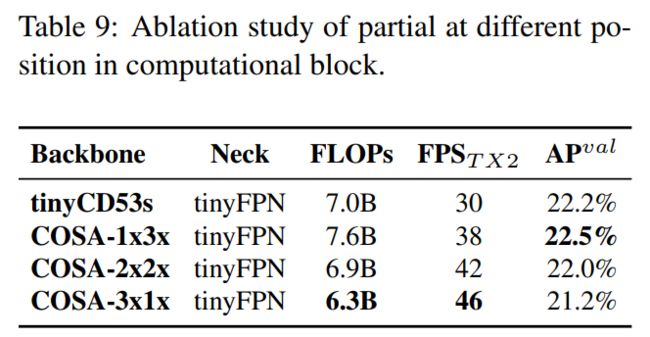
这里使用PCB架构的CSPOSANet来构成YOLOv4的主干。设g=b/2为增长率,最终使其增长到b/2+kg = 2b。通过计算得到k=3,其结构如图3所示。对于每个阶段的通道数量和Neck部分了采用YOLOv3-tiny的设计。
2.4、YOLOv4-large
YOLOv4-large是为云GPU设计的,主要目的是实现高精度的目标检测。这里设计了一个完全CSP-ize的模型:YOLOv4-P5,并将其扩展到YOLOv4-P6和YOLOv4-P7。

如图4所示为YOLOv4-P5、YOLOv4-P6、YOLOv4-P7的结构。作者设计在 #stage上执行复合缩放,并将每个阶段的深度尺度设置为 , ds为[1,3,15,15,7,7,7]。最后进一步使用推断时间作为约束来执行额外的宽度缩放。
实验表明,当宽度缩放因子为1时,YOLOv4-P6可以在30帧/秒的视频中达到实时性能。对于YOLOv4-P7来说,当宽度缩放因子等于1.25时,它可以在15fps的视频中达到实时性能。
3、实验结果
3.1、CSP-ized消融实验
3.2、YOLOv4-tiny消融实验

3.3、SOTA实验对比

论文和源代码获取方式,后台回复关键字:【项目实战】,即可获取。
参考:
[1].https://github.com/AlexeyAB/darknet
[2].https://github.com/WongKinYiu/PyTorch_YOLOv4
[3].Scaled-YOLOv4: Scaling Cross Stage Partial Network
[4] Real-time object detection method based on improved YOLOv4-tiny

更多优质内容?等你点在看
