深度学习之理解神经网络的四个公式
在这篇文章里面,我们探讨了:可以使用偏导值利用梯度下降来求权重w和b,但是我们并没有提,如何求代价函数的偏导,或者说如何对代价函数使用梯度下降。这时候就需要我们的backpropagation出马了。
backpropagaton的历史我就不详谈了(主要是懒),总之呢,现在他已经成了神经网络计算的核心算法了。接下来我们就详细的讲这个算法。
首先我们从基础开始说起,首先定义一个神经网络
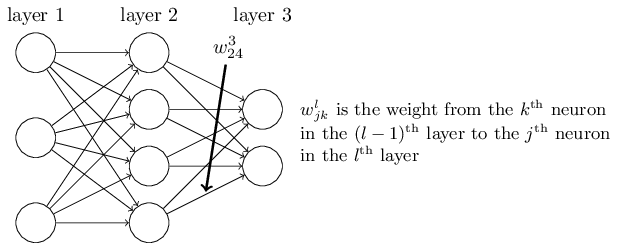
在这里,首先需要理解的就是 wljk 的形式。右上角的 l , 代表的是层数,也就是“输入”(可以是直接输入,也可以是上层的输入)与权重w结合,作用到的下一层。右下角的 k , 是l−1层的第k个神经元;右下角 j 的,是l层的第j个神经元。
这么写看起来好像比较奇怪,因为直觉上说,k在l之前,才是更符合我们认知的理解方式。但是后面我们可以看到,在这种处理方法之后,我们可以得到一种更简洁的处理式子。比较而言,这种前后稍微颠倒下,也无所谓了,适应下就好了。
除了权重w之外,我们还有b和a:
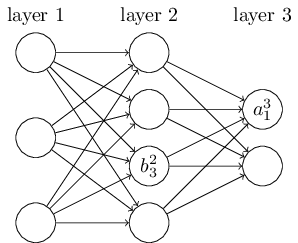
b是我们的偏差,a是我们的输入向量经过激活函数之后的结果,也就是 a=δ(z) .
在表现形式上,b跟a有这类似的特点:
右上角的值是所在的层数;右下角的值,是所在的第几个神经元。
于是,根据前面的一些式子,我们一结合,就可以写出下面的式子:
这个式子看起来好像复杂,但实际上很简单,而且完全描述了我们刚才说的神经网络的问题,当然,这里的 alj 是其中的一个神经元,它位于第l层的第j个。
这个神经元的得来,就是从前一层l-1层的所有神经元,与与之对应的权重结合之后,所有的相加,经过激活函数得来的。
说点题外话,看到相乘,然后求和的情况,你会想到什么呢?如果你能想到矩阵相乘的话,哎吆,不错奥。
在矩阵中,我们要求的某个值,就是行与列对应位置的值相乘之后相加得到的。在本式子中,k就是那个对应的位置。例如,我们有公式
lij=∑Kkmiknkj
这个公式就是典型的矩阵相乘求值的公示,那么我们转成矩阵相乘:
li=minj
在(23)中,可以把 alj 理解成第l行第j列的值,那么我们采用矩阵相乘的方法来计算,就得到了:
al=δ(wlal−1+bl)
这样,就得到了一个比较简洁的式子。而且我们也可以看到之前说的 ,k和l互相颠倒的优点了。
为了更方便,我们设定
这样,我们可以方便的得到 al=σ(zl)
然后呢,为了计算backpropagation,我们需要作出两个假设。
首先,我们知道,代价方程的形式为:
其中, n 是样本数,x 是输入样本点, y(x) 是其理所应当的输出值,而 aL(x) 是我们的神经网络的输出值。其中L是神经网络的层数,在这里就代表了神经网络里的最后一层。
所以,我们作出两个假设:
1) 代价函数可以写成这种形式: C=1n∑xCx,Cx=12||y−aL||2
也就是说,整个的代价函数可以用每个样本的代价就平均来得到。我们知道对于一个样本点来说,x的值是固定的,因此,我们可以暂时把 Cx 中的 x 省略掉,写成C的形式。
2)代价函数C可以写成关于 aL 的函数。其中 aL 是个向量,里面包含多个不同的输出情况。可以写成:
基于两个假设,我们再来介绍backpropagation的四个基本等式:
什么是backpropagation呢?实际上,backpropagation实际上就是理解我们改变权重和偏差会怎样影响代价函数的问题。或者说,实际上就是求 ∂C/∂wljk 和 ∂C/∂blj 的值的过程。为了求他们,我们首先定义各个中间变量 δlj ,我们成为在第l层的第j个神经元的错误值。
backpropagation 将会给出求解 δlj 的过程,然后关联到 ∂C/∂wljk 和 ∂C/∂blj 。

我们假设有一个小精灵在l层的第j个神经元,当有输入的时候,这个小精灵对这个神经元都会做些干扰。他会给激活函数的输入一点小的扰动,比如说增加了 ∇zlj ,那么这个神经元的输出就变成了 δ(zlj+∇zlj) ,这个变化会不断的传导,最终会传导到我们设定的代价函数那里。那么这个对代价函数产生了多大的扰动呢,就是:
也就是说代价函数对这个节点输出的偏导与实际变化大小的乘积。
现在,我们假设我们的小精灵是个好的小精灵,是个想要帮我们的小精灵。加入说代价函数很大,那么由于我们有了扰动函数
小精灵需要做的,就是让这个值为负值就好了。每次都干扰下,让这个扰动为负值,就可以不断的让代价函数较小,直到。。。。直到为0!
那么如何使这个值始终为负呢?很简单,小精灵需要做的,就是每次都取 ∇zlj 与 ∂C∂zlj 相反的符号就行了。
之前我们提到,我们的终极目标,是让小精灵不断的帮忙,直到代价函数为0为止。这个过程借助的是 ∂C∂zlj 。反过来我们想下,如果 ∂C∂zlj 很小,甚至接近为0,这表明什么?这表明了,我们的小精灵可能无能为力,来帮我们很好的调整我们最终的代价函数了。
也就是说, ∂C∂zlj 从某种程度上来说,衡量了这个神经元的错误情况:如果这个值大,也就是代价函数大,那么值得小精灵做的还有很多;如果这个值很小,甚至为0,供小精灵发挥的空间就不多了。
于是,我们设定:
这个代表在第l层第j个神经元的错误情况,于是,我们可以用 δl 来代表第l层所有的错误情况。
有了 δl ,后面backprogation 会给我们讲如何利用他来求解 ∂C/∂wljk 和 ∂C/∂blj 。
当然,有人也会奇怪,为什么小精灵会选择 zlj 作为修改的对象,而不是直接选择输出 alj 呢?实际上,这两者的选择在后面的分析当中都差不多,但是选后者会让代数式变的复杂一些。所以我们选择
作为错误的衡量。
下面我们将四个等式:
证明:
这个函数只有在k=j的时候才是有值的(其他时候不存在这个输入 zLj ,导数为0),因此(37)可以写为:
由于 aLj=σ(zLj) 所以(38)式可以写成:
这是我们的基本式1.
下面还有三个基本式(暂不证明),这四个式子基本就是推理神经网络的基本公式了。
基本式2:
δlj=∂C/∂zlj
δl+1k=∂C/∂zl+1k